建置奈米等级的IC由导线(wire)开始,亦由导线结束。导线主导着奈米设计;若不了解导线,就无法了解设计的速度效能,也无法知道是不是能够将它制造出来。事实上,一个奈米设计的策略必须将注意力集中于如何快速地将导线产生出来、将之最佳化、并予以分析,若使用的设计方法不具备这样的考量,设计团队将无法在适切的时程内完成至为复杂的奈米IC。
导线(wiring)主导奈米设计
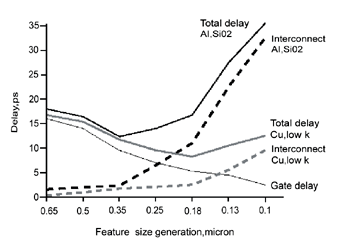
在奈米设计中,导线的延迟(wiring delay)占掉整体延迟中的绝大部分,延迟问题从“闸”转移到导线已有一段时间,而且是众所周知的。如(图一)所示,导线的延迟在0.18微米或更小的铝制程、以及0.13微米或更小的铜制程等节点超越了“闸”的延迟,到了90奈米,导线所贡献的延迟将占去整体延迟约75%。于是,设计团队便须将焦点从逻辑最佳化转移至导线的最佳化(wire optimization)。
延迟特性的改变
除了导线主导整体延迟的问题外,奈米设计也使得一些能够引起相当可观延迟的实体效应更为严重,其中又以信号完整性(signal integrity;SI)以及电压降(IR or voltage drop)最为显著。这些效应在0.18微米的制程即应加以考量,而到了0.13微米,“签核(sign-off)”的时序分析工具也欠缺了对许多SI及电压降等类型衰减的考量,这些衰减的效应与表面的时序效应(nominal timing)相当,却较难预测,然而许多设计团队在对0.13微米的设计中,仍继续使用过于简化的延迟计算模型(如lumped capacitance;凑合电容值)。如此一来,不但降低了速度效能(肇因于高误差),也增加了多余而费时的设计来回(iteration)次数。到了90奈米,一个不考量SI与电压降效应的时序分析基本上是毫无意义的。
交互耦合效应(Cross coupling)
延迟是一个导线负载与驱动的结果。在0.25或更高微米时,主要的导线电容值是来自于与地线之间的偶合关系(coupling),而其大小正比于导线的长度:导线的长度加倍,电容值即加倍。 Steiner绕线-或称总体绕线-的评估能根据布局来预测导线的总长。
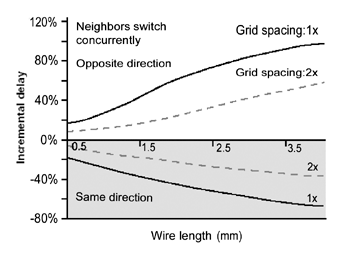
然而由于制程的尺寸越来越小,导线的主要偶合电容转移到与其邻近的其他导线之间。电容值取决于导线本身的形状[1],而在多数的情况下,它亦取决于其邻近导线上的信号变化。以(图二)为例,该图所示为在0.18微米下,因信号线间之电容偶合所产生的延迟变异:实线为一倍格点间隔(grid spacing),虚线为两倍。延迟变异对1毫米的导线可达+/-30%;对3毫米的导线则可达+80%/-60%。
在0.18微米时,交互偶合效应只会对高速的设计有明显的影响。但到了90奈米,交互偶合则会对所有的设计均有显著的影响。而在奈米几何下,既然电容值不再只是单纯地与导线长成正比,为了达到精确的时序分析,则需要先有详细的绕线。
电压降(IR drop)
电源(power)与地线的线路网络中的电阻造成电压降(IR drop)。由于这样的电阻随着制程尺寸的减少而增加,奈米设计因而对这些效应极为敏感。而在整体的电源供给电压降低后,信号变化可用的范围变小,这个效应便更加地严重。在电源供给电压下降后,闸延迟与杂讯影响敏感度(noise susceptibility)增加。由1.7V到1.6V的电压降可产生50%甚或更多的延迟差异。一项针对0.18微米或更小尺寸设计的研究显示,20%的设计在第一轮的矽成品失败,其原因单纯地为电压降。
奈米技术问题
事实上,有一大串在0.13微米及以上即存在的技术问题,在奈米设计中则更加地严重。而一些关于复杂度(complexity)、实体效应(physical effects)、以及可制造性(manufacturability)等等的新问题也应运而生。 (表一)列出一些最具关键性的奈米设计议题。
