人們對資訊運算與資訊傳輸頻寬的需求似乎從未滿足過,1992年Intel提出了PCI匯流排,在32-bit、33MHz時可達132MB/Sec的高傳輸率,就當年而言可謂是驚為天人的規格,但時至今日PCI的傳輸頻寬已成為許多資訊發展的瓶頸,為了尋求頻寬的突破,這陣子資訊組件廠商又開始了新一波的介面/匯流排制訂風潮,因此許多嶄新或強化的名詞紛紛出現,以下我們便就數個最常見的名詞做解釋與說明。
HyperTransport
HyperTransport在2001年2月之前的舊稱為LDT(Lightning Data Transport),主要是針對AMD自家的下一代處理晶片:Hammer/K8所提出,此種介面僅用於高速晶片與高速晶片間,且只在同一張電路板上使用,沒有排線或插槽形式,AMD將此匯流排用於多CPU間的資料溝通,以及CPU對記憶體、I/O間的溝通。
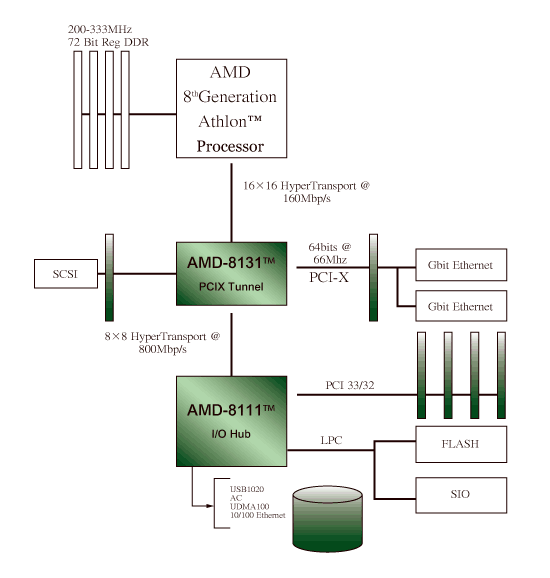
| 《圖一 AMD-8131 HyperTransport PCI-X tunnel》 |
|
在AMD提出HyperTransport前,Intel已經察覺PCI漸漸成為系統傳輸瓶頸,特別是UltraATA/66出現後,兩個UltraATA/66便需要133MB/Sec的頻寬,對於32-bit、33MHz的PCI而言已經是滿載,為此Intel於82810晶片組加入了新推出的Hub-Link匯流排,以此舒緩PCI的瓶頸問題。
Hub-Link雖解決問題,但僅專屬於Intel,不似PCI屬開放規格,而AMD同樣也面臨PCI瓶頸問題,因此只好自行提出HyperTransport來因應(2000年5月提出LDT 1.0版)。
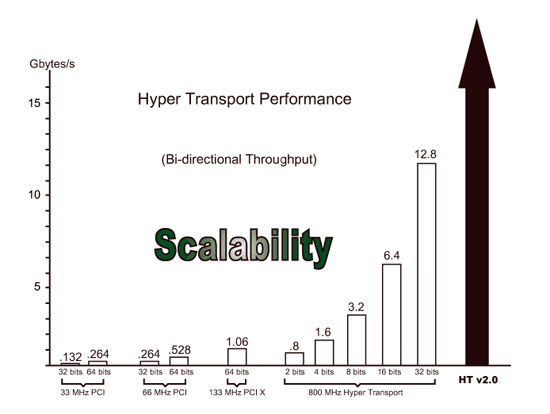
由技術上來看,HyperTransport採彈性、機動調度資料寬度(2-bit至32-bit),以及差動式信號與封包(Pocket)式傳輸,目前最高傳輸時脈為400MHz(上下觸發緣皆運用,相當於800MHz)、傳輸速可達6.4GB/Sec(32-bit時,寬度減半傳輸率亦減半,16-bit則只有3.2GB/Sec),比InfiniBand(後述)的4GB/Sec還快。
HyperTransport雖為AMD所提出,但AMD卻願意授權給其他業者使用,目前已知獲得授權的業者如下:
3GIO
3GIO是「3rd Generation I/O」的意思,與AMD HyperTransport所使用的技術相當類似,都是可調變資料寬度的差動式封包傳輸,同樣也是串列式傳輸,但比HyperTransport優異的一點在於3GIO不僅提供高速晶片間的溝通管理,同時也可以是I/O形式的插槽,與現今的PCI相當類似,且由於3GIO在軟體操控方面直接運用現有PCI的運作方式,因此3GIO也被人稱為Serial PCI,或PCI 3.0版。
3GIO提出的用意即在於全面取代PCI,不過PCI的普及性既廣且久遠,且3GIO規格藍圖雖宏遠但實現技術仍待成熟,所以將採漸進方式取代PCI,短時間兩種匯流排與插槽將會並存於同一主機板上。
