AMR语音编解码器之运算复杂性──MIPS
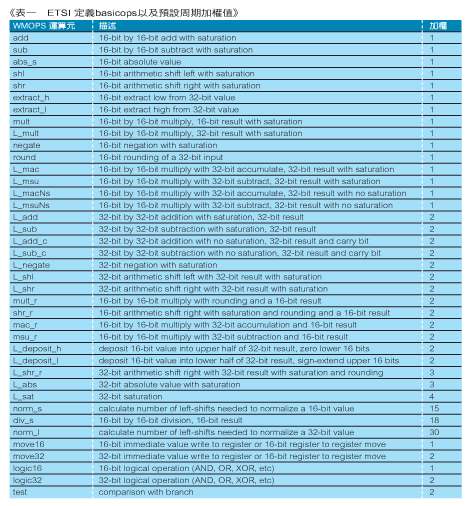
AMR语音编解码器的MIPS是经由WMOPS(Weighted Millions of Operations Per Second)的使用来估计的,这个是由ETSI所开发的方法,用来计算资料存取时,基本的数学与逻辑上的运算并对整个运算数目进行加权,用来反映出一颗DSP上预期的效能。 WMOPS是用来预估MIPS的良好惯例,因为它们能够随着处理器架构改变而有所适应,或者若已知道执行某一特定运算将耗费多少周期时,系统架构能够随之微调。(表一)列出 WMOPS 运作(通常是指 basicos) 和它们在AMR语音编解码器参考程式码时的原始预设加权:
| 《表一 ETSI 定义basicops以及默认周期加权值》 |
|
这个表显示一个周期的期望数目,以执行一个特定的运算。例如,一个32位元的绝对值(L_abs)被期望花费三个周期并增加一个16位元到饱和状态(saturation)(add),并预计花费一个周期。经由AMR语音编解码器所执行的一个测试向量,一个基础线(baseline)的WMOPS(以及接下来的MIPS)值会被决定。整个供AMR语音编解码器的WMOPS是以4.75kbps 的模式运作,其中约有10.7是供编码器所用而有2.0是供解码器之用。当然,如果目标处理器以较慢或较快的速度来执行任何前述的运算,则加权表格必须要跟着调整,以提供更好的总体WMOPS估计值。
应该注意的是,这个WMOPS数字没有考虑到一个目标处理器在架构上的任何限制,例如一个有限的暂存器组合或深层的管线(deep pipelines)或是如果处理器的运算单元没办法以一个准确的位元形式来处理这些运算,这些都将在模拟必要活动时,导致额外的周期时间。此外,这些测试没有考虑到从运算的计算过程当中取得资料所可能产生的限制或额外增加的周期时间。参考程式码假设当资料取得(data fetch)是由于数学运算的需求时,能够在不增加额外周期时间的情况下被负载。这样的假设很可能是不真实的,其主要原因有二:因为处理器并没有支持所有来自数学运算所需资料的模拟负载,或者是因为被负载的变数是被放置在一个非零的等待状态的记忆体。然而,WMOPS 值对于决定一个处理器上特定运算的绝对最佳可能效果,是一个很有价值的指标。
AMR语音编解码器的运算复杂性──记忆体
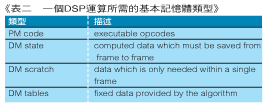
当我们在对此一性质的嵌入式系统进行编码时,很重要的是把整个记忆体使用分散成许多PM(program memory;程式记忆体)和DM(data memory;资料记忆体)这些类别及其简述,如(表二)所示:
DM的状态可以在Speech_Encode_FrameState a和nd Speech_Decode_amrState的结构定义上被发现。这些结构必须在每个讯框中保留它们的值且被放置在读取/写入(R/W)记忆体上。编码器需要2744个状态位元(假设它正在使用VAD1)且解码器需要1628个状态位元。
在AMR参考程式码中,DM散布通常发生在堆叠中。当这个在PC应用上可能是经常且常态的发生时,在嵌入式系统上,减少以堆叠为基础的散布并透过其他的方法来进行配置也是相当常见的。在将AMR语音编解码器移植到目标硬体的部分,将会有详细的描述。
在AMR参考程式码上能够发现DM表格散布在许多C档案上。在AMR语音编解码器所使用的整个表格的总数是14729个16位元的字元。这个资料只能被读取且能够散布在内部DSP记忆体和外部系统记忆体。
执行AMR语音编解码器的取舍和考虑因素
