前言:突破摩尔定律屏障、最佳瓦效能─多核心处理器
过去,CPU研发厂商遵循着高登‧摩尔在1965年提出的摩尔定律─每18~24个月单位面积的电晶体数量/效能倍增的趋势,新世代处理器研发,凭借每两到三年的制程进化,得以在一定的晶粒面积(成本)下用更多的电晶体来设计,凭借新架构与线路微缩的时脉提升来强化矽晶片的运算能量。但是在跨入21世纪之后,这股一昧追求高时脉以及高运算效能的CPU研究风潮,各厂开发的新世代处理器晶片的功耗与废热急速攀升,快要到了到近乎失衡的地步。
在当今逐渐强调每瓦效能的环保趋势下,以验证过的单一核心,借助制程技术做两颗、四颗对称式的叠加起来,直接设计出晶片多线绪(Chip Multi-Threading;CMT)或晶片多重处理(Chip Multi-Processing;CMP)的多核心处理器,搭配多线绪化的软体下得以直接提升平行运算的效能,享有较佳的效能/功耗比,已经是必然的趋势。
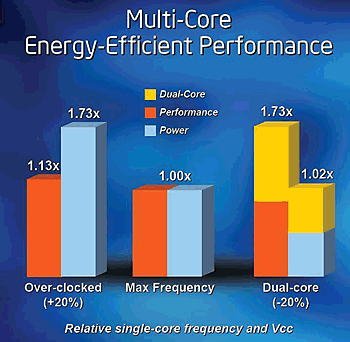
| 《图一 以图标说明为何多核心有最佳瓦效能。以相同制程技术,单核心CPU若超频20%,实际效能约提升13%,功耗却暴增73%(图左);若将单核心CPU降频20%,效能仅下滑到86%,功耗可减少约一半;将两颗降频20%的CPU迭成双核心,功耗跟单CPU几乎相同下,搭配优化双线绪软件,效能可提升87%左右。(数据源:Intel IDF技术文献)》 |
|
特别是在伺服器电脑系统,向来就是最早导入双颗、四颗甚至多颗CPU以平行对称多处理器运算(Symetric Multi-Processor;SMP)的方式设计,相关的伺服器作业系统、专属应用软体也已经多线绪化(MultiThreading),导入多核心CPU不仅相关硬体平台与软体环境搭配都最为成熟,同时还能缩减原先做四颗、八颗处理器的伺服器平台的大小与建制成本,缩减到仅以往一颗实体CPU所需的系统,就能享有以往四颗、八颗甚至更多颗实体CPU平行运算的效能。
双/多核心的处理器发展史-双打时代开幕
谈到开启多核心CPU研发的号角,首推蓝色巨人IBM,在1999年10月微处理器论坛中率先揭露了其双核心POWER4的研发计画,以180奈米铜导线绝缘矽(SOI)制程打造,并采四颗矽晶片多重陶瓷封装的设计,单一实体外观POWER4 CPU就具备八线路(8-Way SMP)执行能力。在2001年10月,推出采用POWER4 CPU的eServer p670伺服器。紧接着在2003年8月IEEE Hots Chips热门晶片会议中,IBM揭露具备同步超执行绪(SMT─Simultaneous Multi-Threading)概念的POWER5处理器,POWER5具备四个逻辑处理器核心,可以同时执行四个程式线绪。
惠普(HP)也曾于2001年10月微处理器论坛中,揭露双核心HP PA-8800及后来时脉强化的PA-8900处理器,但随着HP伺服器策略全面转向Intel Itanium,PA- 8800/8900推出后成为绝响。另一家以Solaris作业系统与UltraSPARC伺服器处理器闻名的升阳(SUN),也曾发表双核心UltraSPARCⅣ处理器的计画,但后来因故取消。
宿敌超微(AMD)也在2004年8月31日,实机展示安装四颗双核心Opteron处理器的惠普HP ProLiant DL585伺服器,呈现八线路(8-Way SMP)平行运作的能力。至此英特尔(Intel)则在2004年9月秋季IDF中首度揭露双核心Itanium2 CPU(代号Montecito),并在2005年春季IDF时,从桌上型的Pentium D、Pentium Extreme Edition,笔记型的Core Duo(Yonah)以及伺服器的XEON 7000(Tulsa)等双核心系列CPU计画。