3GIO之所以採串列傳輸,主要也是並列傳輸已經發展至瓶頸,未來的突破性也不看好之故,而3GIO則是以串列方式壓榨傳輸介質的物理極限,根據推估,以現有銅質導線來做為3GIO的傳輸,最高可達物理極限的10Gbps,未來甚至可以在不改變協定上的規格,僅將傳輸材質變更,由銅線改成光纖,則有進一步推出傳輸力的可能。
不過10Gbps是遠大的夢想,初期務實的設計僅有10Gbps的1/4速度,為2.5Gbps左右,而這指的是單一傳輸線時,3GIO採可變資料寬度的設計,傳輸可為1-bit、2-bit、4-bit...最高達32-bit,若以單一bit之2.5Gbps來計算,最高速度可達2.5Gbps x 32 = 80Gbps,未來若真達到10Gbps一個bit,則更可達320Gbps。
3GIO另一特點是改善以往PCI的頻寬管理問題,以往經常會有爭搶匯流排主導權的仲裁問題,仲裁經常導致傳輸效能折損,這點於3GIO有新機制負責改善,使3GIO上的任何封包資料傳輸都能即時送達目的地(晶片或介面卡)。為了讓3GIO的普及效應如同1992年PCI般的成功,所以3GIO初期的制訂會員已將後期的制訂權交由PCI SIG負責。
最後3GIO的支援廠商相當眾多,除PC四大廠與Wintel外,其餘成員詳列如下:
Serial ATA
Serial ATA顧名思義是串列傳輸式的ATA介面,目前以16-bit資料寬度傳輸的IDE/ATA介面已經到了傳輸極限,UltraATA/33與UltraATA/66間有100%的傳輸力成長,UltraATA/66與UltraATA/100間卻只有50%的成長,而UltraATA/100與UltraATA/133更是只有33%的成長,並列傳輸已經到了瓶頸,唯一的突破方式即是改採串列傳輸,事實上現今的高速介面皆採用串列傳輸,ATA僅是從善如流而已,其優勢請參考(圖三)。
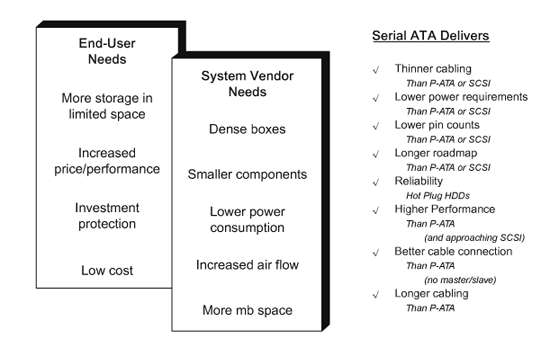
| 《圖三 Serial ATA Value Proposition》 |
|
根據Intel的規劃,Serial ATA初期的資料傳輸率為1.5Gbps(約187.5MB/Sec),已比現有133MB/Sec的UltraATA/133快,而這只是1X的Serial ATA(也稱為Ultra SATA/1500),依據研發排程後續將有2X與4X傳輸速的Serial ATA,即是3Gbps、6Gbps的Serial ATA出現,不過依據Intel內部的工程師看法,一般串列線路可能會在4.5Gbps時即發生傳輸瓶頸,因此6Gbps可能有更換傳輸材質的需要,這點與1394頗雷同,目前IEEE 1394a達400Mbps,要達800Mbps、1.6Gbps、或3.2Gbps的更高傳輸速,必須用光纖作為傳輸介質,若認為光纖太昂貴,至少必須用價格較低廉的塑膠光纖替代,才有突破的可能。
傳統並列式ATA除了傳輸速率難再提升外,40pin的寬排線也經常阻礙機殼內的散熱空氣流通,因此用4pin的Serial ATA亦有減少機殼內線路紊亂,以及讓空間更流通的好處。
Serial ATA從連接的角度看也與傳統並列式ATA不同,以往ATA是以兩個Channel分別連接兩條40pin排線,並於排線上串接兩個支援ATA介面的儲存裝置,如硬碟、光碟機等等,而Serial ATA將沒有這種串接動作,因此可能直接於主機板上提供4組「一對一」連接的串接介面,甚至更多組。