当在对一个语音编解码器(或任何运算)进行移植或编码时,考虑用来执行该运算的整个系统,以及处理器和应用上的需求是很重要的一件事。这些限制可能来自DSP/系统架构和终端应用上的需求,并使得整个移植过程更复杂。在这个范例当中,工程师利用ETSI所提供,最初是针对一个ARM处理器所开发参考程式码。 ETSI提供一个完整的ARM语音解码器和编码器,以及解释程式码如何运作的文件。
MIPS v.s.记忆体使用
决定可允许的运算执行时间和整个记忆体的使用量之间的平衡,是嵌入式程式运算中最重要的取舍之一。如前所述,语音编解码器必须在下一组被安排送达的资料抵达前,即时处理它现有的资料。在上一期,已经讨论了在完全双工装置下,以20ms的时间内,用8MHz进行抽样,来处理160个字元区块的需求。
一般而言,通常是很有可能经由修正一个演算法在记忆体当中的位置,来降低整个MIPS。现在有许多DSP都包含了多阶层的快取记忆体或是针对每个存取而有不同等待状态的多种记忆体类型。 DSP通常也支援那些能够在一个次要的记忆体空间放置资料的方法,以便进行双重的资料存取;在某些DSP架构下,可能是属于程式记忆体的一部分,或者是一个小规模的高速暂存空间。不论如何,在这个部分需要仔细的选择,以确保次要的记忆体空间被有效的使用。在需要两个阵列同时读取和MAC’ed(multiply-accumlated;多重累积)的一个相关或回旋(convolution)功能,是需要利用到次要记忆体典型范例。透过记忆体最佳化用来改善MIPS的方法将会在稍后进一步的详述。
运算上的应用限制
AMR语音编解码器是特别针对无线手机所设计;这隐含着特定的系统限制将能协助设计人员决定基础线(baseline)的运算需求。由于一个行动电话是一次处理一个对话(因此需要语音编解码),这么一来,排除了同时执行多个语音编解码运算请求的需求。代表着AMR语音编解码器被移植且是不允许再次进入(re-entrant)。一个再次进入的运算需要参考所有透过指标器(pointers)所处理的状态和scratch记忆体,而非绝对的记忆体位址。一个直接使用已定址的DM不能够再次进入,因为来自另外一个请求的处理运算已经打断一个请求的scratch和状态记忆体。
如果语音编解码器再次进入(re-entrant),高阶应用程式运算介面(Application Programming Interface;API)功能的呼叫将包含指标器到scratch和状态结构,所有被存取的变数将会被来自此一基础位址(base address)的一种补偿(offsets)。相对于绝对的记忆体存取,ADSP-218x 架构对于以指标器为基础的记忆体存取是比较没有效率的。因此,一个被执行单一AMR的范例版本是同时储存了MIPS和记忆体。
除此之外,因为AMR是在一个无线装置当中执行,为了同时处理多种运算以支援一通电话呼叫(频道编解码、等化器、运算系统、使用者应用等等),其不能使用太多内部的程式或资料记忆体。这表示记忆体分析应该针对所有的变数与阵列来执行,以决定快速记忆体(例如一个位在DSP的内部SRAM)和慢速记忆体(例如外部的快闪记忆体Flash)之间适当的资料分割。执行此一分析所使用的方法,将在下面加以说明。
将参考的AMR语音编解码器C程式码移植到目标硬体上
很明显地,将AMR语音编解码器进行移植的第一步骤是取得参考的C程式码。然而,设计团队必须检查在资料程式码的完成日期之后,是否已经有任何的变更要求被执行并获得批准。有关AMR语音编解码器的变更要求可以在3GPP(3rd Generation Partership Project)网站上找到[1]。包括GSM网路在内,许多使用在第二与第三代无线网路的标准是由3GPP所负责营运与更新的。通常3GPP会提供所有必要变更的解释与原始程式码。