接下来我们将分上下两集,这次先针对大型主机、高阶伺服器等集中式伺服器所设计,强调规格、可靠度的多核心伺服器CPU做介绍;下集再针对一般网路伺服器、游戏机/伺服器,以及最普遍的x86伺服器所设计的多核心CPU来作说明。
IBM POWER4/POWER5/POWER5+处理器,以及即将推出的POWER6
先从目前IBM仍在使用的IBM POWER5/POWER5+开始介绍。 2004年5月发表的POWER5,采用130奈米绝缘矽制程,八层金属层互连设计,电晶体数两亿七千六百万(276M Transistors),矽晶粒面积为389mm2。工作时脉提供1.9GHz、1.65GHz以及1.5GHz,设计功率为80W。随后2005年10月POWER5+则改采用90奈米制程,时脉突破到2.3GHz,矽晶粒面积微缩至230mm2,同时设计功率降到70瓦,但仍维持跟原先POWER5相同的核心架构。

| 《图二 POWER5处理器模块采四颗CPU硅芯片搭四颗L3 芯片的多重芯片封装》 |
|
POWER5/5+ 采双核心(Dual-Core)设计,每个核心具备64KB L1指令快取、32KB L1资料快取,第二阶快取记忆体采三区块设计,共1.875MB(3 x 640KB )。外接的L3 eDRAM快取记忆体模组直接连通到L2快取记忆体,而不是如POWER4/4+那样得藉由光纤介面控制器,容量则从36MB开始起跳,eDRAM Cache时脉也从原先POWER4时代的1/3的CPU时脉进展到1/2。同时在外观上,POWER5/5+采用四颗CPU矽晶片搭四颗L3晶片的多重晶片封装(Multi-Chip Module)。
POWER 5核心具备120组通用与浮点暂存器组,并改进了指令预撷取缓冲器(Instruction PrefetchBuffer;IPB)、指令执行状态保留区(Reservation Station;RS)及位址转换表(Address TranslationTable;ATT)上做有改进,并实作出可以一分为二的单核心同步超执行绪(SMT─SimultaneousMulti-Threading)的能力,每个子CPU核心可以模拟成两个逻辑处理器来协同运作;加上POWER5处理器又包入四个CPU矽晶片,相当于一颗POWER5处理器实体晶片,就可以开启4x4=16个逻辑处理器,同时执行16个线绪的强悍能力。
IBM POWER5处理器晶片内建Virtualizine Engine虚拟化引擎,每个处理器的微分区技术,允许定义10个动态逻辑分割区(LPAR)或「虚拟伺服器」,可以虚拟、模拟出不同伺服器的环境,每部虚拟伺服器可选择UNIX(AIX 5L)、Linux或i5/OS作业系统。
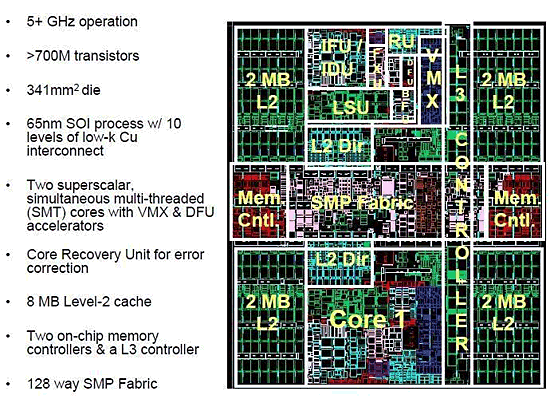
| 《图三 IBM于ISSCC 07论坛公布的POWER6硅晶电路图》 |
|
IBM 于2006年10月中旬微处理器论坛中,首度揭露POWER6细节,采65奈米铜导线加绝缘矽制程技术,矽晶粒面积达到341mm,电晶体总数达七亿九千万颗(790 Million Transistors)。大致上仍维持单矽晶双核心,每个双核心能两路执行绪(2-Way CMT)的设计。每颗CPU核心以既有的POWER5/POWER5+核心架构做延伸,拥有独立的4MB L2 Cache(两核心一共8MB),并且每个CPU核心扩增解码单元,能一周期发送七道指令并分配到两个线绪执行单元(POWER5/5+则为5道),并增加了十进位浮点运算单元、VMX单元以及即时修复单元(Recovery Unit),预计将会以5.5~6.1GHz超高时脉运作。
