簡介
當快閃記憶體仍然在嵌入式系統的儲存裝置上佔有一席之地的同時,它的應用已超出其原本的設計。近年來,它已經成為許多系統設計中重要的一環,其中著名的例子有英特爾提出使用快閃記憶體來當作硬碟快取記憶體的架構,還有微軟提出Windows Vista系統的快速開機服務 [1, 6, 9],此類的應用對快閃記憶體的使用壽命及可靠性造成極大的挑戰;更甚者,在低價快閃記憶體市場日益擴大的趨勢之下,對快閃記憶體可靠性所造成的衝擊是更加嚴重。例如:傳統的SLC (Single-Level Cell,代表每個儲存資料的單位可存一個位元的資料) 快閃記憶體的每個區塊可被抹除的限制為100,000次,而現在的MLCx2 (Multi-Level Cell,代表每個儲存資料的單位可儲存兩個位元的資料) 快閃記憶體的每個區塊的抹除限制降至10,000次,未來隨著每個 Cell可存放的位元數的增加,快閃記憶體的使用壽命將勢必減短。這樣的觀察點出了快閃記體上資料可靠性的問題。然而,在實用及市場上不太可能接受大幅提高系統硬體效能及成本的做法,因此提出並研發一個既省主記憶體又能與當前系統相容的方法來有效提昇快閃記憶體壽命的方法實為一重要的課題。
一個NAND型快閃記憶體晶片含多個區塊,每個區塊包含多個頁面,一個區塊是抹除動作的最小單位,而讀寫的最小單位是一個頁面。大區塊的SLC快閃記憶體中,每個頁面(page)通常包含2KB的空間外加64B額外空間,而每個區塊(block)包含64個頁面;小區塊的SLC快閃記憶體中,每個頁面通常包含512B的空間外加16B的額外空間,而每個區塊包含32頁面。另外,MLCx2快閃記憶體,每個頁面通常包含2KB的資料外加64B的額外空間,而每個區塊包含 128 個頁面。通常快閃記憶體會被一個「區塊裝置轉換層」所管理,著名的管理方法有Flash Translation Layer協定 (FTL)及NAND Flash Translation Layer (NFTL)協定,這樣的管理層通常是由主機上的軟體來實作,或是實作在裝置內部以硬體或韌體的形式存在。在過去的研究中,有許多關於快閃記憶體的傑出研究或實作,它們主要是用來提升快閃記憶體的讀寫效能 [2, 3, 4, 5, 11, 12, 17, 18],另外有一些則是研究快閃記憶體可以被應用的其它層面,例如:大容量的儲存系統及資料壓縮 [11, 17, 18]。
因為快閃記憶體每個頁面被寫入資料之後就不能再被修改,除非被抹除之後才能夠再寫入新的資料,因此具有「外部更新」(out-place updates)的特性,也就是要被更新的資料必須要寫在另外一處尚未被寫過資料或剛被抹除的頁面之中,而原來儲存舊資料的頁面就要被標示為「過期」(invalid)的資料,而外部更新的特性引發了快閃記憶體的平均抹除議題,因為任何過期頁面的回收都會引發區塊抹除的動作,而平均抹除是用來使區塊抹除的分佈較為平均,使得每個區塊被抹出的次數一樣或較為平均,這樣可以延長快閃記憶體的使用壽命。以這個方式為目標,許多不同的動態平均抹除方法被提出來,例如 [7, 10, 11],但是動態平均抹除方法通常會試著去抹除有效資料較少的區塊。這樣的方法需高效率的的方法來分辨 經常被更新的資料(hot data),也因此有許多方法被提出,例如:[11, 13, 14, 15]。僅管動態平均抹除可以大幅改善記憶體的平均抹除程度,但是對記憶體壽命的延長仍受到極大的限制,這是因為存放不常被更新的資料(cold data)的區塊通常不會被選來做抹除,最後使得部分區塊被抹除的次數特別少。相反的,靜態平均抹除和動態平均抹除方法不同,它會試著去抹除記憶體中的任何區塊,使得沒有任何資料能存在任何一個地方太久。
僅管靜態平均抹除對記憶體壽命能有大幅的提昇,但是非常少的研究著重在這個議題之上 (除了如[7, 16]等產品上有提到這個議題之外),因此我們提出一個靜態平均抹除的機制來提昇快閃記憶體的使用壽命,並且只使用非常少量的主記憶體及增加非常少量的系統負荷;其中,一個管理的資料結構及一個佇列式檢視的程序被提出來達成靜態平均抹除的目的,並且能與現行的管理機制(FTL及NFTL)相容。這個機制的行為及特性亦被詳細地驗證過,諸如主記憶體需求、額外的區塊抹除及額外的有效頁面資料複製。我們做了一系列的實驗來證明我們所提出的論點,依據實驗結果,我們所提出的方法在第一次區塊損壞的發生時間為考量的話,搭配FTL管理的快閃記憶體壽命可提升51.2%,且可以提升使用NFTL的快閃記憶體壽命高達 87.5%。