一旦进行了这些更新,参考C程式码就准备好进行修正,以便对嵌入式环境中对特定处理器的独特性提供较好的支援。在此我们将以ADI的DSP产品AD6526为例,来说明下列各项工作的修正:
评估和发展一个basicops的准确位元版本
当参考程式码转成一个最佳化的嵌入式运算时,最重要的工作之一是适当地处理basicop功能。当许多basicop功能能够转换到一个单一的DSP指令时,参考C程式码在使用功能呼叫多数的数学运算就显得没有效率。将basicops最佳化最常用的方法是利用输入线路(inline)C的预置处理器指令,来告知编译器不要执行某一功能呼叫,而把已被呼叫的功能程式码直接包含在档案里。对一些现今的DSP架构而言,发展工具包括有一个basicop路径的资料库,使得ETSI语音编解码能够更容易地移植到特定的架构。在AD6526上,多数简单的basicops变成简单的组合语言指令,而最复杂的basicops(such as div_s)则维持功能呼叫的执行方式。
计算并分析记忆体存取到变数和表格中
分析和最佳化AMR语音编解码器最重要的一个部分,是决定在一个资料架构的处理期间,对所有表格和变数的存取数目。不同的表格和变数有很多不同的存取频率,而一些存取对于某些AMR的特定模式是很独特的。因为这样的变数性质,显示出存取到每个表格的数目和考虑记忆体架构和等待状态是如何影响整个必要的MIPS,是很重要的一件事。
如果没有硬体或软体的模拟,来支援计算一个记忆体区域的存取计算,参考C程式码能够被侦测,以用来决定每个变数和阵列的存取数目。一个计算记忆体存取的方法是在每个被存取的变数和表格的位置旁边,放置一个计数器的巨集指令,并透过编解码器来执行其中多个测试向量之一。这么做将提供在每个框架(frame)中的存取数目。如果可用的记忆体总数和相关的等待状态是已知的,人们便很有可能对系统中放置变数和表格在低速记忆体(slow memory)当中的影响,取得良好的估计。
当执行此一测试时,对语音编解码器的所有八种模式执行测试向量是很重要的。当每个AMR模式在不同的MIPS下执行且并不是所有的表格在每个处理模式中都会被存取时,每个操作模式下每个记忆体存取的频率是很重要的资讯。 MIPS较强且较经常发生的资料存取会被移到较快速的记忆体部分,以便均衡不同操作模式的效能。
堆叠使用的最小化与决定一个适当的记忆体架构
供AMR语音编解码器所用的参考程式码,是把它所有的暂时变数(temporary variable);也称为散布变数(scratch variables)放在堆叠当中。堆叠是一个普通的资料结构,其中资料和位址是在记忆体当中循序地被储存与存取。在C功能当中所宣告并使用的变数是放在一个堆叠当中,而当该功能中止时,记忆体空间会被释放出来,以供未来使用。这是一个管理记忆体的简单方法,但对嵌入式的设计而言却是很没效率的。把所有暂时的变数放在堆叠上,限制了慢速和快速记忆体的使用效率。
此外,如果其他的运算也使用堆叠,该系统架构会被强迫让最更糟的堆叠所占用。如果先占运算(在目前的工作/运算完成之前,允许一个工作/运算开始执行)是被允许的,且在系统上有多阶的优先顺序,这可能导致无效率的记忆体利用。堆叠的使用也强迫变数以循序的方式放置,且不允许多个记忆体全部用在双重的资料存取上,这是DSP架构与运算当中相当重要的一部分。最后,在某些DSP中,相较于直接定址的阵列堆叠记忆体的使用是很没效率的,DSP通常不处理以指标器为基础的存取和直接的记忆体存取。