传统二进位浮点运算的资料记录格式,由于转换上会有精确度误差的问题,向来不适合于法务与金融上的需求,像是电信公司的帐单、税务计算等等。据IBM资料显示,全球约有55%的数字资料库采用BCD(Binary Coded Decimal)记录,而其余的43%中的整数资料,大多也是十进位运算。以BCD方式储存与运算上,会有精确度提升但浪费记忆体与转换时间的问题,IBM在POWER6设计加入符合IEEE 754R规格十进位浮点运算单元(Decimal FPU)的概念,并追加50道处理这类BCD资料的指令,处理这类资料的运算速度将会提升至少两倍以上。

| 《图四 IBM POWER6特有的十进制浮点运算电路的设计(数据源:IBM MPF2006技术文献)》 |
|
IBM POWER6处理器将多颗平行处理(SMP)的连接方式,从以往的四颗一组的循序串列方式,改成了四颗一组,八组以环状星形方式相互以高速光纤网路介面连接,能有效降低每个处理器模组相互沟通的延迟效应。IBM POWER6也在伺服器强调的RAS(Reliability, Availability, Serviceability)功能上强化,从每颗CPU核心内的每个运作单元,从指令预撷取区、执行单元、记忆体载入/储存单元等都具备即时错误侦测修正(ECC)能力,即时修正维护每一笔资料运算的正确性;当其中一个CPU核心发生位元错误时,可重新启动,再度启动仍发生错误时,则会由整颗CPU核心管理线路将该子核心电路移除于工作状态。
由备位变正取的富士通SPARC 64 v处理器
在日本大型电脑市场上闻名的富士通(Fujitsu),在获得SUN Microssystem升阳电脑授权UltraSPARC处理器相容架构的SPARC64Ⅳ、SPARC64Ⅴ架构之后,藉由自身在制程技术的掌控、研发团队的努力下,研发进展超越原设计者;加上SUN升阳随后的CPU研发策略转向,双方签订了APL(Advanced Product Line)的计画,将整合SUN与Fujitsu双方高阶伺服器的产品线与客户交接到SPARC64系列。
在2004年10月微处理器论坛,Fujitsu公布代号Olympus的新一代双核心处理器SPARC64Ⅵ规格。 SPARC64Ⅵ是以两颗SPARC64Ⅴ的处理器核心叠加而成,每个SPARC64 CPU具备256KB的L1快取记忆体(128KB指令,128KB资料),两个SPARC64核心外接并共享6MB快取记忆体,每个核心也具备两线绪执行能力(Two way CMT),因此一颗实体SPARC64Ⅵ具备四线绪平行执行能力。它采用90nm制程铜导线、10道金属层布线制造,总电晶体数目达6亿9千万颗(690M Transistors),矽晶粒面积则为400mm2。推出时脉从2.4GHz起跳。

| 《图五 Fujitsu SPARC64Ⅵ处理器与运作单元图(数据源:Fujitsu网站、MPF2006技术文献)》 |
|
除了具备双核心、四线绪执行能力之外,SPARC64Ⅵ也针对原先CPU核心架构进行改良,将硬体资料预先撷取机制以及指令码分支预测能力强化、加倍位址转换的缓冲器等等,增加RegisterWindow实体暂存器数目,加倍浮点运算单元,也引进代号Jupiter的新型系统汇流排,透过多条单向的资料传输路径提升载入和储存的效率。Fujitsu宣称,新一代以90nm制程打造的SPARC64Ⅵ处理器,每颗CPU核心能较升阳上一代SPARCV处理器提升25%的浮点运算效能,一个实体处理器插槽更能提升2.5倍浮点运算效能。
在伺服器强调的RAS上,富士通SPARC64Ⅵ系列CPU,从每一个指令预撷取、解码、位址载入储存、浮点运算单元的路径等,全矽晶片几乎99.96%区域(其余为错误也不会造成损害区域),具备ECC错误即时修正能力,以及独特的指令执行错误重试功能,更是让富士通能继续在日本大型电脑市场上称霸一方的拿手绝活。
