
介绍:即时机器学习推论
机器学习是支撑新型服务的技术,透过使用自然语音互动与影像辨识提供无缝社群媒体或客服中心体验。此外,它能够在与大量变数相关的巨量资料中辨识出模式或异常,因此经训练的深度学习神经网路也将透过数位分身(digital twin)与预测性维护等服务,转变我们进行科学研究、财务规划、智慧城市营运、工业机器人编程和执行数位业务转型的方式。
无论经训练的网路是部署在云端还是在网路边缘的嵌入式系统内进行推论,大多数使用者都期望能够达到确定性的传输量和低延迟。然而,想在可行的尺寸和电源限制下同时达到这两个要求,需在系统的核心架构高效且大规模的平行运算引擎,以有效率地传输资料,而这需要弹性的记忆体阶层和灵活应变的高频宽互连等功能。
一般用于训练神经网路且以GPU进行运算的引擎运算周期皆相当耗时,且会产生teraFLOPS运算次数,其固定式的互连结构和记忆体阶层难以满足即时推论的要求,与上述的需求成为对比。由于资料重复、快取遗失和阻塞(blocking)等问题时常发生,因此,为达到可满足需求的推论效能,需要一款更加灵活且具可扩展性的架构。
专案善用FPGA的可配置性
现场可编程逻辑闸阵列(FPGA)整合了最佳化的运算砖(compute tile)、分散式区域记忆体和自行调适、无阻塞的共用互连(shared interconnect),能克服传统的限制并确保确定性的传输量和低延迟。随着对机器学习作业负载的需求变得越来越严苛,像微软「Project BrainWave」这类先进的机器学习专案已采用FPGA执行即时运算,可达到GPU无法企及的成本效益和极低延迟。
全球运算服务供应商阿里云的先进机器学习专案也选择FPGA作为其运算基础,为影像辨识和分析建构深度学习处理器(DLP);该公司的基础设施服务事业群认为,FPGA让DLP具备GPU无法达到的低延迟和高效能。图一所示为该团队使用ResNet-18深度残差网路进行分析所得的结果,显示采用FPGA的DLP能达到低至0.174秒的延迟,比同水准的GPU速度快86%,而以每秒查询率(QPS)测量的传输量则提升7倍以上。
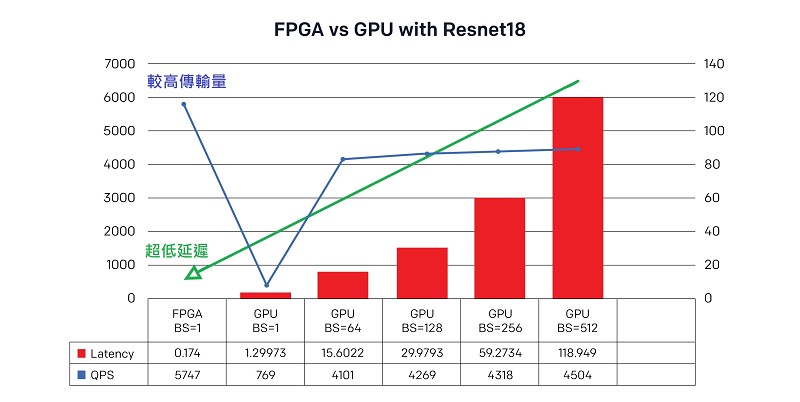
|
微软的「BrainWave」和阿里巴巴的DLP等专案皆成功建构出能加速AI作业负载的新型硬体架构。然而,这只是落实机器学习加速的开端,最终它将被云端服务、工业与汽车产业的客户广为应用;其中,工业与汽车产业对网路边缘嵌入式系统部署机器学习推论有更频繁的需求。
另一方面,部分的服务供应商热衷于将机器学习融入到现有系统中,以强化和加速既有的使用案例。例如在网路安全方面,机器学习能强化模式辨识,驱动恶意软体和危险异常的高速侦测。其他案例包括将机器学习应用于脸部辨识或干扰侦测,协助智慧城市更顺畅地运作。
为非FPGA专家打造的AI加速
赛灵思已建立起具备丰富资源的产业生态系,让使用者能充分发挥FPGA的潜力,以加速云端或边缘AI的作业负载。
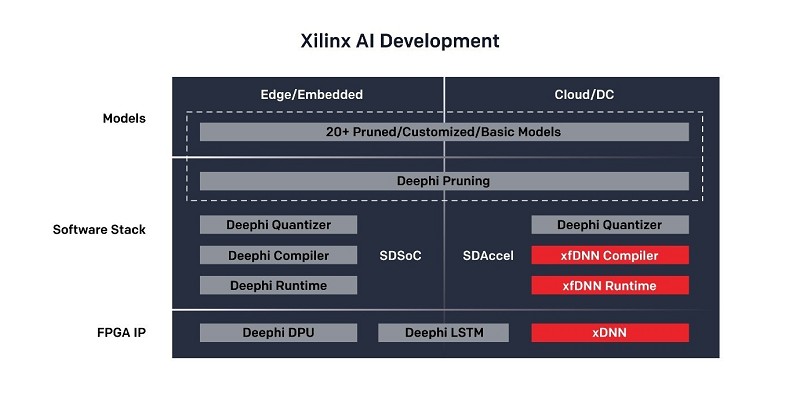
在可用的工具中,ML套件(图二)负责编译神经网路,以便在赛灵思FPGA硬体中运作。它能与TensorFlow、Caffe、MxNet等常见的机器学习框架所生成的神经网路共同运作,而Python API可简化与ML套件的互动。

|
因为机器学习框架常常生成采用32位元浮点运算的神经网路,因此包含量化器工具的ML套件能将其转换成定点等效网路,更适合在FPGA中运作。该量化器是整套中介软体、编译与优化工具及运转时间的一部分,整体称为「xfDNN」,它能确保神经网路在FPGA晶片上发挥最佳效能。
在赛灵思收购深鉴科技(DeePhi Technology)后,其剪枝技术也被纳入赛灵思的产业生态系中,用于删除近零权重(near-zero weights)、压缩和简化网路层。深鉴科技的剪枝技术能在不影响整体效能和精度的情况下,将神经网路速度提升10倍并显著降低系统功耗。
