網際網路時代來臨後,帶來一個含有文字、圖片、聲音、影像等多媒體內容的新資訊世紀。由於資料極為龐大,且散佈在世界各處,搜尋引擎這個我們耳熟能詳的工具,也隨之興起。透過搜尋引擎,我們可以找尋滿足需求的資訊。小學生交作業,研究生寫論文,自助旅行者收集旅遊資料、股票族買賣股票...,上網查資料是必須做的功課,全球資訊網檢索已經成為生活中重要的一環。Yahoo、AltaVista、Lycos、Google、Openfind等全域性搜尋引擎隨之崛起,扮演搜尋入口網站的角色,提供巨量資訊檢索服務。政府單位、民間企業、學校...等,在網站中通常也會附加檢索工具,提供站內資訊搜尋服務。
了解檢索的需求
使用者對於資訊檢索的最理想要求,是在最短的時間,找到最完整、最精確的資訊。在網際網路上,由於資訊量非常龐大,搜尋回覆時間和準確度,是使用者滿意度重要指標之一。一般人會認為資訊檢索品質的好壞,檢索系統要負完全的責任。其實不然,搜尋行為是使用者和檢索系統間的互動。使用者必須把心中的資訊需求明確的說出來,檢索系統才能完成交代的任務。問題是資訊需求的呈現通常非常模糊,例如我們對「諾貝爾獎」的資料有興趣,可能的查詢包括:
- ●「諾貝爾獎」
- ●「諾貝爾獎得主」
- ●「2003年諾貝爾獎得主」
- ●「2003年諾貝爾和平獎得主」
需求由最模糊的單詞「諾貝爾獎」,到較精確的片語「2003年諾貝爾和平獎得主」,所呈現的語意都不一樣,檢索系統回覆的搜尋結果,當然就不一樣。理想中的系統,應該是使用者提供的資訊越精確,搜尋回來的答案越準確。
從使用面看,查詢詞彙通常相當簡短。經網路使用者查詢語彙分析,平均長度為6.36 bytes,接近2-3個中文字元的複合名詞。簡短的查詢詞彙,通常無法掌握資訊需求。使用者的行為分析,建議合適的檢索詞或相關主題詞彙、查詢記錄分析提供建立索引典的參考等,附帶服務和功能就被引介進來。本文擬由資訊檢索系統的基本架構,談如何找尋滿足需求的資訊。考量中文的特性,分析斷詞對檢索效能的影響,斷詞技術介紹也是主題之一。面對完整資訊需求的呈現,談系統可能的改進對策,介紹中文開放領域自動問答系統的發展。
資訊檢索
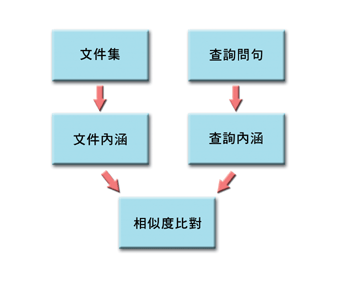
由技術面看,一個資訊檢索系統包括三個重要的部分:文件集和查詢問句的處理、以及文件和查詢的相似度計算,可參考圖一。文件集在網際網路搜尋引擎就是網頁資料,資訊檢索系統會擷取重要的詞彙代表文件的內涵,以合適的資料結構儲存,目的之一是加快搜尋的速度。當使用者下檢索指令時,檢索問句也做類似的處理,接著進行快速比對,依照算分公式計算,依分數大小順序,列出“符合需求"的資訊。
在傳統資訊檢索架構中,最被挑戰的地方是:關鍵詞比對,而非概念比對,因此會有相同的概念,但是可能無法找到以不同詞彙表達的資料的問題。由於在網際網路檢索,正確性優於完整性,如何處理這個問題,不是本文討論的範圍。本文的重點將著重在說明如何減少太多不相關網頁被檢索出來,以降低使用者瀏覽、判斷相關性所發的時間。
以一個簡單的例子說明,假想某國小五年級學生的寒假作業是收集「門聯」的相關資料。如果透過搜尋引擎在網路上收集,最直觀的的檢索詞是「門聯」。搜尋引擎回傳可能的資料包括:澳門聯網、萊特門聯合企業股份有限公司、部門聯絡、聯語有門聯楹聯之稱、...等,直到第四筆資料才是真正所要的網頁。