表一:奈米设计中关键的技术议题
| # |
议题 |
是否与导线相关 |
| 1 |
设计大小与复杂度 |
是,若为阶层式的(hierarchical) |
| 2 |
信号完整性(SI)及流阻(IR)相关的时序 |
是 |
| 3 |
电压降(IR drop,电源供应网〔power grid〕设计) |
是 |
| 4 |
互扰(crosstalk)与电感 |
是 |
| 5 |
电子迁移(Electromigration) |
是 |
| 6 |
数位-类比整合 |
多多少少 |
| 7 |
耗电 |
多多少少 |
| 8 |
系统信号传输 |
是 |
| 9 |
制造规则(Manufacturing rules) |
是 |
| 10 |
良率最佳化 |
是 |
任何一个重要的奈米设计议题的表列都会有一个最显著的特征,那就是有着许多与导线有关的议题。在奈米几何下,导线主导着几乎所有关于IC制作各个方面的问题──包括设计时程、速度效能、占据面积(area)、以及可制造性。
连续性收敛设计方法
由于导线在90奈米制程及以下的节点所扮演的关键角色,传统的线性设计流程因而无法发挥功效。奈米设计需要一个完全不同的设计策略──连续性收敛。
对新设计策略的需求
传统的IC制作方法是线性的,也就是说设计本身循序经过一连串的设计阶段:RTL、逻辑闸、耗电功率规划、布局、时脉树(clock tree)设计、绕线、以及实体分析。当逻辑闸主导设计中的延迟时,因为速度效能的最佳化与分析的来回(iterations)在设计流程的初期进行作业,这样的流程是可预期且有效率的。
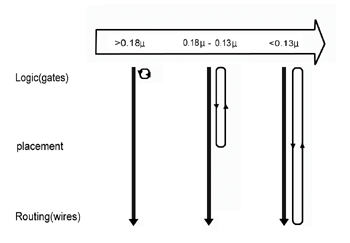
随着导线延迟所占的比例的增加,这样的线性流程变得越来越不可预测而没有效率。在0.18微米,速度效能在布局之前为未知。藉由布局规划与实体合成工具,设计工程师们在布局阶段,经由多次来回的尝试来找出可行的布局方案,见(图三)。若找不到可行的方案,则必须一口气退回到前面,改变设计的架构或逻辑。冗长的尝试可能大幅降低可预测性与工作效率,在90奈米,速度效能在详细的绕线之前皆为未知,也就是说,使用这样的线性流程意味着更多而且更久的尝试-亦即更难以预测、更加地没有效率。
由于在奈米设计中,时序延迟主要以导线为主,设计团队所使用的方法必须既能够要尽快地产出导线(time-to-wire)、又能够要尽量地减少晶片设计消耗的时间。 Time-to-wire与晶片设计来回消耗的两个时间点,将是奈米设计中设计可预测性与效率的关键性度量指标。
布局规划不敷使用
布局规划使用一个全晶片、总体的实体布局拓朴关系(topology)、及估计的实体资料,来产出时序与拥挤度分析的估算。这项资讯必须是精确的才会有意义,而在奈米阶段唯一能够得到精确资讯的方法,是对真实的导线进行分析,包括互扰与电压降等实体效应。若布局规划的资讯并非基于真实的导线,其在奈米阶段的结果,将会是一个不可预测而没有效率的流程,这样的流程只能产出次于最佳化的设计。
实体合成不敷使用
实体合成即逻辑与布局的同时最佳化,相对于传统以线载(wireload)为基础的逻辑合成在0.18微米与0.13微米提供了显著的效益,实体合成以逻辑闸、布局以及曼哈顿(Manhattan)式导线估算为基础;这些并未包含电容耦合效应、金属层,或是详细的绕线效应。然而,由于这些效应对整体的时序延迟都有相当的影响,实体合成基本上缺乏足够的资讯来收敛奈米设计的时序。
虽然早先有实体合成将取代逻辑合成的市场预言,但目前设计团队仍只是将它应用在对无法满足时序要求的闸级区块重作最佳化。在奈米设计中,设计团队亦只会将实体合成应用于全晶片详细绕线阶段所指出对时序要求有落差的区块。届时,实体合成会扮演着一个珍贵的最佳化引擎,对绕线的最佳化提供一个较佳的起始点。然而,导线的本身-而非逻辑或是布局-将独导速度效能。