由于上述的原因,下列的方法是用来移除来自C功能的堆叠操纵。常见的方法是「动态记忆体配置装」,例如ANSI C标准功能malloc。 Malloc将记忆体放成一堆,相当类似于堆叠的型态。这种作法的一个优点是让多数的编译器能够控制那些成堆记忆体的位置,使得系统设计人员能够把它放在适当的记忆体区隔当中。除此之外,一些malloc也能够执行多个成堆的记忆体,使其可以根据这些记忆体被存取的频率,提供一种将变数放置在不同记忆体区隔的方法。另外一种方法是创造一个「散布的(scratch)记忆体结构」,透过分析每个功能上配置了多少个记忆体,然后把这些配置放在一个C结构。在此一状况下,高阶API介面能够呼叫malloc,以配置足够的空间。一个程式如何能够从一个标准的、以堆叠为基础的记忆体配置,转换成一个使用记忆体配置和一个散布(scratch)的例子。
主要功能和两个子功能都放在它们的散布记忆体的一部分,形成一个称之为scr_scrmem的结构;该结构是被配置在主要记忆体的开端且其结尾的部分取消配置(de-allocated) 。当这个程式码使用标准的记忆体配置器在一个DSP的应用上,额外的参数将会被加到配置的功能,以允许该结构被放在一个特定的记忆体类型当中。
上述两个表列间的资料记忆体需是相同的。因为两个子功能的散布阵列(scratch arrays)结合在一起,它们只需要选择两个阵列当中较大的一个容量,来作为其记忆体(空间)。此一作法是与如何在同样的呼叫阶层,对两个功能的区域记忆体配置进行覆盖的作法相同。这个例子说明了在同样阶层的呼叫如何能够安全地把它们的散布记忆体结合在一起。如果一个运算有其他阶层的呼叫在其中(由subfunc1和/或subfunc2所形成的功能呼叫),这些结构的其他阶层(和潜在地以功能呼叫的精准细节为基础的结合)将会被放在scr_sf1和scr_sf2结构当中。
在AD6536的AMR 语音编解码器执行,不曾使用一个已通过(passed)的指标器和间接的记忆体存取从状态和散布的结构当中取得资料。然而,在此所创造的结构是用来创造配置该结构的空间所需的组合语言程式码。一个小型、以PC为基础的C语言程式是用来作为AMR状态和散布结构的。它可以分析结构的单元,并对该结构单元的名称和容量所对应的每个变数,输出一行ADSP-218X组合程式码。透过这样的方式,C结构被转换成一个相同的DSP组合语言档案,使其能够静态地分配到适当的资料记忆体空间。
将表格聚集成档案的子集合
当AMR语音编解码器在移植时,另一个重要工作是把所有来自不同C档案当中的表格,整合成几个档案。表格是在程式码中被初始化且未曾变更过的任何变数。把所有这些常数变成几个档案是很重要的,因为它们需要根据本身被存取的频率,来把表格放到不同的记忆体区隔。在ETSI原始程式码当中,表格是很简单地被包含在其所被存取的原始档案当中。根据一个特定DSP架构所设计的软体开发工具,它很难(甚至是不能)任意地把不同的表格从一个单一的档案放到不同的记忆体区隔。
处理此一情形最简单的方法是依靠可用的记忆体,来决定所有被存取表格的频率,尽可能地把许多最常被存取的表格放在一个单一档案当中;该档案将会连接到特定的记忆体区隔。决定适当的分群是透过分析从记忆体分析所得的资料,然后将最常被存取的单元放在一个单一表格当中;当较不常被存取的表格资料放在低速的系统记忆体时,前述的方式主要是以快速的内部记忆体为目标。
最佳化快取使用率并开发快取中的未使用区域以达决定性运算
由于常见DSP运算的容量和复杂性,通常需要使用一个快取记忆体的机制来处理逐渐增加的记忆体需求。在DSP运算中使用一个快取记忆体的主要问题是造成执行时间上的不确定;被执行的程式码与其所耗费的执行时间不再是单纯一对一的对应关系。此外,程式码的中断执行或提早执行会占用早先已经装满的快取记忆体,导致后续执行时间的不确定。
在DSP运算时,促成其执行时间最糟糕状况的原因是很重要,尤其是对于那些麻烦的即时处理限制(例如AMR语音编解码器必须在20ms完成其处理运算或是audible artifacts发生时)。当人们要在一个已被快取处理记忆体处理的(cached)处理器找到绝对是最糟的执行时间,是很难以捉摸的,伴随AMR语音编解码器的某些设计决策能够减少在快取记忆体上执行时所带来的冲击。如先前所提供的资讯所示,接下来的决策是有关于如何针对DSP程式码进行分隔。
