本文介绍如何使用NanoEdge AI Studio快速部署AI应用。
本应用的目的是透过马达控制板的电流讯号,侦测风扇滤网的堵塞百分比。当风扇堵塞时,马达电流讯号波型将有所不同,但利用传统演算法侦测差异并不容易。因此,机器学习演算法便成为解决这个问题的绝隹选择。
此范例可应用於空调滤网和吸尘器滤网堵塞侦测等类似情况,也可延伸应用於电动马达的其他异常侦测。
硬体与软体前置准备
P-NUCLEO-IHM03马达控制套件用於驱动风扇,由NUCLEO-G431RB主板、马达控制扩充板与无刷马达所组成。
NanoEdge AI Studio则用於自动产生机器学习函式库,并且整合至由STM32 Motor Control Workbench所产生的马达控制软体中。
利用NanoEdge AI Studio 寻找最隹AI函式库
建立新专案
在主视窗中选择「Anomaly Detection」,并建立新专案。
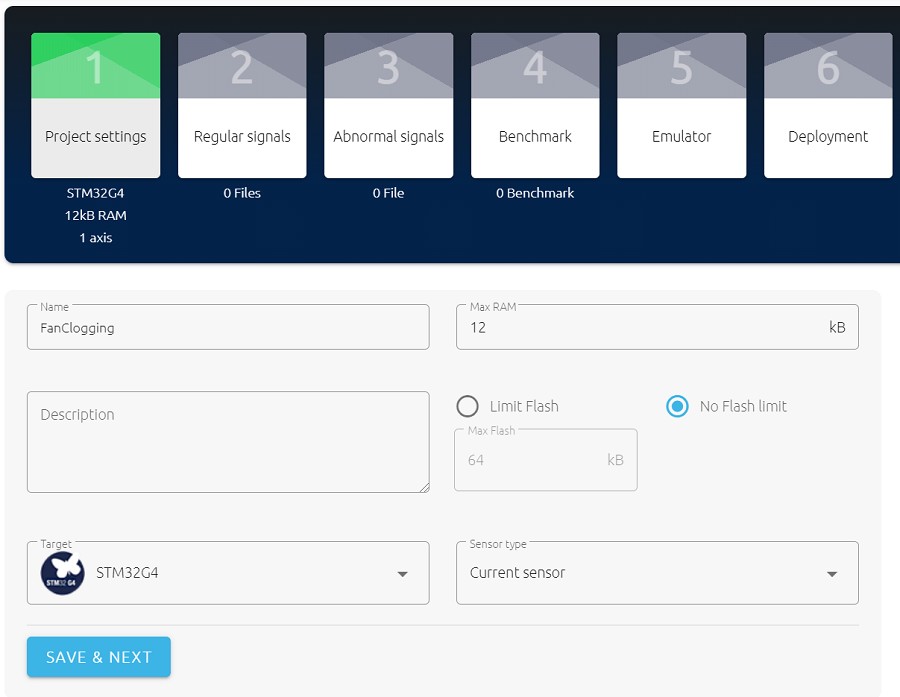
在「Project Settings」步骤中,需进行以下设定:
- Name:专案名称
- Max RAM:使用者希??为AI函式库配置之最大的RAM空间。Studio仅会在「Benchmark」步骤当中,利用这项硬体资源限制来搜寻AI函式库。
- Max Flash:使用者希??为AI函式库配置之最大 Flash 空间,与最大RAM相似。此选项仅会在选择「Limit Flash」时启用。
- Target:此专案的目标MCU或开发板。使用者可选择STM32 MCU 、ISPU或STM32 MCU任一所对应的开发板。
- Sensor type:用於资料收集的感测器类型。此处采用的是内建於马达控制板的电流感测器。
汇入讯号档案
在接下来的两个步骤(步骤 2 与步骤 3),需要汇入两个讯号档案,Studio将会提供格式说明,如图五所示:
- 「Regular signals」 档案对应的是风扇在正常运作下的行为,这些资料是在风扇滤网未堵塞时(如图六所示)收集而得。
- 「Abnormal signals」档案对应的是风扇异常的行为,这些资料是在风扇滤网完全堵塞时(如图七所示)收集而得。
函式库基准测试
在步骤 4 中,我们将启动函式库的「Benchmark」并进行监测。NanoEdge AI Studio会依据步骤 2 和步骤 3 所得之讯号,搜寻最隹且可用的AI函式库。