奈米设计方法:连续性收敛
连续性收敛设计方法可充分减少导线产生的时间(time-to-wire),以及晶片设计来回尝试的时间,有数目越来越多的公司已经在0.13微米采用了连续性收敛,且相较于线性流程有着出色的结果。
虚拟的投片(tape out)
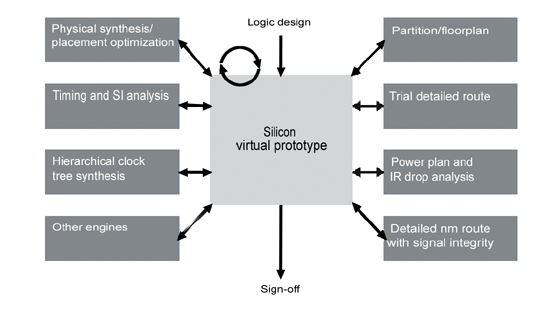
连续性收敛以一个初始的全晶片设计导线模型开始,这个模型称为矽虚拟原型(silicon virtual prototype;SVP)。 SVP会同时并行地考量设计的所有面向-逻辑、时序、信号完整性(SI)、功率降(power drop)、电子迁移(electromigration; EM)、输出入问题以及可制造性。设计团队使用SVP来指出并安排速度效能与制造等问题的优先顺序,尔后个别设计者从最优先的问题次第解决。告一段落时,整个设计团队整合所有的设计变更到SVP里面,再重新分析整个设计。
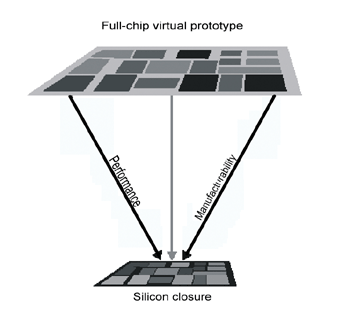
使用连续性收敛的设计团队,通常协调以一天为标准的整合周期,也就是说每天都进行一次虚拟的投片。如此一来,他们每天都可以看到可预测、可测量、朝向其矽收敛目标与最终tapeout的一个有系统的进度,如(图四)。
矽虚拟原型
SVP是连续性收敛设计方法的关键。一个SVP必须是一个具有与tapeout品质够接近的完整全晶片建置,设计工程师们必须要能够正确地评估所有与设计相关面向的问题。然而它同时又必须要能够快速地执行,俾使设计工程师们得以快速地来回尝试不同的建置方向。一个没有详细绕线的原型或许可以导引逻辑设计,却不足以导引奈米的实体设计。
SVP亦必须支援时脉线路(clock)的结构、电源供应网(power grid)、顶层互连线路(top-level interconnect)以及其他tape out设计中所需的特性。它必须要含有所有相关的资讯,以便用来表示一个已知而且实体上可行的解决方案,进而用来导引如时序预算(timing-budget)与pin脚等规划的设计决策──一个完全详细且具有绕线的布局(layout)是保证实际可行的预算与pin脚规划的唯一方法。
| 《图五 SVP可作为设计驾驶舱(design cockpit)来使用》 |
|
一个SVP可以作为所有工具与功能的总体设计驾驶舱(universal cockpit),如(图五),在一个单一的全晶片环境中结合建置与分析等所有面向的议题。这样的环境可以包括建置的功能-平面规划、布局、实体合成、绕线、时脉电路树合成(clock-tree synthesis)以及耗电功率的规划,亦可以包括分析的功能:时序、信号完整性、可绕线性(routability)、以及耗电功率等分析。
阶层式与高容量单一平坦层级(flat)的支援
大部分的奈米设计将会很巨大,事实上目前已有一些超过十亿物件的设计在0.13微米中开发。在90奈米,一千万闸以下的设计将被视为小型设计,大部分的设计团队会打算使用单一平坦层级来开发这样的小型设计。当然设计团队将会需要在大的设计中使用阶层,但即使在这样的案例中,我们仍需要很高的容量来尽量减少所需的阶层级数。
连续性收敛必须要能够支援阶层式与高容量的单一平坦层级的设计,工具的容量在这两种情况中都是关键的因素。用现今的标准来看,奈米工具将需要巨大的容量及很快的速度效能。现时许多IC制作工具有着相当于一百万闸的有效容量;但有些工具的有效容量则少很多,需要在设计里加上一些本来不需存在的层级;这些为了应付工具容量所新增加的层级,可能会造成相当多余的负担(例如增加了做预算及制约的需求),并且降低了整体最佳化的机会。除此之外,风险也增加了,只要有一个时序预算错误,就可能让一个本来行得通的设计做不出来。