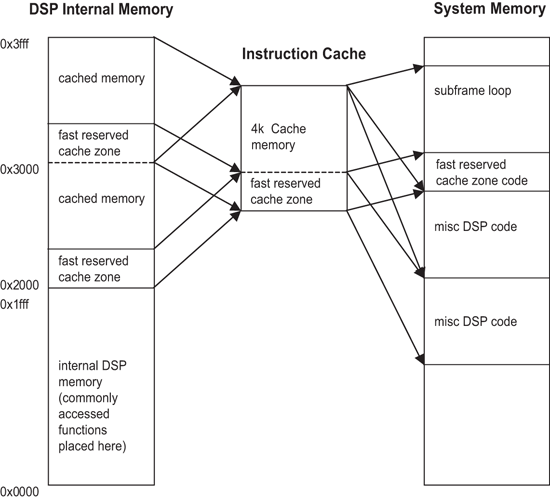
首先,最常见的已呼叫功能是被放在内部程式记忆体中。因此,这些功能不会用到快取记忆体且能够很快地被执行。接下来,程式记忆体中一小部分的区域是对应到快取记忆体上,以配置将会常驻在此一记忆体区隔的单一功能。这种作法的效果是,一旦快取记忆体惩罚(cache penalty)此一功能的首次呼叫,但在接下来的存取中,该程式码将被储存在快取记忆体上且在需要时总是能够即时提供。第三,来自编码器次框架回圈的程式码会被配置,且将被对应到一个记忆体的单一4k字元区隔。这么做是为了避免多个快取记忆体遗漏了资料当中一个框架的单一编码运算。如果有些次框架回路的某些部分是被放在较上层的4K,而其他的部分则放在较低的4K,快取记忆体将会在这个AMR运算当中的关键部分里面,持续地重新载入,如(图一)所示。
| 《图一 AMR语音编译码器优化效能所作的内存对应》 |
|
图三为AMR语音编解码器最佳化效能所作的记忆体对应。来自0x0000-0x1fff的DSP记忆体区域是透过指令快取记忆体。该快取记忆体的一小部分是由DSP程式码所对应的,以确保该程式码总能在它第一次被载入之后,持续地出现。次框架回路是设计用来常驻在一个记忆体的单一区块上,该区块能在不需要造成任何闪失(也就是整个记忆体容量必须少于4K字元减掉快速保留的快取记忆体区域的容量),就能够将其载入快取记忆体中。如果一个次框架回路不能够符合这个区隔,则在每个区隔的每个框架至少有四个快取记忆体失误,必须重新载入到快取记忆体中。
AMR语音编解码器的测试和封装
ETSI提供包括DTX处理在内的一组测试资料,以验证AMR语音编解码器的基本性能。因为该运算中有许多模组和广泛的复杂性,有数以百计的测试向量被能用来进行测试,以验证其与原始C程式码的一致性。一旦语音编解码器通过这些向量的测试,它就会被视为与参考程式码相容。然而,除了由ETSI所提供的向量数目之外,语音编解码的完整涵盖范围并没办法单纯地藉由这些测试来验证(每个编解码模式的处理语音的速度约为150秒)。
较为聪明的作法是透过其他额外向量的产生来证明原始程式码与已移植的执行间的相容性。任何测试向量,不论是来自一个语音编辑器所产生的测试音调或是抽样所得的语音,都是用来测试其运算的有效资料来源。一旦额外的测试执行之后,很有可能会在参考程式码和已移植的编解码器,两者所产生的输出中发现差异。导致这种差异的一个常见原因是如果已移植的编解码器相对于参考程式码,在basicops的处理上有些微不同所造成的。
ETSI的basicops有某些特定的功能(尤其是在如何处理环绕和饱和的部分)在有限的状况下,会有发生若干不相容的机会。通常这些细微的差距不会在基础测试向量上造成一个错误的发生,但是很可能会在一个新的向量测试中造成若干问题。 AMR语音编解码器在整个运算过程中利用许多门槛值(thresholds),如果被运算的值只比那些门槛值都略高或略低,就能够在输出上造成剧烈的变化。此外,语音编解码器也掌握很多种状态,而使得一个框架上的小差异,在一个错误发生之后,能够创造出持续很长一段时间且大量而广泛的运作。
一旦错误的精确位址和原因被确定之后,这个错误是否需要修正是有待争议的。一般而言,通常会建议维持与参考C程式码间完整相容性;此外,把它当作一个产生新的测试向量和验证适当的运算方法越来越困难。然而,若这样的差异不是被人厌恶的话,就不需要遵守,由非ETSI所创造针对参考C程式码的测试。如果一个编码运算在取舍之后,在付出了对所有可能输入的相容性的成本下,让一个AMR语音编解码器运算的某一部分能够更快地被计算,这也可能是不更改程式码的理由。