Serial ATA初期的規格設計僅是用來取代傳統並列式ATA,持續提升個人電腦的磁碟傳輸通道的效能,所以並沒有將「熱插拔」的功能特性規劃進去,畢竟是機殼內的介面,與USB、1394等外接介面有應用取向上的差異,不過由於以前Device Bay規格是以1394介面機殼內使用的方式來實現電腦碟機熱插拔,在未來1394也不可能比Serial ATA普及的預測下,Serial ATA也於新版規格中加入熱插拔功能,因應電腦組裝、擴充、升級上的方便需求。
目前除了Intel外,Seagate也率先加入Serial ATA的制訂與開發嘗試,未來在新舊ATA介面皆有的過渡時期,將提供同時具備新舊ATA介面的硬碟,未來則逐漸換成僅具Serial ATA介面的硬碟,除此之外相關的參與廠商還有AMD、APT Tech、Dell、Promise、IBM、LSI Logic、Maxtor等。最後研發進度上Intel已於2002年IDF正式宣佈Serial ATA 1.0版,且相關廠商成員也已經進入Serial ATA II的制訂規劃。
iSCSI(internet SCSI)
iSCSI雖名為「SCSI」,事實上與實體的SCSI介面沒有太多關係,IBM提出iSCSI主要是希望能提供較「儲存區域網路(Storage Area Network, SAN)」低廉的儲存解決方案,讓預算有限的企業也能享受接近SAN的儲存優點。
目前企業級儲存設備中除磁帶機、磁光碟機外,尚有DAS、SAN、NAS三種以硬碟為基礎的儲存設備,然而三者的傳輸介面皆不同,DAS多半用SCSI,SAN用Fibre Channel(光纖通道),NSA則是用Ethernet,其中DAS推出的歷史已有10年,SAN於1998年開始興起,NAS則是自2000年才開始展露,DAS、SAN都是讓伺服主機延伸儲存空間的作法,唯獨NAS是以IP型態獨立於Ethernet中,以單點裝置服務其他Ethernet中的電腦,包括工作站、伺服器等等。
無論是DAS、SAN的主機延伸,還是NAS的單點獨立提供服務都有其優點在,前者有助於儲存資料的整合管理,後者則在系統與設備管理上較方便(以IP為基礎的軟體管理工具都可以對其進行管理),此外SAN的建置成本高昂,每部主機需要安裝光纖卡、佈設光纖線、連接光纖集線器或交換器等,相對的NAS所用的Ethernet則成本低廉,所以IBM取兩者之長,實體線路上以Ethernet連接所有主機與儲存設備,但協定傳輸上則以TCP/IP夾帶SCSI指令為主,如此主機即可透過Ethernet存取DAS、SAN設備,如同用Fibre Channel一樣,且具有Fibre Channel所缺乏的IP管理特質。
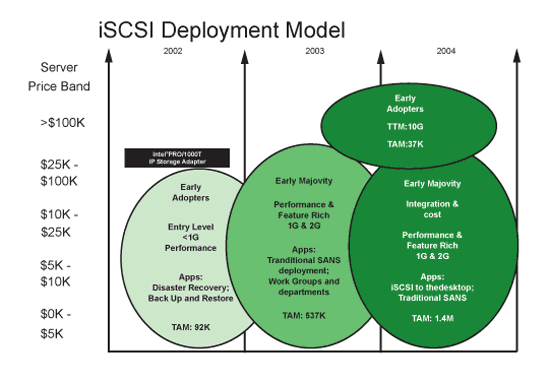
| 《圖四 iSCSI Deployment Model》 |
|
更進一步的,企業內的LAN(Ethernet)與企業外的Internet連接後,也可透過路由器連接到遠端的DAS或SAN設備,讓機房內的主機存取遠在地球另一端的儲存設備,就如同存取自己機身內的硬碟一樣,完全感覺不出差異性。