显然地,工具不应加诸设计工程师们不必要的限制,所有的奈米工具均要有足够的工作容量及速度效能,来应付具有一千万闸单一平坦层级的设计;相较于现今一般的容量,这是一个相当幅度的增加。这能藉由一些方法来达成,包括改善运算法则、改进资料结构以及使用多个处理器。一个一千万闸的有效容量将能提供设计团队较多的自由来决定何时与如何利用设计层级。
奈米绕线的需求
全晶片细部绕线是评估一个设计的初始速度效能的第一步。它同时也是针对所有的速度效能与制造需求做设计最佳化的最后一步。奈米设计需要新的绕线工具,必须要考量实体因素、制造因素、且要具备有巨大的容量以及很快的速度效能。
具实体考量与制造需求考量的绕线
在0.13微米以上的制程节点时,会需要考量到这些麻烦的实体效应的,只是那些设计极高速产品的设计团队;这些考量亦需要极昂贵的人工作业。到了90奈米,困难的问题更多了许多,若要设计团队用手工来改善这些问题是不切实际的。于是,设计团队将需要能够随时应付实体效应(从信号完整性与电压降开始)的绕线工具来收敛时序。
大部分的设计团队只将注意力放在时序的收敛上,心想其结果应该是可以制造的。在0.13微米以上时,当产生完全绕好的GDSII后,若该GDSII果真不正确,仍能执行如光学近区间修正(optical proximity correction;OPC)的制造程序来进行修正;设计团队确实可以忽略实体制造过程的效应。
大部分的设计团队是在0.13微米第一次碰到其设计是否可制造的问题。使用铜质导线、化学机械研磨(chemical-mechanical polishing;CMP)以及次波长蚀刻(subwavelength lithography)的制程,具有过于复杂甚至于奥秘的设计规则。例如,天线规则(antenna rule)即需要小心地应付以避免在缩短线长的同时产生接点超生(via proliferation)。此外,晶圆专(代)工业者为了要缩短制造时程,在新的制程上市后,仍会持续地改变设计规则。
奈米绕线工具必须明确地支援可变宽度与可变间距(spacing),也必须能够根据铜、多重接点(multiple vias)、OPC、相位位移光罩(phase-shift masking;PSM)以及CMP等做调整及改变。 90奈米以后,绕线工具将必须特别为制程需求做绕线的最佳化,奈米设计对于未特别考量这些先进制程议题的绕线工具,将会是一个难题。
巨大的绕线容量与很快的绕线速度效能
在0.13微米以及以上的,设计团队可以针对一个区块一个区块来进行绕线,接着使用晶片层级的绕线工具将各个区块连接在一起,之后便可以进行如产生顶级时脉树(clock tree)的工作。奈米绕线工具则必须要能够在晶片层级及区块层级同时运作。
这样的绕线工具必须与绝大部分晶片实体化的各项考量因素紧密地结合在一起,并且要能够控制这些因素,包括:
- ˙最佳绕线的布局;
- ˙针对时序修正与面积修复作局部的逻辑最佳化;
- ˙时脉树的建构与平衡,包括有用的时脉歪曲(skew);
- ˙以电压降及EM分析为基础的电源供应网的建构。
奈米绕线工具必须要同时能够取得寄生参数的抽取、全晶片的静态时序分析(static timing analysis;STA)以及信号完整性分析等的结果,并使用这些结果来随时导引及调整绕线。高档的设计团队必须要应付信号、电源以及时脉绕线等之间复杂的互动。例如,在90奈米的高效能设计中,高速时脉绕线必须要以隔离(shielding)、线轨分配(track assignment)以及配置拓朴控制(topology control)等技巧加以严谨的控制。绕线必须与自动时脉树合成、以及时脉时序分析整合在一起。
