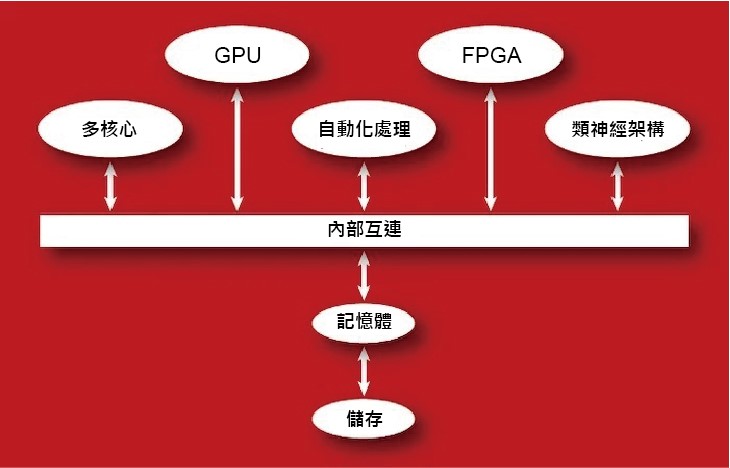
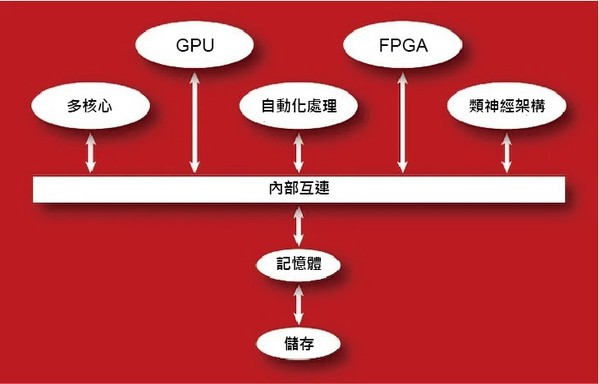
雖然邊緣計算有無數種定義,但今天的邊緣運算大多是指透過這項技術,將運算、儲存和網路等功能的子集(subset)工作,被分散到位於網絡中最遠端的一層或多層邊緣節點。今天的邊緣節點通常利用同質運算基礎,也就是所有處理都在同一類型的CPU上運行。
CISC/RISC處理器是迄今為止最主要的解決方案,較小的邊緣節點只需要使用單核心CPU就有足夠的處理能力,通常使用X86或ARM架構。而更大的邊緣節點則採用多核處理器的方案,內建2個~32個不等的X86、ARM或RISC-V內核,或者包括多個相同類型的CPU處理器。
雲端數據中心的多處理單元異質架構
在雲端平台方面的計算資源,是由傳統的複雜指令集計算/精簡指令集計算 (CISC/RISC) 伺服器所組成,或許也有部分平台還包括了,圖形處理單元 (GPU) 加速器、張量處理單元 (TPU)、場域可程式閘陣列( FPGA)和其他一些處理器,來幫助加速部分的工作。
| 圖一 : 一個先進通用的異質運算系統。(source:Mohamed Zahran) |
|
雖然這樣的雲端平台方面有強大的運算能力,但隨著邊緣節點的增加,大量的運算需求,開始大量消耗著雲端平台的資源,導致整體效率大幅滑落。
因此異質運算的概念就被提出,並且正被實現中。異質運算是一種將不同數據路徑架構下的不同類型處理器,以優化特定計算工作負載的執行技術。所以,在決定如何在雲端數據中心,和邊緣運算節點之間劃分工作負載時,需要考慮許多權衡,來對每一層設計中面為不同應用程序時,進行優化的處理器數據路徑架構就變得相重要。
在這樣的架構下,雲端數據中心可以將許多工作負擔,分散到邊緣節點的異質運算架構中。包括用於多種處理器類型的模組,包括 CISC/RISC CPU、GPU、TPU 和 FPGA等。而運算工作負載不僅可以分散在邊緣和雲之間進行,更可以在兩個相異級別的異質處理資源之間分區進行。
例如圖二中節的點F2和F3,可以並行地處理從F1傳送的數據。而F4則是可以獨立地處理來自F2和F3的數據,或者處於等待狀態,直到來自兩個節點的數據出現,這取決於所需的行為。
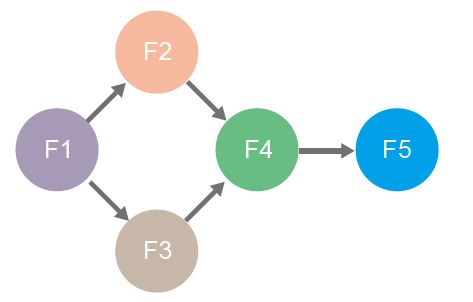
| 圖二 : 多種處理器流程圖的圖示例。(資source:Institute for Information Transmission Problems, RAS;作者整理) |
|
同時許多流程節點可以並行執行,其中也會一些不能,因為它們的功能無執行緒安全,尤其是對於神經網絡節點,情況更是如此。
在軟體方面,則有多種平台可以選擇,例如Microsoft的Azure Edge、Amazon的Greengrass、VMware Edge,以及 Eclipse、EdgeX Foundry和Linux等。透過這些軟體來管理邊緣節點中CISC/RISC的基礎架構、配置、安全性、編排、管理等。
加速器與CPU協同使用 提高系統效能
隨著人工智慧/機器學習開始佔據優先地位,新出現的各種應用陸續對處理單元提出了獨特的服務需求,包括了可以執行乘積累加運算(Multiply Accumulate, MAC)、極高並行化和大量數據存取等運算任務等。
