1989年科幻電影「親愛的,我把孩子縮小了」,2015年「蟻人」,2017年「縮小人生」,以及我們從小看到大的多啦A夢「縮小燈」、「縮小隧道」,都不約而同的提到一個概念,就是可以透過一種神奇的機器,就能把人的體積大幅縮小但生理機能完全不減。這裡姑且不論是否符合物理定律,但如果真的能實現,就會像「縮小人生」中所提到的,可大幅減少地球資源的浪費,大幅改善人類的生存環境。雖然以上提及的技術可能我們這輩子都難以看到實現的一天,但把超巨大的AI模型縮小但仍保持推論精度不變,還是有很多方法可以達到的。接下來我們就來幫大家簡單介紹一下幾種常見技術。
1. AI模型組成元素
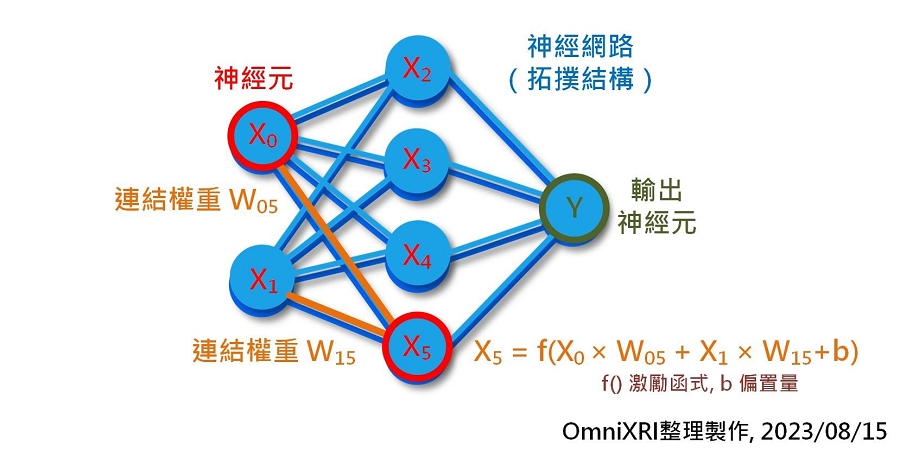
回顧一下本專欄三月份文章[1]第1小節提及的神經網路架構,其組成內容主要包括神經元內容(包含數量)、網路結構(神經元連接拓撲)及每個連結的權重值,如Fig. 2所示。簡單的卷積神經網路(CNN)如LeNet-5,就有約6萬個權重,而大型模型VGG16則有約1.38億個權重,到了現在流行的大型語言模型GPT-3已激激增到1750億個權重,更不要說像GPT-4已有超過一兆個權重。
通常在訓練模型時為了精度,權重值大多會使用32位元浮點數(FP32)表示法[2],這就代表了每個權重佔用了4個Byte(32bit)的儲存(硬碟)和計算(隨機記憶體)空間。這還不包括在推論計算過程中額外所需的臨時隨機記憶體需求。
為了讓運行時減少資料(網路結構描述及權重值)在CPU和AI加速計算單元(如GPU, NPU等)間搬移的次數,所以通常會一口氣把所有資料都都載入專用記憶體中,但一般配置的記憶體數量都不會太多,大約1GB到16GB不等,所以如果沒有經過一些減量或壓縮處理,則很難一口氣全部載入。
2.常見壓縮及減量作法
如同前面提到的,我們希望將一個強大複雜的AI模型減量、壓縮後,得到一個迷你、簡單的模型,但仍要能維持原有的推論精度或者只有些微(0%到指定%)的下降,就像我們平常看到的JPG影像、MP4影片,雖然採大幅度破壞性壓縮,但人眼是很難分辨其品質差異的。這樣可以得到幾項好處,包括大幅減少儲存空間和計算用記憶體,推論速度加快,耗能降低,同時更有機會使用較低計算能力的硬體(如GPU變成CPU)來完成推論工作。以下就把常見的四種方式簡單介紹給大家。
2.1 權重值量化(Quantization)
通常在訓練模型時,為求權重有較寬廣的數值動態範圍,所以大部份會採用32位元浮點數(FP32, 符號1 bit,指數8 bit,小數23 bit,共4 Byte,數值表示範圍±1.18e-38 ~ ±3.40e38)[2]。而經許多資料科學家實驗後,發現在推論時將數值精度降至16位元浮點數(FP16, 2 Byte, -32,768 ~ +32767),甚至8位元整數(INT8, 1 Byte, -128 ~ +127)、8位元浮點數(FP8, e5m2, e4m3, 1 Byte)在推論時其精度下降幅度可控制在一定程度內,同時可讓儲存空間和記憶體使用量減少1/2到3/4,若加上有支援SIMD或平行運算指令集[1]還可讓運算量提升1.x ~ 3.x倍,一舉多得。
以FP32量化為INT8為例,一般最簡單的作法就是把所有空間等比對稱分割再映射,不過當遇到權重值分配往單邊靠或集中在某個區間時就很難分別出細部差異。於是就有以最大值與最小值非對稱方式來重新映射,以解決上述問題。
這樣的量化減量的方式最為簡單,但也常遇到模型所有層用同一數值精度後推論精度下降太多,於是開始有人採混合精度,即不同層的權重可能採不同數值精度(如FP32, FP16, INT8等)來進行量化。不過這樣的處理方式較為複雜,通常需要一些自動化工具來協助。
2.2 模型剪枝(Pruning)
所謂樹大必有枯枝,模型大了自然有很多連結(權重)是沒有存在必要的或者是刪除後只產生非常輕微的影響。如果要透過人為方式來調整(刪除、合併)數以百萬到千萬的連結勢必不可能,此時就只能透過相關程式(如Intel OpenVINO, Nvidia TensorRT, Google TensorFlow Lite等)使用複雜的數學來協助完成。
經過剪枝後,計算量會明顯下降,但可以減少多少則會根據模型複雜度及訓練的權重值分佈狀況會有很大差異,可能從數%到數十%不等,甚至運氣好有可能達到減量90%以上。