要完成以上这些,并且支援可变异的线宽与间距,便需要巨大的容量与很快的速度效能。一个有意义的测试标竿(benchmark)是要能够在一个晚上绕出一个一千万闸的设计。要做到如此,即可能需要多程绪(multithreading)与多工处理(multiprocessing),以将所有可以运用的运算资源利用到该项作业上。
奈米实体分析上的需求
每一个制程节点的改变均带来了新的挑战。而在90奈米、铜制程的一并加入则又带来了相较于一般更多、更艰难的问题。这些问题使得要得到正确的分析资讯更加地困难。成功的奈米设计需要在整个设计过程中使用到奈米等级的分析工具。这些工具不但应该要能够指出问题,更应提供建议来解决它们。
所见不同于所得
在奈米层级的布局(layout)所看到的,与在最终矽成品所得到的并不相同,甚至也不会太相似。导线的宽度会因次波长蚀刻的光学扭曲而改变,导线的厚度也会因铜线上的CMP而改变,造成如侵蚀(erosion)与碟化(dishing)的效应。这样的扭曲相当程度地影响了信号导线、时脉以及电源供应网等的电气特性,包括电容值、电阻值、电感值、可靠度以及EM。设计团队需要能够反应这些现实的分析资讯。
若有了正确的分析资讯,设计团队亦能自任何一种制程技术显著地得到更快的速度效能。使用全客制(full-custom)技巧的微处理器设计团队,通常能较使用半客制技巧的ASIC设计团队,在任何一种制程节点达成七倍到十倍快的频率。造成这样差别的因素,有相当的一部分是来自于拥有精确的实体分析资讯,让设计工程师能做大幅的改善,于是他们便能在任何一个制程节点获得速度上的效益,或者选择使用较便宜的制程节点来降低每颗晶片的成本。
寄生参数的撷取
撷取的正确性是绝对必要的,正确性大致上倚赖工具业者与晶圆业者之间的关系。工具业者必须要能够较早地得知关于制程的机密性资讯,以便于决定如何做出最好的制程模型,以及捕捉必要的制程特性。正确性亦取决于设计的表示(representation)。工具需要使用设计元件的实体细节,而非简单的化约特性。例如,虽然提供一个输出入埠的简化模型是很方便没错,可是这样会很自然地限制了设计的最佳化。同样地,元件(cell)模型应该以各个实现后的元件(或译事件:instance)个别处理,而不应将一个元件的所有事件均视为相同的。 [2]
从设计方法的角度来看,要达到对最终矽制程的最佳利用便需要在每一次的设计来回(iteration)中,利用到所需要的最精确实体资讯。在初始的设计来回中,较为重要的是作业完成所需的时间;而到了设计的后期,精确性则最为关键。使用较不精确的撷取工具来加快时程,有可能会增加错误率以及增加时序不能收敛的风险。一个撷取工具应该要让设计工程师能够在一两个小时内,完成一个区块的设计来回(iteration),并且应该要能隔夜完成一个全晶片的撷取,如果需要,得使用多处理器的电脑来运作。
延迟计算
现今的「签核(sign-off)」时序分析工具所作的延迟计算是不精确的。这些工具通常使用一些过于简化的模型(如凑和电容值;lumped capacitance),这些过于简化的模型并未考量到导线上的动态效应,导线上的动态效应最终亦会造成元件延迟上的动态效应。元件延迟除了随着闸的驱动负荷改变以外,亦会随着线路脉络间的耦合效应而改变,于是延迟是动态的,并非固定的。精确地说,延迟计算不能只植基于元件的行为功能化约模型(behavioral abstraction);它还必须加入下至电晶体层级的电流与电容特性等考量。对于高频电路而言,以凑和电容值为基础的元件延迟计算根本不够精确。奈米延迟计算必须基于信号完整性与电压降,如(图六)。
| 《图六 对信号完整性与电压降予以考虑的奈米延迟计算》 |
|
阶层式的延迟计算对奈米设计而言也是重要的。简化的、保守的、在阶层层级边界的时序模型,会增加误差。延迟计算必须正确地模拟跨越阶层层级边界的路径,以维持其精确性。