斷詞是相關性判斷出錯的原因之一,由於中文句子詞彙和詞彙間並沒有明顯的分隔符號,造成在詞彙切分時,容易有多重選擇的情況。以搜尋引擎為例,在建立網頁索引檔、或處理查詢問句時,可能以內建的辭典作查詞運算。若有多重分詞的情況,會依某些原則選擇其中之一。例如將「澳門聯網」當作檢索詞送入Google,由回傳的結果中,選取「頁庫存檔」,會出現「您的查詢字詞都已標明如下: 澳門 聯 網」這項訊息。由此可知,「澳門聯網」被切分成「澳門」、「聯」、 和「網」三段。其中「澳門」切對,而「聯」 和「網」應合在一起形成一個詞。
斷詞技術
斷詞是中文資訊處理基本運算,挑戰處在於分詞的歧義性,以下是個範例:
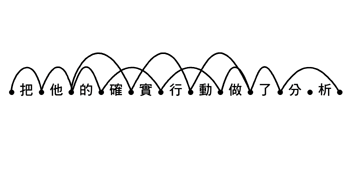
句子「這名記者會說國語」,如果不看上下文,可能會被切分成「這 - 名 - 記者 - 會 - 說 - 國語」、或是「這 - 名 - 記者會 - 說 - 國語」,但僅有第一個斷法是正確的。詞典是斷詞處理不可缺少的重要資源,一般的處理模式是:先查詞,列出"所有"可能的詞。接著進行歧義排除,挑出最佳組合。例如:處理「把他的確實行動作了分析」這個句子,經查詞典後,有如圖二的組合:
過去有很多策略被提出來解歧義,包括長詞優先、除去組合中造成路徑中斷的詞區段、偏好二-三字詞、採用剖析法、或馬可夫模型、鬆弛法等統計方式。
但基本問題是:詞典無法完整收錄所有可能的詞,新詞時常被忽略,不能被正確地切分出來。因此,以(半)自動化的方式漸進式地擴大詞典的規模是必要的策略,而加入未知詞處理模式,加強斷詞系統的強健性,也是可能的方式。例如,人名、地名、公司/組織名、時間、日期、錢、百分號等是文件重要成分,呈現人、地、時、事、物等五大單元。而這些通稱『具名實體』的詞彙,又經常沒有被收錄到詞典中,如何辨識是斷詞上挑戰的議題。
以人名辨識為例,姓名結構分析,姓氏(單姓、複姓、冠夫姓)是重要的線索,名字的用字機率(男性、女性、優雅、 ...)、前後文資訊(例如,頭銜、標點符號、特殊用語、 ...)、詞彙的重現性等等,都是可供運用的重要資訊。
詞彙收集是重點
在搜尋引擎,由於回應使用者查詢的速度,以及所管理網頁的巨大量,資料更新的時間要求等考量,通常不作複雜的斷詞處理,而僅進行簡單的查詞動作。因此,詞彙的收集益顯得重要。某些字串經常被輸入為檢索語彙,自然會收錄到詞典。經常使用的詞彙,重要性自然提高,分詞時就會被優先選擇。這些線索都可以由使用者檢索後所留下的記錄統計出來,所以使用者的行為分析是搜尋引擎不可或缺的運算。
中文開放領域自動問答系統
自然語言或稱人類語言一直是最自然的人機互動媒介,是表現資訊需求最直接的方式之一。自然語言問答系統的發展很早,過去就有以人的語言當資料庫系統介面的應用。在網際網路極為盛行的新資訊時代,自然語言問答系統再度吸引大家的注意力。主要的原因是網路世界大量不同媒體所呈現的資訊不斷地產生,傳統資訊檢索技術由文件集中取出相關文件,依相關程度高低排列,再由使用者閱讀的使用模式,在非常大量的資料下,已漸漸不能滿足需求。
當自然語言遇上傳統檢索
以下是兩個自然語言查詢問句的例子,說明使用者在傳統資訊檢索系統下的行為:
- (1)《台灣之子》這本書的作者是誰?
- (2)諾貝爾獎是什麼時候開始頒發?