在部署转换后的神经网路时,ML套件提供xDNN客制处理器叠加,让设计人员从复杂的FPGA设计工作中抽身,且有效率地运用晶载资源。每个叠加一般都有配套自己的优化指令集,用于运作各类型神经网路,使用者可透过RESTful API与神经网路进行互动,同时让自己在偏好的环境中工作。
对于在地(on-premise)部署,赛灵思Alveo?加速器卡能克服硬体开发的挑战,并简化将机器学习纳入资料中心现有应用的作业流程。
该产业生态系支援将机器学习部署到嵌入式或边缘实例时,不仅运用深鉴科技所提供的剪枝技术,还有其提供的量化器、编译器和运转时间,为资源受限的嵌入式硬体创建高效能、高效率的神经网路(图三)。 Zynq? UltraScale? 9卡和Zynq 7020模组系统等一站式硬体(turnkey hardware)可简化硬体开发流程并加速软体整合。
|
此外,有些创新型独立软体厂商已经建构出能部署在FPGA上的CNN推论叠加。
Mipsology开发的Zebra是一种能够轻松代替CPU或GPU的CNN推论加速器。它支援多种标准网路(如Resnet50、InceptionV3、Caffenet)和客制框架,并能在极低延迟下达到优异的传输量,例如在Resnet50达到每秒3,700个影像。
Omnitek DPU是另一个推论叠加的案例,能在FPGA上运作具有极高效能的CNN。例如,在GoogLeNet Inception-v1 CNN上,Omnitek DPU使用8位元整数处理执行224×224的影像推论,在赛灵思Alveo资料中心加速器卡上能完成每秒超过5,300次的推论。
可重配置运算满足未来灵活性的要求
开发者在部署机器学习时,除了面临需确保达到推论效能要求的挑战外,还必须牢记机器学习和人工智慧的整体技术环境正快速变化。今日业界一流的神经网路可能很快会被更新颖、更快速的网路所取代,但原有的硬体架构可能无法良好地支援新网路。
目前,商用机器学习的应用往往集中于影像处理及物体或特征辨识,这类应用透过卷积神经网路就能处理得很好。随着开发者将机器学习功能用于加速字串排序或无关联资料的分析等任务,未来这种情况可能会改变,因为使用其他类型的神经网路能够更有效地处理该类型的作业负载,例如随机森林(Random Forest)网路或长短期记忆(LSTM)网路。若要藉由更新硬体来处理不同类型的神经网路,就必须确保低延迟下的快速运算,然而这可能要数月或数年时间才能做到。
若使用GPU或固定架构的客制ASIC建构推论引擎,就无法轻松或快速地更新硬体。 AI目前的发展速度已超越晶片的发展速度,因此在开发之初处于业界一流水准的客制ASIC也可能在即将部署之际成为过时元件。
相反地,FPGA的可重配置性和优异的资源客制灵活性是让元件跟上AI发展速度的关键优势。我们已知道FPGA适用于无监督学习的低延迟集群,而无监督学习是AI的新兴分支,特别适用于统计分析等任务。
使用ML套件这类的工具来优化和编译网路进行FPGA部署,能让开发者在不具备指导编译器决策所需的FPGA专业技术之情况下,也能在自己的环境中进行高层级作业,同时还能在未来灵活地重新配置硬体,支援未来数代的神经网路。
结论
FPGA以能提供机器学习从业者所需的效能加速和未来的灵活性而闻名。它不仅能建构高效能、高效率且可立即部署的推论引擎,还能适应机器学习领域技术和市场需求的快速变化。难题在于既要让机器学习专家充分地发挥FPGA的架构优势,同时又要建构能达到最佳效能、最高效率的设计,因此赛灵思产业生态系将业界一流的FPGA工具与便于使用的API相结合,让开发者无需深入理解FPGA设计,就能充分发挥FPGA晶片的优势。
(本文作者Daniel Eaton为赛灵思策略行销发展资深经理)
PIC32-BZ6:新一代高度整合单晶片无线平台
随着智慧设备的射频(RF)设计复杂性日益增加,传统无线解决方案通常需要多晶片组合才能新增功能,或频繁重新设计才能满足不断升级的行业标准。为此,Microchip推出全新高度整...
随着智慧设备的射频(RF)设计复杂性日益增加,传统无线解决方案...