信号电子迁移(Signal Electromigration)
之前人们相信铜制程会简化所有的电子迁移(Electromigration;EM)议题[3],然而现在发现事实可能恰好相反。铝的「竹状」结构对EM的抗衡会随着导线越窄而增加,而铜并不会。除此之外,钨材质的接点(via)可将可能发生的EM效应限制在线路脉络的区段内,而在铜制程中所使用的铜接点则会将EM效应扩散到整个线路网络。
由于导线越来越小,而设计工程师为了达成速度效能上的需求,被迫将更多的电流灌入这些狭小的导线,于是信号的EM(电子迁移)便渐渐成为一个问题。配置与绕线的工具为了满足对时序的需求,对线路产生大型驱动电路,这却在巨大的晶片中制造出许多EM的问题,这些问题连设计工程团队都不晓得。奈米实体分析必须在EM问题在最终矽成品中出现前便将它们指出来,包括由于高频交流信号(AC)所感引出来的EM(广泛包含超过300 MHz的信号与带有许多危险的信号)以及由于高单向直流电流(DC)所造成的EM。
电源供应网(Power Grid)的分析
电源供应网大约占掉所有导线的三分之二。在奈米设计中,他们将包括超过十亿个导线区段(wire segments)-电阻。相对于一般对信号线一次处理一个信号,电源供应网必须作整体的分析与考量,这也使得工具的处理容量显得重要,并且必须要能够支援多重层级。电源供应网的分析必须要包含电压降以及EM的分析。若使用过于简化的模型抄捷径来加快电压降的分析,其代价可能会相当昂贵,因为最终的矽成品可能会因EM而失败。
对电源供应网的精确分析需要对设计行为(design activity)做模型,做出来的模型必须要能够代表实际的信号变化。要为许多复杂的设计提供适当的测试向量已是难上加难,电源供应网的分析工具应该要能够使用一些以或然率为基础的技巧,这些技巧能为越来越多的设计,提供使用静态及以测试向量为基础的方法所无法提供的精确度。为了要达到精确度,电源供应网的分析工具必须也要考量制造方面的技巧如OPC与PSM,以帮助对晶圆专工矽模型持续进行中的校正(model calibration)。
电感
SI下一个大问题是电感,业界现在有对很小型电路的特殊解决方案,这类的解决方案着重在撷取(extraction)。虽然有些业者已开始针对大型设计推出特殊功能,完整的解决方案在短期内却不太可能出现。撷取与分析电感问题中一个主要的挑战,在于其计算成本超乎寻常地昂贵,可能会需要比能对交互耦合效应做最详尽分析的工具,还要多上许多倍的计算成本。连续性收敛能帮设计团队指出最可能会有电感问题的导线,这样他们就能好好地利用如此耗费计算资源的工具了。
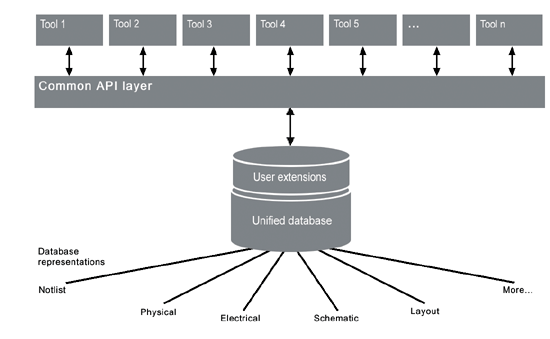
奈米设计对资料库的需求
因为有巨大、复杂、精密繁复的实体需求、艰涩的制造需求,以及其他一切仍属于未知的因素等,一个「对」的资料库在奈米设计中较以前来得更为重要了。由于大部分的奈米设计将会是数位/混合信号IC(例如带有关键类比线路的大型数位设计),于是要让奈米设计的资料库能够支援一个统一的资料模型便显得格外地重要。
在1980年代早期,要把几何资料以及其所属的线路连接资料结合在一个单一的资料库的想法,仍是属于新颖的观念,当时对这样的观念有许多的讨论与质疑;然而若将这个观念付诸实行,将同时能够实现一些我们最特出的运算法则的跃进,包括以线路连结为基础的编辑、配置与绕线、实体合成,以及有效的实体验证。现在的这个时间点正是实现下一代统一的资料库的时候。
统一的资料模型
奈米设计需要统一的资料模型,即以一个单一的设计表示(representation),足以包含设计所有面向的资讯:包括线路图(schematic)、线路列(netlist)以及布局等表示;此外还有数位与类比表示,以及元件组合(cell-based)与客制(custom)的表示。这个表示也要能够支援所有与这些设计表示相关的资讯,包括实体布局、逻辑与实体线路连结、撷取与化约的寄生资讯(extracted and reduced parasitics)、时序制约(timing constraints),以及详细的制造资料,如OPC与PSM。