系統架構
常用的系統架構

| 《圖一 常用檔案系統所使用的系統架構》 - BigPic:574x524 |
|
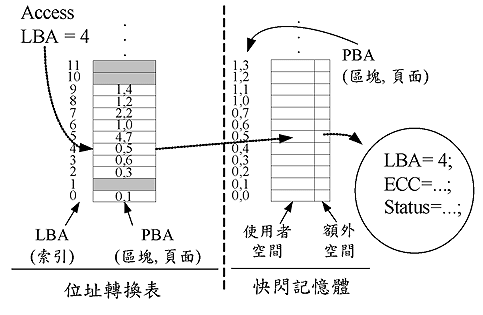
如(圖一)所示為一個常用檔案系統所使用的系統架構,其中包含一個MTD (記憶體技術裝置、Memory Technology Device)驅動程式用來提供基本的函數及功能,如讀、寫、抹除等基本功用的函數,另外包含一個「快閃記憶體轉換層」,是用來做記憶體管理及區塊回收,而 FTL及NFTL就是這一層的管理機制。在這一層中,記憶體管理是用來做位址轉換,也就是來自上層的LBA (邏輯區塊位址、Logical Block Address)與下層實體記憶體的PBA (實體區塊位址、Physical Block Address)之間做轉換,而不同的方法採用不同的方式來管理LBA與PBA之間的轉換。區塊回收單元則是用來回收存有過期資料的頁面,但因為資料抹除的單位是以區塊為單位,因此需要先把區塊內的有效資料複製到其他地方,然後再將整個區塊抹除,而選擇被被抹除區塊的方法直接影響到記憶體壽命,因此突顯平均抹除技術的重要性。
現在快閃記憶體轉換層的重要實作
FTL [2, 3, 5] 採用「頁面單位」的管理機制,也就是每個實體頁面都會有一個相對映LBA 與PBA之間的轉換資訊,(圖二)的表格中所記的資訊就屬於這一類的位址轉換,例如LBA4實際上是被儲存在實體的「區塊0」中的「頁面5」,也就是PBA=(0,5)的地方,其中LBA是作業系統所管理的頁面(或區段)位址。當有任何資料被更新時,FTL必須找一個空的頁面來存放新的資料。當空頁面不足時,區塊回收單元會被啟動來回收儲存過期資料的頁面的空間,這樣的動作必須要抹除該頁面所在的整個區塊,所以該資料所在區塊內的其他有效資料必須複製到其他地方,然後再進行抹除,同時位址轉換表的內容亦需更新。
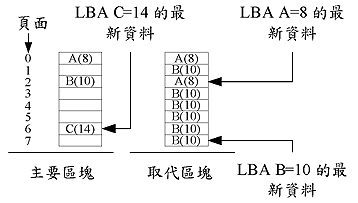
NFTL使用「區塊單位」的管理機制,也就是每個區塊才有一個位址轉換的資訊。在此機制之中,每一個LBA被分為VBA(虛擬區塊位址、Virtual Block Address)及區塊offset (也就是「LBA」除以「一個區塊內可存LBA個數」的餘數),一個VBA會依據位址轉換表內的資料找到它的實體區塊。每當一個寫入要求到來時,寫入資料的內容會被寫到該實體區塊內相對 offset 的頁面之中,當第二次寫入資料到同一個頁面時,因為頁面已寫有資料不可被覆寫,所以資料不會寫入這個主要區塊(primary block),而會寫到一個相對映的取代區塊(replacement block),並且是寫到取代區塊中的第一個空頁面。如(圖三)所示,假設有三個LBA分別為LBA A=8、LBA B=10及LBA C=14,且分別被寫入3次、7次及1次,它們最新資料的所在位置如(圖三)所示。
高效率靜態平均抹除機制
概要
靜態平均抹除是為了要防止任何資料留在任意一個區塊內太久,也就是要縮小任兩個區塊的抹除次數的差別。這此論文之中,我們考量一個模組化設計的架構,因此可以輕易地整合進許多現行的管理機制之中。如(圖一)所示,我們提出的架構就是將高效率靜態平均抹除機制變成一個嵌入快閃記憶體轉換層中的一個模組,它會啟動區塊抹除模組去抹除高效率靜態平均抹除機制所指定的區塊。
高效率靜態平均抹除機制中有一個BET (區塊抹除表、Block Erasing Table),是用來記錄在一段時間區間之內區塊被抹除的分佈情況。高效率靜態平均抹除機制是經由一些系統參數來決定啟動的時機,當它被啟動之後會重設BET內的所有資訊或是依據BET內所紀載的資訊來選取要回收的區塊(組),並利用啟動區塊回收單元來完成有效頁面資料的搬移及區塊抹除的動作。其中選擇回收區塊必須要非常有效率,且每當一個區塊被抹除時,BET的內容必須要正確地被更新。因為快閃記憶體的容量快速增大及控制器上容量有限的RAM (隨機存取記憶體),所以BET 的設計必須要具有可擴充性。此外,高效率靜態平均抹除機制可以是一個執行緒或程序,可以透過記憶體管理機制來觸發執行。
區塊抹除表(BET)