因此,這樣的背景下,期望能滿足效率提高且不增加功耗,又可以支援人工智慧/機器學習下,最好的方法就是建立一個全新的運算架構,而這個架構可以由多個協同工作的專用運算模組所組成。每個模組都能高速的執行單一任務,並且在低功耗下,呈現出的是更高的效能和更低的整體功耗。
異質系統是可以提供更高效率的運算能力,就如上述,需要跨主機CPU和加速器來分配工作。因此就需要一些方法來對參數的分析與AI的規劃,在機器學習模型最佳化後,讓系統達到接近最優秀的配置。
從歷史上看,運算處理是一項通用任務,利用CPU可以順利地執行許多不同的任務,但以今天的觀點來看,這並不太聰明,因為一次只能執行單一任務。
直到圖形化使用者介面(GUI)的出現,使得操作和運算處理變得越來越複雜,因此GPU就被開發出來作為個專門的、高度並行運算的處理器。
加速器通常會與CPU協同使用,來提高整體系統的效能。例如,前500強的超級電腦名單裡,功能最強大的5台電腦中,就有3台是採用GPU作為加速器的異質電腦(圖三)。因此可以透過不同的架構特性和大量的系統參數配置(例如執行緒數、執行緒親和性、主機多核處理器與加速設備之間的工作負載劃分),設計出最佳的工作負載分配,來實現最優異質系統的性能和耗電效率。

| 圖三 : 500強的超級電腦前5強中,就有3台是採用異質架構。(source:Top500.org) |
|
不過必須注意的是,能夠產生最高吞吐量的最佳系統配置未必是最省電的。此外,最佳系統配置也有可能需要因應不同類型的應用運算、輸入問題大小和可用資源而進行調整改變。
異質節點的效益衡量標準
在優化經濟效率方面,工業物聯網聯盟CTO助理Charles Byers曾經提出2個計算方法:一些吞吐量/一些成本來作為衡量標準(Some throughput measure/Some cost measure)。
隨著更開放的軟體和硬體生態系統,硬體的成本將會持續降低,而使得更龐大終端客戶採用多邊緣運算。每一美元所購買的系統能擁有更多吞吐量下,是優化邊緣系統總生命週期的一種重要成本方法。因此一美元購買的吞吐量,在很大程度上取決於系統架構、處理器的能力、基礎設施的效率,以及被要求的軟體平台和演算法。
邊緣節點運轉所需的電力是一個極其重要的考量部分,無論電力是由電池供電,還是直接從電纜供電,耗電率通常是佔營運成本的最大比例。另一方面,進入處理器的電能幾乎完全轉化為熱量,而這些散熱設施,也會是建置和運營成本的重點之一。因此,電源和散熱是相當大程度決定了邊緣運算單元的吞吐量。
此外,空間也是另一個考慮因素,邊緣節點是否位於蜂窩塔的底部、路邊機櫃、貨櫃大小的微型數據中心、車輛中,甚至是可攜帶式。隨著處理器愈來愈多,空間相關的成本也會相對地急速增加。
在計算與邊緣運算節點相關的真實成本時,權重是另一個經常被忽視的考慮因素。在某些情況下,尤其是對航空、太空、海上或可攜式的產品規劃時,重量受到很大限制下,處理器技術的選擇就會對系統的整體重量產生很大影響。
邊緣計算的性能、成本和效率,可以透過仔細選擇各種類型的異質處理器來進行邊緣工作負載。因應不同工作負載需求,可以透過選擇不同的處理器類型來組成最佳化的的運算模組。
更進一步的可以透過模組多元組合機制,動態地調整各異質處理器架構,來匹配來自於負載的需求。因此異質處理器技術,在邊緣運算中特別具有價值性,因為它們可以大大改善資源受限的邊緣節點,來降低吞吐量成本以及提高經濟效率。
