在人類的世界中,我們利用視覺來獲取、處理、分析和理解大量的資訊。一般情況下,視覺就佔據大腦的80%的感官認知影響力。然而,隨著資訊、影像處理元件及技術的進步,我們已經在醫學、工廠、軍事、汽車、相機、航太等領域利用電腦視覺來進行代替人眼的工作。近年更因為結合了巨量資料、雲端運算、以及人工智慧等技術,讓電腦視覺技術更為躍進。
電腦視覺技術架構
隨著資訊科技的進展,利用不同的影像成像設備,如:數位相機、監視器、紅外線感測器等,將所見之影像轉為數位化後(將三維實境轉為二維圖像),電腦視覺 (Computer Vision) 再利用不同的光學、數學、物理學等影像處理 (Image Processing) 技術,將二維圖像的部分資訊推演出三維整體訊息的過程。
電腦視覺最早可於1960年的美國麻省理工學院 (MIT) 的教授Larry Roberts和David Marr教授開始談起,Roberts教授率先開創如何解析三維圖像的研究。1977年後,Marr教授則更進一步談論到電腦視覺的理論框架,從此便開展了電腦視覺的新方法、概念及理論的研究熱潮。
電腦視覺理論框架
隨著Marr提出電腦視覺的理論框架(如圖一)後,許多相關研究也逐漸提出來精進其理論框架。然而,根據過去對電腦視覺的架構描述,電腦視覺理論框架可分為四大階層。分別為:低層次視覺 (Low-Level Vision)、中層次視覺 (Mid-Level Vision)、高層次視覺 (High-Level Vision),及抽象層視覺 (Abstract Level Vision)。
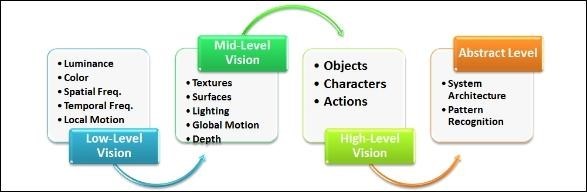
| 圖一 : 電腦視覺理論框架(資料來源:資策會MIC) |
|
低層次視覺
主要針對原始圖像的處理,在此大量運用物理及數學進行基本特徵辨識,包含明亮度(Luminance)、顏色識別(Color)、空間頻率(Spatial Frequency)、時間頻率 (Temporal Frequency)、區域活動偵測(Local Motion)…等等許多技術,藉以找出場景、色彩、邊緣、角度和紋理或基本運動偵測等。
中層次視覺
中層次視覺要求可以恢復2D場景中的深度、物體輪廓的信息,將原本2D場景恢復至2.5D場景的情況,經常使用的技術有紋理(Texture)及表面 (Surfaces)辨識、光源(Lighting)、深淺(Depth)、和全區運動偵測 (Global Motion)(全區運動指整個畫面一起動作,如開車忽然向右轉)。
高層次視覺
高層次視覺主要將物件復原成3D圖的概況,藉此可對3D圖中的人事物進行描述、識別。經常要做的任務就是對物件(Object)、特徵(Characters)以及動作(Actions)的辨別。
抽象層之視覺
開始進行高層次及抽象主題的識別,例如:開始辨識建築物的風格、或是瞭解人類的不同動作和行為模式,經常以系統結構 (System Architecture)和模式辨識(Pattern Recognition) 進行討論。
電腦視覺流程週期及知識架構

| 圖二 : 根據電腦視覺在處理的過程中,其實需要不同的流程才得以成為電腦視覺的產品。(Source:CEVA's Experts blog) |
|
根據電腦視覺在處理的過程中,其實需要不同的流程才得以成為電腦視覺的產品。其中本文在電腦視覺流程中,將電腦視覺的流程週期簡介為四大流程,分別為:影像資訊輸入(Image Input);影像前處理(Image Preprocessing);影像理解(Image Understanding);電腦視覺產品(Results)。以下說明每項流程週期之工作任務、技術以及相關知識領域。
影像資訊輸入
在影像資訊輸入中,最為普遍的就是數位相機以及攝影機,此外,各應用領域也有專業的取像設備,例如光源感測器、紅外線感測器、深度攝影機(Depth Camera)、3D掃描器、核磁共振攝影印(MRI)等。甚至,我們利用滑鼠、繪圖板所繪製的圖像或是掃描器,這些其實都是影像資訊輸入的裝置。因此,在影像輸入階段中,技術重點仍著重在影像相關的光學及成像技術。
影像前處理
影像前處理(Image Preprocessing),又稱影像還原(Image Restoration),主要目的就是利用不同的影像處理技術進行影像失真的還原、雜訊的處理。並且,也同時針對影像進行訊號的前處理,藉此來瞭解影像的光源、角度、邊緣…等。因此,在影像前處理階段中,相對較類似電腦視覺理論框架的低層次及中層次架構,以及部分的高層次視覺處理技術。
然而,在此項流程週期中,許多技術根本是基於數學幾何學、物理學、訊號處理學等。由於上述基礎科技來發展圖像特徵偵測、光源、邊緣、點線面辨別的判斷,藉此來達到影像前處理之目的。
影像理解