另外由於剪枝後會造成模型結構(拓撲)變成很不完整,無法連續讀取,所以需要另外增加一些描述資訊。不過相對權重值佔用的儲存空間,這些多出來的部份只不過是九牛一毛,不需要太過在意。
2.3 權重共享(Weight Share)
由於權重值大多是由浮點數表示,所以若能將近似值進行群聚(合併),用較少的數量來表達,再使用查表法來映射,如此也是一個不錯的作法。但缺點是這樣的作法會增加一些對照表,增加推論時額外的查表工作,且由於和原數值有些微差異,因此會損失一些推論精度。
如圖4所示,即是將16個權重先聚類成4個權重(索引值),再將原本的權重值變成索引號,等要計算時再取回權重值,這樣儲存空間就降到原本的1/4。
2.4 知識蒸餾(Knowledge Distillation)
知識蒸餾基本上不是直接壓縮模型,而是利用一個小模型去學習大模型輸出的結果,間接減少模型的複雜度、權重數量及計算量。大模型就像老師,學富五車,經過巨量資料集的訓練,擁有數百萬甚至千億個權重來幫忙記住各種特徵。而小模型就學生,上課時間有限,只能把老師教過的習題熟練於心,但若遇到老師沒教過的,此時是否能舉一反三,順利答題就很難保證了。
如圖5所示,訓練學生模型時,將同一筆資料輸入到老師模型和學生模型中,再將老師的輸出變成學生的標準答案,學生模型再以此調整所有權重,使輸出推論結果和老師一樣即可。當給予足夠多及足夠多樣的樣本訓練後,學生就能結束課程,獨當一面了。
小結
以上僅是簡單介紹了部份減量及壓縮模型的方式,還不包含模型減量、壓縮後造成的精度下降如何調整。這些工作相當複雜,只能交給專業的工具來辦,其中 Intel OpenVINO Toolkit 就有提供許多模型優化(Model Optimization)[4]及神經網路壓縮工具 NNCF (Neural Network Compression Framework)[5],有興趣的朋友可以自行了解一下,下次有機會再為大家做更進一步介紹。
(本文由VMAKER授權轉載;連結原文網址)
參考文獻
[1] 許哲豪,【vMaker Edge AI專欄 #03 】 AI晶片發展歷史及最新趨勢
https://omnixri.blogspot.com/2023/03/vmaker-edge-ai-03-ai.html
[2] 許哲豪,【vMaker EDGE AI專欄 #02】 要玩AI前,先來認識數字系統
https://omnixri.blogspot.com/2023/02/vmaker-edge-ai-02-ai.html
[3] 許哲豪,NTUST Edge AI Ch6-3 模型優化與佈署─模型推論優化
https://omnixri.blogspot.com/p/ntust-edge-ai-ch6-3.html
[4] Intel, OpenVINO Toolkit – Model Optimization Guide
https://docs.openvino.ai/2023.0/openvino_docs_model_optimization_guide.html
[5] Intel, Github – openvinotoolkit / nncf – Neural Network Compression Framework (NNCF)
https://github.com/openvinotoolkit/nncf
延伸閱讀
[A] 許哲豪,【Intel OpenVINO ?教學】小孩才作選擇,AI推論速度及準確度我全都要─OpenVINO Post-Training Optimization Tool簡介
https://omnixri.blogspot.com/2021/04/intel-openvinoaiopenvino-post-training.html


![圖2 : 權重值量化示意圖[3]。](/art/2023/08/301748579690/p2.jpg)
![圖3 : 模型剪枝示意圖[3]。](/art/2023/08/301748579690/p3.jpg)
![圖4 : 權重共享壓縮示意圖[3]。](/art/2023/08/301748579690/p4.jpg)
![圖5 : 知識蒸餾示意圖[3]。](/art/2023/08/301748579690/p5.jpg)