一个统一的资料库能使所有的设计工具运作在一个共同的表示之下,免去耗时与易错的档案转换。每一个应用程式得以使用资料库中与其相关的部分,若要增加新的资料型态,则只需改变使用到新资料型态的应用程式即可。以现今的交换格式而言,每一个应用程式都需要去解读、储存以及输出表示格式中所包含的所有的资讯,如此常常会造成资讯的遗失。一个统一的资料库消除了这种当每一个工具程式读取、解译、转换及写出资料时资讯遗失的尴尬。
一个统一的资料库允许新的运算法则(algorithm),使用目前只有一些特定工具能够接触到的设计意向(design intent);例如,一个产出OPC的工具可以在选择修正(correction)之前先检验每一个讯号上的余裕(slack),进而降低光罩的复杂度及成本。其他如智慧型混合信号设计分割(intelligent mixed-signal design partitioning)、模拟以及分析等,都是很好的例子。
关键功能
一个奈米资料库必须能够支援奈米物理与制造阶段所需的先进资料型态(constructs),如整区填充(area fill)、槽线(wire slotting)、OPC及PSM。例如,对OPC与PSM资料型态具体的支援,意味着一个设计档案除了能够包含OPC前/PSM前的布局之外,亦能够包含关于OPC/PSM改变的资讯。设计团队便能够将原来的布局更轻易地转移到新的制程。具体的制约支援(constraint support)则确保得以与设计表示同步,避免使用不正确的制约档。奈米设计将包含许多不同型态的电路,包括数位逻辑、类比、RF、记忆体以及可程式化的逻辑。为了要最佳化速度效能与可制造性(manufacturability),资料库应该要对同一个设计能够支援到数套的设计规则(design rules)。
巨大的资料库容量以及强大的速度效能
奈米资料库应该要能够提供较其前一个世代的实体设计资料库,在容量上十倍的改良,并且不能因而牺牲速度上的效能。事实上,像是读取与写出这类动作的速度,必须要能够明显地提升,对知名处理器与作业系统、32位元与64位元版本跨平台式(transparent)的支援也是重要的。大部分的设计工程师比较喜欢用32位元的机器,而跨平台的支援让他们能够在记忆体范围内使用设计表示。设计工程师若需要使用到超过4GB限制的应用程式应该可以自行达成,不需要将整个设计团队通通换到64位元的机器上作业。
资料库的高速度效能能够让许多工具脱离资料库来自行执行,省去应用程式的开发时间。有些工具仍会为执行效率而使用它内部自订的资料结构,但永久性的储存库会一直是中心的资料库。若资料库能够同时有一个适当的扩充模型,就会有越来越少的应用程式重复已经存在于资料库中的资料结构(如线路列)。
扩充性与开放性
要预测所有的未来设计资讯需求是不可能的,所以奈米资料库应该要能够支援对物件型态的新增、对已存在的物件新增属性,以及定义物件间新的关系等功能-而这些功能均须以原机(native)的速度与效率运作。这些扩充必须要是轻量级(lightweight)、能够有效率地使用空间及时间,并能最佳化特定的资料型态。
若具有适当的扩充性,应用程式开发工程师──包括公司内部以及协力厂商(third party)的工具开发业者,便能够写出有效率的运算法则,确切地在全速下操作与分析所需的资料。扩充功能应该要能够永久地存在以便让其他的工具使用;也应该要能够暂时地存在以便作为整合的高速快取模组(cache)使用。驻在记忆体中的一贯性(in-memory coherence)让下列三者成为可能:将合作的模组整合成一个工具,这些模组在本质上是渐进(incremental)的;使用懒人评估技巧(lazy evaluation technique);以及提供应用层级的工具组(toolkits),用以快速地开发与演进新的工具。