BET的目的是用來記錄在一個預設的時間範圍內的區塊抹除情形,用以偵測存放不常更新資料的區塊之所在,這個預設的時間範圍稱為「重置區間」(resetting interval)。BET是一個位元陣列 (bit array),每個位元為一個旗標,每個旗標對映到連續2k個區塊,其中k為一個0或大於0的整數。一開始時,BET內的所有旗標都被設為0,每當區塊回收單元抹除一個區塊時,靜態平均抹除機制會被啟動來將該被抹除區塊相對映的旗標設為1。如(圖四)所示,資料的維護分為一對一以及一對多兩種模式。當k=0時,一個旗標對映到一個區塊 (一對一模式),當 k>0時為一對多模式。當k的值越大,則有越高的機率會忽略掉一些存放不常被更新資料的區塊,然而它可以降低BET對記憶體的需求量。
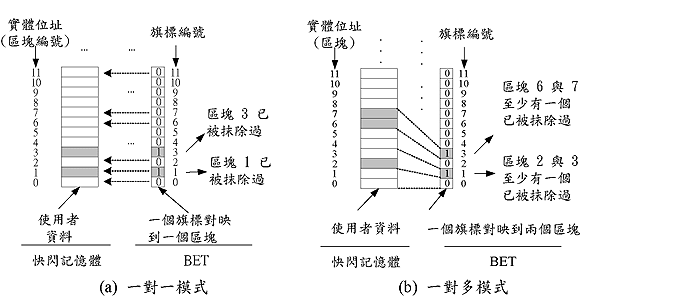
| 《圖四 旗標與區塊的對映機制》 - BigPic:680x300 |
|
最壞狀況出現在當k值很大且經常更新與不常更新的資料存在同一個區塊組 (一個區塊組就是被同一個旗標所對映到的一組連續區塊) 裏,幸運的是:這樣的情況會隨著時間自然地解決,原因是當頁面所存放的資料是經常更新的資料,則該頁面所存的資料很快就會過期,結果不常更新的資料最後還是會被率靜態平均抹除程序要求搬到其他地方。技術上的問題是依據解決此狀況所需的時間(偏好小的k值)及可用的RAM的空間 (偏好大的k值)。另一個技術問題是當系統啟動時,重建BET所需的時間,一個簡單有效方法是在系統關機時,將BET存放在快閃記憶體內,並且在系統重新啟動時重新載入BET。如果系統沒有正常關機,我們可以載入任何現存BET的正確版本,只要不常發生系統不正常關機的情況,這樣的解決方法相當合理,原因是我們只損失少量的抹除記錄,並不會影響整體的效能。值得一提的是BET對抗系統當機的方法可以用雙重暫存區(dual buffer)的概念來解決BET內容流失的問題,同時此方法不需要讀取頁面的額外空間來重建BET,是有效率且可以應用到未來大容量的快閃記憶體上。
因為每一個區塊組只需要一個位元,所以整個BET所需要的記憶體空間很小。如表一所示,BET 的大小依據快閃記憶體的大小及k值的大小而定。舉例而言,一個4GB SLC大區塊的快閃記憶體需要512B來存放BET。當然,如果使用MLC快閃記憶體的話,BET的大小就會更小。
(表一) SLC快閃記憶體的BET大小
|
128MB |
256MB |
512MB |
1GB |
2GB |
4GB |
k = 0 |
128B |
256B |
512B |
1024B |
2048B |
4096B |
k = 1 |
64B |
128B |
256B |
512B |
1024B |
2048B |
k = 2 |
32B |
64B |
128B |
256B |
512B |
1024B |
k = 3 |
16B |
32B |
64B |
128B |
256B |
512B |
靜態平均抹除機制
靜態平均抹除機制包含BET及兩個子程序SWL-Procedure及SWL-BETUpdate (參見圖五及圖六)來達成靜態平均抹除的目的。每當區塊回收單元抹除一個區塊,它就會呼叫SWL-BETUpdate,並依新被抹除的區塊來更新BET。SWL-Procedure是當需要做靜態平均抹除的時候才會被呼叫,而呼叫的時機是經由fcnt及ecnt等兩個變數所決定,其中fcnt表示BET中被設定的旗標個數,ecnt表示自從上次BET被重置之後抹除區塊的總次數。當fcnt/ ecnt的值 (我們稱為「不均勻程度」(unevenless level) )大於或等於所設定的門檻值T時,SWL-Procedure就會被啟動來檢查BET,從中找出一些很久沒有被抹除過的區塊,並要求區塊回收單元將這些被選上的區塊抹除並回收,這樣一來不常被更新的資料就會被強迫存放到別的地方去。值得一提的是:不均勻程度越高,表示越多的區塊抹除都集中在小部分的快閃記憶體區塊中。