第一個範例以關鍵詞檢索所找到的文件,可能含有「台灣之子」,使用者必須用眼睛"挖"出答案。同理在第二個範例,帶有「諾貝爾獎」這個詞的文件很多,使用者必須判斷哪一篇才是談諾貝爾獎的歷史。閱讀傳統資訊檢索的結果,再找出答案,使用者需花相當多的時間才完成知識擷取,傳統架構已不敷需求,如何運用自然語言處理技術,由相關文件中找出"準確"的答案,是很重要的網路技術。
過去自然語言問答系統在資料庫上的應用,比較強調的是介面的功能,背後所接的資料規模較小、限定領域、且具有相當的結構性。相較之下,開放領域自動問答系統所面對的是規模龐大、不限領域、不具結構(或僅有部份結構)的資料。重要挑戰包括︰偵測使用者的意圖;掌握問句的核心;在龐大資料下,由機器取代使用者"閱讀"文件,擷取答案﹔掌握人和機器間的互動性;面對不同的媒體素材等。
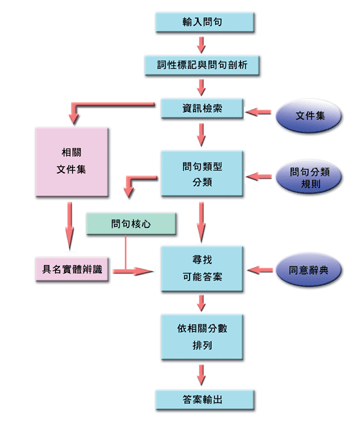
圖三是基本的中文開放領域自動問答系統架構,包括:問句處理、資訊檢索、答案選取、以及結果呈現等步驟。問句處理掌握使用者的資訊需求,由問句中辨識語意核心。這裡的問句核心可能包括使用者想知道的人名、地名、公司名、時間、日期、原因等等。問句核心的掌握,可以幫助系統找到較精確的答案。這部分的工作有:中文斷詞、詞性標記、具名實體擷取、以及問句的分類。資訊檢索系統用來過濾不相關的文件,保留可能含有答案的文件,因此完整性比準確性重要。答案選取步驟的工作是將資訊檢索系統傳過來的文件,切成數個區段,比較問句和區段之間的相似程度,並考慮問句核心,由較相似的區段中擷取答案,整合各個可能的答案後再列出結果。
掌握問句核心
問句核心的掌握相當重要,提供很多回答問題所需的資訊,例如當使用者詢問的是地名時,系統藉由具名實體辨識,找出文章中哪些詞是地方詞,這些地方詞構成候選答案。以下是一些例子:
(1)《台灣之子》這本書的作者是誰?→ 這種問句類型問的是人名。
(2)草嶺谷在哪裡? → 這種問句類型問的是地名、國家名等等。
(3)飛機什麼時候起飛? → 這種問句類型的答案是個確定的日期或時刻。
(4)台灣使用客語的人口有多少? → 這種問句類型的答案是數量、比例、金額、長寬大小等度量衡數值。
(5)怎樣增加鈣的吸收? → 這種問句類型問的是解決的方法,或事情的做法。
(6)誰是畢卡索? → 這種問句類型問的是特定人士、特定組織、甚至是特定物品。
(7)何以會「先天性髖關節脫臼」? →使用者問的是事情的起因、原由等。
(8)申請HiNet連線應先有哪些基本配備? → 答案包括一個以上的物件、設備等。
自然語言處理的挑戰與未來趨勢
自然語言處理一直是人工智慧研究重要領域之一,如何讓電腦分析與生成人類語言,讓電腦與使用者以人的語言溝通是電腦科學終極目標之一。基本的自然語言處理技術,包括段落切分、斷句、片語切分、斷詞、具名實體擷取、詞性標記、語意標記、相互參考分析等。其中部分技術有不錯的效能,並已成功地應用到資訊的擷取上。在著名的訊息理解技術評比所開發出來的英文具名實體擷取技術上,包括人名、地名、組織名、時間、日期、錢、百分號等文件重要成分,系統效能普遍已達90%以上。具名實體是文件的主要成份,掌握具名實體是理解文件基本工作。
目前應用於搜尋引擎的自然語言處理技術,仍然很有限。以中文斷詞為例,採用的功能僅侷限於查詞處理。預期更精確、及更快速的斷詞技術將會被引進,以提升檢索準確度。另外,建構於搜尋引擎之上的開放領域自動問答系統,僅由回傳的摘要中找尋答案會有漏網之魚之慮。如果到相關網站進一步取得完整網頁的資訊,雖然可避免遺漏,但是收集網頁資訊對回應時間的影響是個問題。基於企業內部資訊的自動問答系統,可掌握所有資料,上述問題相對較不嚴重,但是增強問句處理的類型,是另一個要面對的挑戰。
跨足生物科技領域應用
除了一般文件,如網頁、新聞報導...之外,搜尋技術也可延伸到熱門的生物科技。由於生物科技的快速發展,大量新的研發成果不斷地發表,掌握最新的理論和技術,開創新的研發成果,是生物科技一大挑戰。基本上科技論文是以人的語言(如英文)所書寫的文件,而自然語言處理技術就是處理文件的利器。運用自然語言處理技術,自動分析生物科技論文,儼然成為生物資訊重要的研發項目之一。除了以搜尋技術找尋相關的科技文章外,由科技文章中辨識蛋白質名稱、基因名稱、細胞名稱、疾病名稱、和藥物名稱,嘗試找出其間的特定關係,交由實驗室進一步驗證,成為自然語言處理技術新的應用。(作者為國立台灣大學資訊工程學系教授兼系主任)