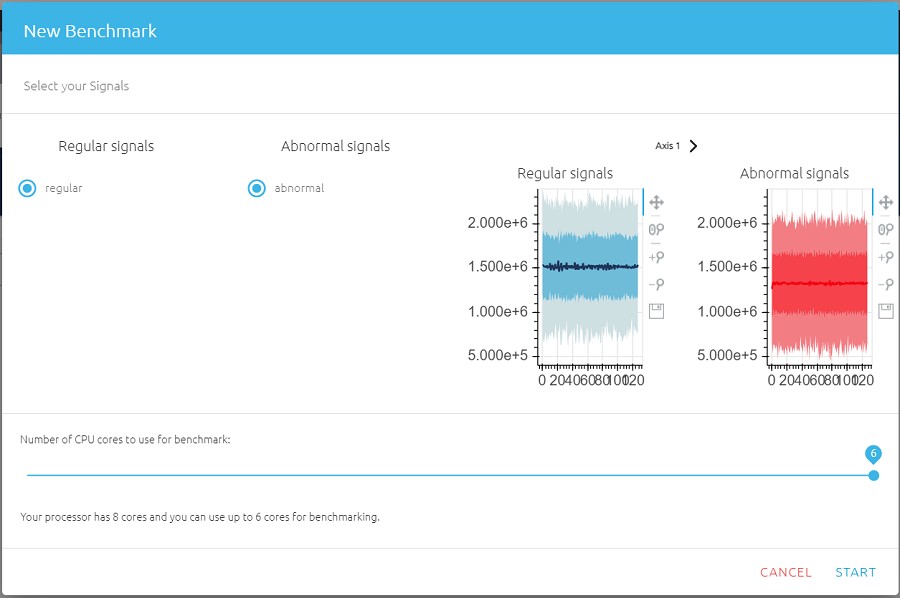
首先,执行新的「Benchmark」基准测试,如图八所示:
然後,选择正常讯号和异常讯号,以及电脑在进行基准验证时所使用的微处理器核心数量。
启动「Benchmark」後便能即时监测候选AI函式库的效能和以下效能指标的变化:
- 「Balanced accuracy」表示正确分类的数量与输入样本总数的比例。这是机器学习中最常用的评估指标之一。
- 「Confidence」 表示对结果的信心程度。正确分类的正样本和负样本之间的差距越大,信赖度就越高。
- 「RAM 」表示候选AI函式库所需之RAM的大小。
- 「Flash」表示候选AI函式库所需的 Flash 大小。
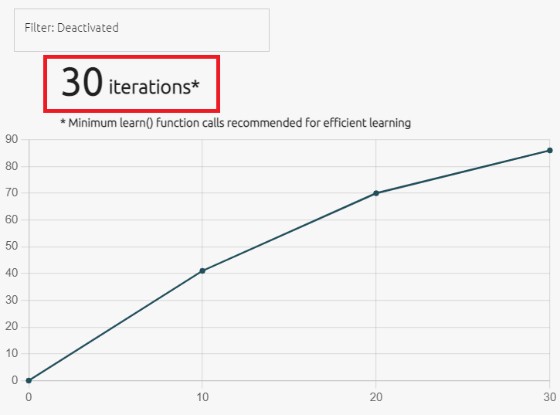
基准验证完成後,会出现摘要画面。这表示当AI函式库内嵌至最终的硬体应用时,为取得最隹效能所需的最低学习次数。在此特定范例中,NanoEdge AI Studio建议应在侦测阶段前,至少呼叫 learn() 函数 30 次来学习 30 个正常运作的讯号。
透过模拟验证函式库
NanoEdge AI Studio也提供模拟器,无需撰写任何嵌入式软体便可协助使用者测试和验证在「Benchmark」过程中所选取的AI函式库,。
依照上一步骤建议,让AI函式库学习最低次数的正常讯号後,再执行侦测,藉以测试AI函式库的行为是否符合预期。
如图十二范例所示,100个讯号已学习完成,而即时讯号和先前学习之正常讯号相似度为 35%,这代表风扇有部分堵塞。
函式库部署与整合
当选取的AI函式库经过验证後,就可以进入最後一个步骤:「Deployment」,其中可针对AI函式库进行编译、下载及为用於嵌入式软体做准备。
在编译函式库前,有数个编译选择可供使用。在此范例中需勾选「Float-abi」选项,才能支援浮点数资料作业。然後,按一下「COMPILE LIBRARY」即可下载NanoEdge AI函式库。
一个.zip压缩档案将会下载至电脑,其中包含了所有的相关文件、NanoEdge AI模拟器、静态 AI函式库和函式库的标头档。此静态函式库可轻松整合至嵌入式软体。
最後,在NanoEdge AI Studio的协助下,无需具备任何 AI 专业知识,只需几个简单步骤,就能快速部署 AI 应用。