(圖五)是SWL-Procedure的演算法:如果BET才剛被重設過的的話,fcnt會等於零,因此 SWL-Procedure就會直接返回(步驟1)。當不均勻程度大於或等於預設的門檻值T時,區塊回收單元在每一個迴圈中都會被呼叫起來抹除所選定的一組區塊(步驟2-15)。在每一個迴圈的一開始都會先檢查是否BET內的所有旗標都已被設定(步驟3);如果是的話,就會把BET內的所有旗標都重設為0,並將其他參數都清為0 (步驟4-7),值得一提的是:findex是在做靜態平均抹除時用來指出被選到的區塊組,並且每次重設時它都會被隨機的設定指到任意的一個區塊組。在BET及其它參數都重設後,SWL-Procedure就會返回以開始下一個重設區間(步驟8),否則選取指標findex就會移動到下一個尚未被設定的旗標以找到很久都沒被抹除過的區塊組(步驟10-12),值得注意的是:循序掃描每一個區塊組在實作上是非常快速且有效的做法,因為我們發現不常被更新的資料可能被存在快閃記憶體中的任意區塊中,所以循序找一個尚未被抹除過的區塊組與隨機找是一樣的效果。SWL-Procedure接著會呼叫區塊回收單元來將所選中的區塊組(findex所指的旗標所對映的區塊組)抹除(步驟13),然後移動到下一個旗標(步驟14)。我們必須指出來的是:因為SWL-BETUpdate會在區塊回收單元抹除一個區塊後被呼叫,因此fcnt和 BET都會自動被正確地更新。這個迴圈一會直執行到不均勻程度降到比預設的門檻值還低為止。

| 《圖五 演算法之一》 - BigPic:592x505 |
|
SWL-BETUpdate的演算法如圖六所示:給定被區塊回收單元所抹除的區塊的位址 bindex,SWL-BETUpdate首先將被抹除的區塊總數加1 (步驟1),如果該區塊所對映的旗標尚未被設定的話,就會把該旗標設定,並且將被設定的旗標總數值加1 (步驟2-4)。

| 《圖六 演算法之二》 - BigPic:592x255 |
|
最後的技術問題是如何維護 ecnt、fcnt及findex的值。為了讓靜態平均抹除能得到較好的效果,這些變數的值必須儲存在快閃記憶體之中,但是我們必須指出:這些值是可以忍受錯誤的,也就是如果這些值尚未被寫入快閃記憶體中,系統就當機的話,我們可以在下一次開機時直接載入上次存在快閃記憶體中的舊值,因為失去小段時間的區塊抹除狀況的記錄並不影響靜態平均抹除的效能。
效能評估
實驗設定
本文的目的是為了評估我們所提出的平均抹除機制在FTL及NFTL上的效能,尤其是使用壽命及此機制所帶來的額外負荷。使用壽命基於「第一次發生區塊損壞」來做分析評量;而額外負荷是利用「額外區塊抹除」及「額外頁面複製」來做評量。
為了使比較具公平性,無論有沒有加入我們所提出的平均抹除機制,都同樣在FTL及NFTL中使用greedy的方法:也就是在選擇一個即將被抹除的區塊時,如果區塊中有一個頁面裏所存的是有效資料,那麼就會增加一個單位的抹除負荷,如果有一個頁面裏所存的是過期資料,則就會增加一個單位的利益;當一個被檢視的區塊內的總頁面利益大於總頁面負荷時,就會被區塊回收單元所抹除,而區塊回收單元在整個系統中閒置區塊量低於總區塊量0.2%時,就會被啟動來進行區塊抹除,以回收一些儲存過期資料的空間。值得注意的是:當NFTL的一個取代區塊要被抹除時,NFTL會將取代區塊及其相對映的主要區塊內的有效資料合併到另一個區塊中,並同時把這兩個區塊一起抹除。
實驗中,我們使1GB MLCx2的快閃記憶體(每個區塊128個頁面,每個頁面可存放2KB的資料)為對象,雖然FTL及NFTL的原始設計都不能使用在MLC快閃記憶體上,但是只需要小修正就可以管理 MLC快閃記憶體,因此不是一個大問題。這1GB的快閃記憶體最多可以存放 2,097,152個LBA的資料。另外,實驗中所使用的資料存取記錄是蒐集一台裝配有20GB硬碟的筆記型電腦上一個月的硬碟存取記錄而來的,而這台電腦在蒐集期間主要是用在瀏灠器的使用、電影片的下載及播放、電腦遊戲的執行及文件編輯。在此存取記錄中約有36.62%的LBA有被寫過,而平均每秒鐘的寫入次數為1.82次、讀取次數為1.97次,但只有存取前2,097,152個LBA的資料才會被使用在實驗中。為了使快閃記憶體發生第一次區塊損壞,所以我們隨機從蒐集到的存取記錄中選擇一個10鐘長度的存取記錄的片段,且每個被取過的段斷還是有機會被重取,這樣就可以產生一個虛擬的無限長度存取記錄。
使用壽命的延長