整體而言,iSCSI是IBM提出的「窮人的SAN替代方案」,以Ethernet替代Fibre Channel來建置儲存區域網路,為了實現此一想法,主機上的驅動程式、儲存設備上的驅動程式都必須換成支援iSCSI的版本,如果還要存取遠端的儲存設備,更要使用能支援iSCSI的路由器才行,這方面IBM是與CISCO合作,由IBM提供支援iSCSI的伺服主機與儲存設備,由CISCO提供支援iSCSI的路由器,共同推展iSCSI的企業儲存解決方案。其推展模式請參考(圖四)。
InfiniBand
InfiniBand的提出,即是為了解決「PCI頻寬不足」與「運算機房內骨幹與叢集連接介面紊亂」等兩個問題,但事實上在InfiniBand還沒有出現前,Intel自己就已經在研究類似InfiniBand的解決方案,此時稱為NGIO(Next Generation I/O),不過不是只有Intel發現問題與想解決問題,IBM方面也有同樣的問題與困境,IBM也是自行研發解決方案,並且與其他系統業者(HP、COMPAQ)共同發展與制訂。
由於Intel與IBM所要解決的問題是同一個,因此各自發展並無益處,經過一番磋商後,於1999年8月正式敲定雙方的合作,將共同一致的解決方案稱為InfiniBand,且獲得軟硬體大廠的共同支持,這些支持者除Intel、IBM外,還包括有微軟(Microsoft)、昇陽電腦(Sun Microsystems)、戴爾電腦(DELL)、惠普電腦(HP)、以及康柏電腦(COMPAQ)等等。
經過共同研發的結果,InfiniBand v1.0正式版於2000年10月24日發表,隨即v1.0.a版於2001年6月19日發表。
InfiniBand的原始用意也包含了要取代PCI,許多新介面都是要取代PCI過於慢速的問題所提出,例如AGP、Hub-Link、V-Link、MuTIOL、HyperTransport、3GIO等,這些解決方案中除了3GIO同時有提供「晶片連接」與「擴充插槽」兩種特性外,其他都是部分地解決問題而已,AGP只解決3D顯示問題,Hub-Link、V-Link、MuTIOL、HyperTransport只解決晶片間的I/O問題,而InfiniBand則是與3GIO相同,希望「晶片連接」與「擴充插槽」兩者都能提供,才算是完整的解決方案,而其實以往的ISA、PCI等也都是晶片連接、擴充插槽都適用的介面。
現在把焦點拉到資料中心的機房內,在資料中心的機房中,講究的是大運算量、大儲存量,因此以往伺服器用SCSI介面與自己內部的硬碟連接,這種作法使得硬碟的使用率僅有30%以下而已,情況差時更是只有20%、15%,但是若將這些硬碟完全集中到「儲存區域網路(SAN)」的設備中,則可以得到90%以上的利用率,在儲存服務效益上是比伺服器各自配備硬碟來得高的,管理上也由於資料集中,所以管理與維護上都較方便。
所以資料中心的機房內都傾向將所有伺服器內部的硬碟拆除,集中放到SAN設備上,而中間用Fibre Channel(光纖通道)作資料傳輸,可是光纖通道目前的傳輸頻寬約100MB/sec,新的版本則為200MB/sec,但是伺服器內的SCSI介面目前多為160MB/sec(即Quantum所提出的Ultra160/m SCSI),很快的就會換成320MB/sec(即Seagate提出的Ultra320 SCSI),如此Fibre Channel將難以因應。