针对IBM POWER6的来势凶凶,Fujitsu也在2006年10月微处理器论坛上宣布,将针对大型电脑版本的SPARC64Ⅵ处理器追加十进位浮点运算单元,同时也预告了以65奈米制程打造的四核心SPARCⅦ处理器的计画。四核心八线绪的SPARCⅦ将以2.7GHz时脉起跳,预计2007年下半到2008年上半年之间推出。
英特尔双核心四线绪Dual-core Itanium 9000(Montecito)
于2004秋季IDF揭露,拖延半年总算于2006年七月正式推出的英特尔新世代Itanium家族的新成员─Montecito,正式名称为Dual-Core Itanium 9000系列。也是英特尔针对EPIC(Explict ParallelInstruction Computing)或称为IA64架构的第一颗双核心的处理器。其中最高等级的为1.6GHz、具备12MB x 2(24MB)L3快取记忆体的9050系列。
Dual-Core Itanium以两组Itanium2(Madison)核心叠加起来,每个CPU核心具备独立的32KB L1 Cache、1MB L2 I-Cache、256KB L2 D-Cache,并各自拥有12MB的第三阶快取记忆体;90奈米应变矽制程,电晶体数量17亿两千万颗(1.72Billions Transistors),矽晶面积596mm2的伺服器CPU。预料今年底推出的Montvale,则会借助65奈米制程技术,将矽晶面积微缩到400mm2以下。
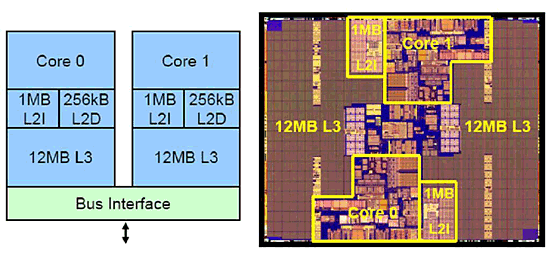
| 《图六 Intel Dual-core Itanium 9050(Montecito)处理器结构与硅晶电路图》 |
|
Dual-Core Itanium每个子CPU核心可以开启两个执行线绪做2-Way SMT(Simutaneous Muli-Threading),因此一颗Dual-Core Itanium(Montecito)就具备4-Way SMT、四颗逻辑处理器或执行四线绪的执行能力。同时Montecito处理器能搭配原先Itanium、Itanium2的汇流排介面,既有的Itanium伺服器系统,也可以以换装Montecito处理器卡匣的方式,升级到具备晶片多线绪等级的平行运算能力。
藉由Foxton节电管理技术的协助,能将未使用的逻辑处理器、快取记忆体以及对外I/O部份依需要动态关闭或开启,并依负载动态调升或调降时脉与电压, Dual-core Itanium平均设计功率约104W。而Pellston快取可靠性技术,CPU核心电路每次存取快取记忆体时,会即时做一次ECC检查,若发生错误而且可以修正,则重新写回修正后的资料到快取记忆体,并随即读取出来反覆检查,若检查过仍然发生错误,或者一开始就发生两个资料位元的错误,则会自动关闭那个发生ECC错误的快取记忆体区域,但其他运作正常的快取记忆体区域仍可继续使用。
Itanium/Itanium2以及Dual-Core Itanium等EPIC(IA64)指令集架构的特性,就是剔除掉以往过于复杂的非循序执行(Out of Order Execution;OOOE)指令集分派电路,借助外部编译软体以及内部超长指令集架构的相互配合,把软体程式码编译成执行单元指令互不冲突的指令群,才能发挥超长指令集平行处理的效能。当EPIC架构以双核心搭配晶片多线绪实作下,受限于IA64核心架构的OOOE非循序执行特性,许多执行绪无法借助硬体来分均分派每个逻辑处理器,因此在Dualcore Itanium处理器要执行多线绪应用软体,得仰赖编译器重新针对Dual-core Itanium特性重新编译并做排程最佳化,才有可能充分发挥双核四绪的执行效能。
??
??
??
??
4