(圖七)顯示我們所提出的靜態均勻抹除機制搭配FTL或NFTL時皆可大幅延緩第一次區塊損壞的時間;換句話說,也就是可以大幅延長快閃記憶體的使用壽命並提高可靠性。圖中的x軸表示k的值,y軸表示的是第一次發生區塊損壞的時間(以年為單位)。舉例來說:當T = 100且k=0時,靜態均勻抹除機制搭配FTL可以提升快閃記憶體51.2%的使用壽命,而搭配NFTL時可以提升87.5%的使用壽命。一般而言,小的T及k值搭配NFTL可以有比較好的效能,因為T影響靜態均勻抹除機制被啟動的頻率,而k影響BET對不常更新資料的辨識力。
有趣的是當靜態平均抹除機制搭配FTL時,反而是當T小一點但k大一點時的表現比較好,原因是因為FTL是頁面單位的位址轉換機制,當k值大一點的時候,靜態平均抹除機制一次要求區塊回收單元抹除的區塊比較多,也就是一次會搬移比較多的(靜態)資料,反而把經常更新與不常更新的資料分離的更清楚,這使得存放經常更新資料的區塊會更快被損壞。值得一提的是:雖然FTL發生第一次區塊損壞的時間比較慢,但是在大容量的快閃記憶體的應用上是不實際的,因為每個頁面都需要一個位址轉換,因此需要非常大容量的RAM來維護位址轉換表。

| 《圖七 第一次區塊損壞的時間》 - BigPic:852x320 |
|
額外負荷
(圖八)顯示的是所提出的靜態均勻抹除機制搭配FTL或NFTL時所增加的區塊抹除比例。一般而言,當T大一點(啟動頻率降低)及k值大一點(BET的解析度降低)時,所增加的負荷就會比較小。整體來看,所增加的比例在FTL上都小於3.5%,而在NFTL上都小於1%。

| 《圖八 增加區塊抹除的比例》 - BigPic:872x393 |
|
(圖九)顯示的是所提出的靜態平均抹除機制搭配FTL或NFTL時所增加有效頁面資料複製的比例。在搭配NFTL時,所增加的比率都小於1.5%。但在搭配FT時,所增加的比率就大上很多,這是因為經常更新的資料通常都是大量寫入,導致被選上要回收的區塊大部分都佈滿了過期的資料,即使如此,我們提出的靜態平均抹除機制在抹除一個區塊時,平均需要複製的有效資料頁面數仍然非常小。

| 《圖九 增加有效頁面資料複製的比例》 - BigPic:820x391 |
|
結論
本文點出當快閃記憶體被使用在各種不同的應用時所引發的資料可靠性問題,也就是快閃記憶體的使用壽命。不同於之前動態平均抹除的研究,我們提出一個靜態平均抹除的方法來提升快閃記憶體的使用壽命,且只需要極少量的額外RAM,且幾乎不需要改變原來的快閃記憶體轉換層的設計,就能使用我們所提出來的方法,同時又幾乎不會增加系統負荷。一系列的實驗也證明所提出的方法搭配FTL及NFTL都能對快閃記憶體提高一半以上的使用壽命。
未來,我們會進一步研究快閃記憶體的可靠性問題,尤其是MLC快閃記憶體所引起的新可靠性問題;另外,我們也會研究快閃記憶體被應用在外部裝置上的行為及所引發的問題。
<張原豪先生為國立台灣大學資訊網路與多媒體研究所博士班學生>
<謝仁偉先生為國立台灣大學資訊工程研究所博士,現任國立嘉義大學資訊工程系助理教授。>
<郭大維先生為德州大學奧斯汀分校電腦科學研究所博士,現任國立台灣大學資訊工程學系及研究所教授兼系主任。>
參考文獻
[1] Flash Cache Memory Puts Robson in the Middle. Intel.
[2] Flash File System. US Patent 540,448. In Intel Corporation.
[3] FTL Logger Exchanging Data with FTL Systems. Technical report, Intel Corporation.
[4] Flash-memory Translation Layer for NAND Flash (NFTL). M-Systems, 1998.
[5] Understanding the Flash Translation Layer (FTL) Specification, http://developer.intel.com/. Technical report, Intel Corporation, Dec 1998.
[6] Hybrid Hard Drives with Non-Volatile Flash and Longhorn. Microsoft Corporation, 2005.
[7] Increasing Flash Solid State Disk Reliability. Technical report, SiliconSystems, Apr 2005.