更重要的,伺服器能連上光纖網路,主要是透過伺服器內的PCI插槽,目前64位元的PCI插槽若以33.33MHz運作,則能夠有266.66MB/sec的效能(Intel的晶片組大多只支援到33.33MHz,但規格書上表示可到66.66MHz),如此也不足以應付Ultra320 SCSI,所以SCSI、PCI、Fibre Channel三者間沒有一個能夠大幅因應另一個介面,三者呈現競賽的局面。
此外如果不將特殊的叢集專用介面算入的話,其實機房內還有最常用的兩種外部傳輸介面,即是Fibre Channel與Ethernet,不過此兩者都有其傳輸上的缺點,這樣缺點正是InfiniBand能夠補強並取代的地方。
TCP/IP的不適性
現在Ethernet幾乎都是拿來跑TCP/IP通訊協定,但是TCP/IP通訊協定的傳輸設計相當複雜,兩傳輸點間都要有7個通訊層級進行溝通才行,因此在傳輸封包中真正的資料傳輸量不大,大多是一些協定的輔助表示資料,所以設計複雜外,實質的資料傳輸效率也不佳。
此外對開發設計者而言,要支援TCP/IP通訊協定,因為其複雜性,所以要撰寫的程式碼也要上千行以上,另外傳送與接收的裝置還需要具備比較大容量的緩衝記憶體,才能迎合此種層級複雜、傳輸無效率的通訊協定。
還有,目前關於TCP/IP通訊協定的支援方式,都是用作業系統的程式來支援,即是用軟體方式支援TCP/IP,但因為TCP/IP的天性複雜,所以在傳輸進行上也相當佔用CPU的運算資源,不僅耗用伺服器的CPU運算資源,也耗用路由器(Router)、交換器(Switch)內的CPU運算資源,因為這些網路設備也是用內部CPU來執行軟體TCP/IP程式,所以整個機房內的各種設備都會耗用CPU資源,甚至會耗用到50%以上的運算資源。
另外Ethernet目前用銅線的極限為1Gbps,雖然有10Gbps版本的Ethernet,但卻是用光纖線傳輸,所以在傳輸介質上還是直接換用光纖比較有未來性。
光纖通道的不適性
Fibre Channel的傳輸協定較簡單,光纖的協定目前也大多用特殊的專用晶片,直接以硬體線路方式支援,如此資料傳輸量大,也不佔用CPU運算資源,傳輸層級也較TCP/IP簡化,可以直接讓應用程式直接存取記憶體,所以比「Ethernet+TCP/IP」的作法理想。
不過Fibre Channel整體建置成本昂貴,相容性亦有未解決的地方,傳輸雖然簡化,但架構也有其複雜性,上述種種原因都使Fibre Channel的普及速度與接受度受限。
InfiniBand扮演的角色
所以無論是「乙太網路」還是「光纖通道」,都不適合扮演「資料中心」機房內的設備連接角色,因此需要一種具有前兩者的優點,並可避開前兩者缺點的連接介面才行,這即是InfiniBand,它在效能上有光纖的優點,在成本上有乙太的優點,既適合普及,也有理想的效能。
InfiniBand的另外一個特點是支援熱插拔,可以在機房設備運作的情況下,進行InfiniBand線路的插接與拔除,而且可以在插拔動作中,設備也進行介面連通與移除的對應動作,這點與USB、1394相類似,相對的乙太網路、光纖通道並沒有這樣的設計,插拔光纖通道卡與乙太網路卡都要關機情況下進行,否則會發生不可預期的錯誤。