工作負載的方式不斷改進
目前雖然有許多系統採用異質架構來加速工作負載中的人工智慧部分,但可惜的是只在節點層面上的建立異質運算。可以坦白的說,在每個運算節點上部署這些資源是不符合成本效益的。
部分原因是,工作負載主要以物理為基礎來進行模擬,而許多工作並不會使用這些資源,因此大部分時間都會被閒置。此外有許多加速器不是針對運算節點部署而設計的,這會比預期的成本更加昂貴,最重要的是,它們還不是最有效的部署方式。
也就導致目前對於工作負載的改進,不斷的有論文被發表出來,特別是今天大家所關注被稱為認知模擬的工作。
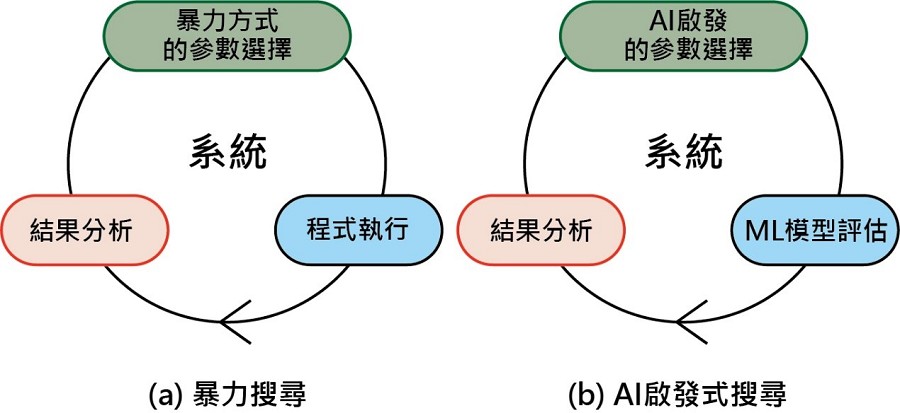
圖四是系統性能調整的過程。傳統上,尋找最佳系統參數的過程涉及到選擇參數值、程式執行和多次反覆的性能分析(圖四a)。較常見的暴力搜索(Brute-force Search),需要對所有可能的參數值執行分析,因此,對於現實世界的程式和系統來說,可能需要花費更長的時間來尋找出最佳參數。
而與暴力搜索相反,透過人工智慧的啟發式搜索是透過自然啟發式演算法為基礎,能夠以較少的性能測試,來找尋到最佳的解決方案,其基礎是自然啟發式演算法(例如,Simulated annealing或Artificial Bee Colony)。而圖四b則是說明了,利用AI啟發式參數值選擇與機器學習模型相結合,來進行性能評估的方法。
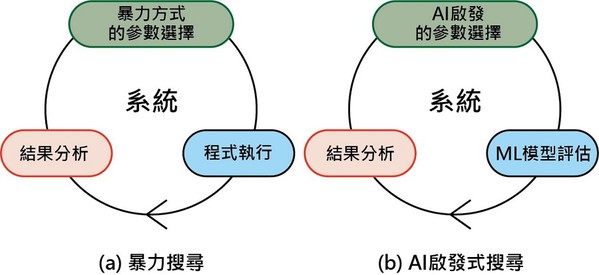
| 圖四 : 使用AI規劃啟發式和機器學習優化異質系統。(source:SpringerLink-Suejb Memeti & Sabri Pllana研究論文;作者整理) |
|
利用參數空間的智慧導航減少總暴力實驗
使用AI啟發式搜索技術的優化過程,但會涉及到隨機選擇參數值的系統配置,和使用機器學習模型的系統性能評估。雖然可以利用暴力搜索的方法,迭代(Iterative)出所有可能的參數配置,但是這樣會使用了大量的總暴力實驗。
因此,瑞典卡爾斯克魯納布萊金厄理工學院歐洲的兩位專家,Sabri Pllana與Suejb Memeti就提出利用參數空間(parameter space)的智慧導航過程,來確定最佳的系統配置,而這樣的方式下,只需要進行一小部分可能的性能實驗。這比起前述的方式,只需使用大約7%的總暴力實驗,就能夠確定每焦耳下最佳的系統配置。此外,使用這個方式的機器學習模型來評估系統組態,會比利用程式執行來評估系統要快1000倍以上。
雖然異質架構是現階段建立具有高峰值性能,和低能耗的計算機系統的最可行方式,但CPU和加速器之間的最佳工作共享並不明顯,同時考慮性能和能耗也會使工作共享問題進一步複雜化。因為優化過程涉及到了隨機選擇參數值的系統配置生成,和使用機器學習模型的系統性能評估,因此可透過概率啟發式搜索技術來進行參數空間探索。
經過實驗發現,在這樣的方式所開發的機器學習模型,為搜索出最佳系統配置所提供訊息的準確度超過了95%。同時在速度上,更比暴力搜索快上1300倍。
所以在邊緣運算、霧運算和雲運算的背景下,各層次之間的數據移動成本很高,想要確定在哪一層執行處理是最佳的模式這並非是易事。此外,與異質系統相類似,對於特定的問題,在不同層中可用各種資源間的共享工作負載,也會產生與能量、性能或成本的最佳解決方案的選擇。