[8] NAND08Gx3C2A 8Gbit Multi-level NAND Flash Memory. STMicroelectronics, 2005.
[9] Windows ReadyDrive and Hybrid Hard Disk Drives, http://www.microsoft.com/whdc/device/storage/hybrid.mspx. Technical report, Microsoft, May 2006.
[10] A. Ban. Wear leveling of static areas in _ash memory. US Patent 6,732,221. M-systems, May 2004.
[11] L.-P. Chang and T.-W. Kuo. An Adaptive Striping Architecture for Flash Memory Storage Systems of Embedded Systems. In IEEE Real-Time and Embedded Technology and Applications Symposium, pages 187.196, 2002.
[12] L.-P. Chang and T.-W. Kuo. An Efficient Management Scheme for Large-Scale Flash-Memory Storage Systems. In ACM Symposium on Applied Computing (SAC), pages 862.868, Mar 2004.
[13] M.-L. Chiang, P. C. H. Lee, and R.-C. Chang. Using data clustering to improve cleaning performance for flash memory. Software: Practice and Experience, 29-3:267.290, May 1999.
[14] J.-W. Hsieh, L.-P. Chang, and T.-W. Kuo. Efficient On-Line Identification of Hot Data for Flash-Memory Management. In Proceedings of the 2005 ACM symposium on Applied computing, pages 838.842, Mar 2005.
[15] J. C. Sheng-Jie Syu. An Active Space Recycling Mechanism for Flash Storage Systems in Real-Time Application Environment. 11th IEEE International Conference on Embedded and Real-Time Computing Systems and Application (RTCSA'05), pages 53.59, 2005.
[16] D. Shmidt. Technical note: Trueffs wear-leveling mechanism (tn-doc-017). Technical report, M-System, 2002.
[17] C.-H. Wu and T.-W. Kuo. An Adaptive Two-Level Management for the Flash Translation Layer in Embedded Systems. In IEEE/ACM 2006 International Conference on Computer-Aided Design (ICCAD), November 2006.
[18] K. S. Yim, H. Bahn, and K. Koh. A Flash Compression Layer for SmartMedia Card Systems. IEEE Transactions on Consumer Electronics, 50(1):192.197, Feburary 2004.