奈米资料库应该是开放的,意即要有一个开放式的应用程式介面(application programming interface;API)、开放式的原始码,以及一个业界社群成员组成的监督委员会。开放性在本质上并非一个技术性的需求,但却能直接地促成一个在技术上优越并快速演进的施行方案。开放性亦能够藉由启动原始的外部与内部应用程式的开发,来减轻设计团队的风险。
未来──与制造阶段接轨
奈米资料库应该要能支援与制造阶段直接、于资料库层级的互动,好让「无GDSII(GDSII-less)」的移交(handoff)成为可能,并同时提供GDSII所无法表示的重要设计原意(design intent)。光罩业者能利用设计原意来降低如整区填充(area fill)这种非电性活跃部分的容忍度(tolerance),以便降低光罩生产的时间以及成本。晶圆专工业者能使用设计原意以特定的设计特性来最佳化其制程,进行更有功效与效率的测试与分析,并且最佳化良率。晶圆专工业者能提供对应到任何设计表示的制造回馈,可能的话,甚至能够将其越来越复杂的设计规则整包装(encapsulate)到资料库里。
结语
在90奈米及以下的IC设计,导线主导速度效能与可制造性,这使得传统的线性流程不敷使用。导线是如此地重要以致于缺乏详细绕线资讯的速度效能分析与最佳化失去实质上的意义。
成功的奈米实体IC设计必须要以导线为主体策略,例如本文所描述的连续性收敛设计方法。这是一个已经过实证的方法,它缩短了导线实体化的时程(time-to-wires)以及全晶片反覆来回(iteration)的时间。使用连续性收敛的设计团队看到可预期、可测量、朝向其矽完成与最终光罩完成目标的一个系统化的进度。
奈米的成功亦须要一套新的施行方案、分析,以及资料库技术。奈米绕线工具必须要能够了解物理特性,要能够在执行时即考量如SI的实体效应。奈米绕线工具亦必须要能够了解制造阶段的需求,具备如可变异区间(variable-spacing)与可变异宽度(variable-width)绕线等功能,以便支援铜、CMP、以及次波长(subwavelength )等制程。奈米实体分析必须要能够精确地代表其标的矽实体。矽完整性与电压降已是直接影响时序的因素了,而EM除了对电源供应网是个问题之外,对信号亦然。一个可扩充、统一的资料库可提供奈米设计的基础,特别由于大部分的设计将会是数位/混合信号的设计。它需要能够支援对物件、属性以及关系等一组丰富的集合。而或许更为重要的,是它必须支援具有原机速度效能的可扩充性。资料库与所有的奈米工具应该要能够轻松地支援多重层级并能有效地处理千万闸的设计。
奈米设计的实体化对设计团队而言要求极高。如连续性收敛这种拥抱以导线为主轴的设计策略将会而胜出,而反之者将付出代价。
<(作者Lavi Lev为 Cadence IC解决方案执行副总与总经理、Ping Chao为Cadence数位IC解决方案资深副总与总经理、Steve Teig为 Cadence IC解决方案资深副总与首席科学家)
注释:
[1] Wire,或称信号节点(node),意指在一个IC设计中的一个单一信号节点,信号节点与信号节点间由逻辑闸或其他类比元件区隔,在布局后该信号节点使用单一连续材质,而其形状可能是任意形状-不一定是线型。
[2]译注:通过导线的电流密度过大且通过的时间过长,造成金属材质的分解,导致线路的断路或者短路。
※本文因限于篇幅而在编辑时稍做文字删修,未来将完整刊载全文于本刊网站:http://www.hope.com.tw/ct ;敬请届时上网参考! >