至於InfiniBand的傳輸速方面,由於InfiniBand採取雙線差動式傳輸,兩條線路傳送一個「bit」,且單向傳輸,以及串列傳輸,這些特點都很類似現在的HyperTransport與3GIO,而InfiniBand目前的規格書中有1X、4X、12X三種傳輸模式,1X單一對線路可以傳2.5Gbps,約相當於500MB/sec,4X可達2000MB/sec,12X更可達6000MB/sec。
InfiniBand適用的網路設備
除了伺服器與路由器、交換器會率先且迫切地需要InfiniBand外,其他如「伺服器負荷平衡器QoS」、「快取裝置Cache」、「密碼安全加速器SSL Accelerator」、「圖形引擎Graphics Engine」、以及特殊用途的加速器等,未來也都有可能採用InfiniBand,以加速資料中心內各網路設備間的資料交換、傳輸。
所以未來InfiniBand將會統一資料中心內的後端網路,即是設備與設備間普遍用InfiniBand架構進行傳輸,並讓叢集電腦間的資料傳輸,甚至可能會取代光纖通道等,不過資料中心的前端網路仍為是乙太網路,因為資料中心對外仍是透過網際網路提供給用戶服務,所以乙太網路仍然是需要保留的。
InfiniBand發展進程推估
InfiniBand已於2000年10月發表v1.0的正式版,因此具體商業化的產品也開始可以推出,事實上Intel於2000年年底就已經有InfiniBand的樣品出現,而2001年也開始有少量使用InfiniBand架構的伺服器、交換器、以及其他機房網路設備出現,
而目前2002年,預計InfiniBand的支援產品層面會再擴大,不再拘限於如伺服器、交換器等基本、迫切的需求,包括叢集網路、儲存區域網路、網站用交換器等也都會相繼支援,然後2003年、2004年預計會更普及,並普遍用於資料中心的機房內。
除了商業角度的進展推估外,國外知名的研究機構IDC也同樣透露,IDC認為到了2004年支援InfiniBand的功能晶片,其市場規模將達420萬顆以上,這在伺服器市場上已屬多數,如此推估,到了2005年,就會有80%以上的伺服器會採用InfiniBand介面。
InfiniBand原希望徹底取代PCI的,不過PCI的慢速已經有PCI-X為其延伸,得到暫時的抒解,PCI-X也有後續的提升計畫在,所以插卡方面的問題暫時解決。
至於晶片與晶片間的傳輸介面,PCI一樣無法應付,但在HyperTransport出現後也得到了暫時解決的方案,而未來3GIO更會將兩者統一,回復到所有溝通路徑都是用同一種介面與插槽的方式,未來3GIO不僅可能成為晶片與晶片間的高速連通介面,也會是高速的插槽,甚至取代掉AGP等。
所以InfiniBand當初欲取代的地位已經有其他方案取代,所以InfiniBand改走機房內的設備專用連接作為其出路,希望能用其統一機房的後端網路連線,包括統一各自為政的叢集連接等,算是由以往的大眾地位走入特殊的小眾應用領域了。
最後是關於InfiniBand的主要支持成員如下所列:
結語
上述的數種新款高速介面,許多都是針對PCI傳輸逐漸不足而提出,相互間雖有部分設計重疊,但也仍有各自特點的需求性,未來何種規格介面可以勝出,仍有待技術成熟度、市場接受性等發展來決定。