影像理解(Image Understanding),其顧名思義,就是要讓系統瞭解影像。技術方面來說,主要著重系統結構(System Architecture)和模式辨識(Pattern Recognition)。在此流程中,為了要能夠辨識及理解不同圖像資料上的內容,則必須要有許多領域知識來進行判斷,其中包含了行為心理學、認知科學、或者是特定領域的學科知識(例如:為了辨識巴洛克風格的建築,必須要有其建築知識的背景)。
除此之外,由於近年運算速度及記憶體的提升,龐大的圖片及影像資料得以有效率地進行分析。因此,在近年的電腦視覺則開始有效的導入認知科學、神經生物學等來協助進行系統結構和模式辨識,以更具備自主性及智慧化。比方來說:利用類神經網路的技術,來辨識道路上的車流情況,藉由收集到的影像資料,以進行路況分析。
電腦視覺應用領域

| 圖三 : 經過影像處理之後,電腦視覺開始能夠做到事件偵測、環境∕物件建模或是定位導航等功能,利用這些影像處理的成果來推出電腦視覺相關的產品。(Source:autor) |
|
在經過影像資訊輸入、影像前處理、影像理解之後,電腦視覺開始能夠做到事件偵測、環境∕物件建模、或是定位導航等功能,利用這些影像處理的成果來推出電腦視覺相關的產品。在過去幾年當中,我們已有相當多電腦視覺的產品推出,而在近年因為大數據及物聯網的發展,電腦視覺的產品更具有許多功能整合性、縮小性、和突破性的方向進行成長。以下我們列舉數項產品進行說明:
功能整合性應用案例--智慧零售、安全監控
在過去,可看到部分公共場合或賣場中的攝錄影機只提供事件分段記錄的功能。而研華電腦於2014年以自家的WebAccess系統為核心,結合影像分析軟體以及自家的影像擷取卡、處理平台等,提出「WebAccess+IVS」作為影像處理的解決方案。
研華電腦提供了如物件統計(Object Counting)、人流統計(People Counting)、攝影機干擾偵測(Camera Tamper)、光學自我診斷(Optical Self Diagnostic)、移動偵測(Motion Detection)、禁區管理(Forbidden Zone)、人口統計變數(Demographic)(如:判別男女、年齡)等影像分析功能。
縮小性應用案例之一--創新手勢控制
日本新創公司Logbar所提出的「Ring」-手勢控制(Gesture Control)戒指,於2014年4月在美國群眾募資平台Kickstarter募資成功。該產品利用戒指中的運動感測器,來瞭解手指所畫出的圖示,藉此瞭解不同象徵性的圖示後,再去執行所相對應的命令。
縮小性應用案例之二--行車防碰撞預警
另外,日前在行車安全中頗具盛名的以色列「Mobileye」公司所提出的主動式「行車防碰撞預警系統」,就以在車子高速及慢速行進間提供對行人/自行車防撞預警、車道偏離、前車防撞預警、交通標誌辨識、以及智慧型遠近光燈切換的功能。這些都依賴著預警系統可以即時處理影像資訊,找出特徵資料並再做出合適的判斷,才得以完成此預警系統。
突破性應用案例之一--主動認知
Google曾經有一項專案名為Google Brain,該專案利用自身開發的深度學習網路來複製人類大腦思考方式,並在利用電腦視覺技術「觀看」了千萬個Youtube影片後,學習到如何分辨「貓」這種動物。這種圖像模式辨識的方式打破了過往所認知的預計規則邏輯,改以讓電腦自行認知去學習何為「貓」的概念。上述的成果,不僅大大突破了原有電腦視覺的框架,也成為人工智慧的一項重要里程牌。
@中標:縮小性應用案例之二--自主遊戲智慧
另外,2014年六月底時,Google花費高達6億美元來併購了一家人工智慧公司「Deepmind」,藉由這次的併購讓全世界觀注到Deepmind這家公司的與眾不同。Deepmind利用所研發的人工智慧來達到「看懂」過去的電腦遊戲來怎麼玩才可以得到高分。並且驚人的是,Deepmind並不需要為每一款遊戲去設定判斷規則或是遊戲怎麼玩,在只需設定目標後,命令Deepmind自行學習來獲得高分。
電腦視覺成為主要公司角力之地
電腦視覺是資訊產品,從被動判斷拓展到主動識別過程中的重要技術,過去,一般認為的電腦視覺大多用於專屬特定領域,如人臉辨識、交通號誌判斷等。不過,由於電腦視覺可開始整合認知科學、類神經網路、深度學習等多元人工智慧相關技術的成熟,開始逐漸走向可以廣泛的對不同人事物或更甚至是行為模式的情況進行判定,使得未來不論在生活各層面、商業分析、監控管理皆有劇烈的影響。
2014年國際大廠積極收購具圖形處理、電腦視覺技術能力的公司,幫助其在電子商務、資料搜尋、社群經營等應用的技術累積。在巨量資料技術對非結構性資料的處理能力不斷進步,未來電腦視覺的處理效率,將成為主要公司的重要競爭要素。
(本文作者為資策會MIC產業分析師)
**刊頭圖片來源(Source:startyourspark)