对已移植的AMR语音编解码器执行额外测试的可能性
除了透过功能性测试的执行来证明语音编解码器的相容性,透过一些一般性测试的执行来决定当语音编解码器被强迫与其他DSP运算一起运作时、或是当传递了初始程式码且已经完成强化后,是否有任何编码错误而影响其行为,是一种很明智的举动。下列是这些测试所包含的一部分:
假设跨越功能呼叫的记忆体状态
好的组合语言编码运算,是假设一个大量且完整定义的暂存器组合(也就是所谓的暂用暂存器;scratch registers)的状态,可以在不同的功能呼叫之间被安全地修改。如果可以这么做,DSP程式设计人员就不需要担心导致一个特定功能的呼叫路径,而能够在不需要担心会导致主功能执行错误运作的前提之下,就能对任何功能进行任何修改动作。
证明此一状态的方式不是用利用一个巨集指令来取代所有的功能回覆指令。当编解码器被整合到一个最终系统时,巨集指令会编译一个回覆指令;然而,在除错阶段,这样的巨集指令是被定义作为修改所有的暂用暂存器之用。如果执行了这个测试且运算持续的适当地运作,程式设计人员将能够确保任何适当运作的功能并没有依赖暂存器的状态,而那些功能能够在不需担心对其主功能造成影响的状况下被修改。
发现和移除异常的记忆体存取
一个异常记忆体存取是被定义为一个记忆体的读取和写入是发生在一个运算所定义的阵列范围之外。这些错误(bugs)是属于不会影响该运算本身的运作,但是当这些状况发生在一个较大且较复杂的系统时,可能会导致微妙且难以解决的问题。
异常的记忆体写入是危险的,可能潜在地改变其他运算的状态,以任何一种方式,使得该运算导致不当的运作。异常记忆体一开始的出现可能是无害,但随着这些发生异常的处理器,能够在一个最终的应用上,导致更陌生且更微妙的错误。
如果目标处理器没有硬体转效点,它仍然有可能找到很多异常的记忆体存取。一个方法是在下载一个AMR编解码器到目标硬体时,用已知的值设定在所有记忆体上,在执行运算之后,目标处理器记忆体会重新读取并比较执行前后的记忆体内容,检查是否有任何记忆体写入是在预期的范围之外。很不幸地,发现异常记忆体并不像检查一个记忆体写入那么容易。假设所有的记忆体都可能发现一些异常读取,若写入运算存取一个特定的值,则运算能够适当执行的时候,反之则否。然而,如果所读取的值并没使用在运算中,则能够继续适当的运作且异常存取不会被发现。另一个能够帮忙发现异常读取(和写入)的方法是,重新安排记忆体上的阵列;经由移动许多阵列的位置,使得诸如一个记忆体对应的周边装置,在强迫异常的记忆体存取移到一个不同的位址后,不能安全地被读取,而使得资料依赖性的错误有可能被发现。
当异常的记忆体存取(特别是写入动作)应该避免的时候,可能有时间能够执行在一个阵列上额外的存取,以协助改善运算的效能。很多时候,在回路开始改善整体效能前,能够在软体传递管线(pipelines)加入一个额外记忆体读取运算是很有优势。然而,确定系统设计人员知道在该运算当中已经加入一个额外的记忆体存取运算是很重要的。许多嵌入式程式运算包括在增加效能与改善可靠性和可携性之间的取舍。在执行困难的即时需求运算时,有时需要提高整合的复杂性,以取得效能上的显著改善。如果编码决定会导致额外读取阵列的增加,应该在原始程式码和公布的笔记上仔细的记载。
未经检验的程式码的检查
决定一个从已提供的测试向量中发现未经验证程式码的方法是很有用处的。一些DSP供应商所提供的这种方法是统计上的描绘(statistical profiling)。统计上的描述是从被呼叫的功能和被存取的阵列当中取得资料并加以处理。因为ETSI测试向量不保证涵盖整个AMR语音编解码器,因此建议要精确地决定在所执行的功能当中有哪些路径是不跟随基础向量集合,并产生新的向量,以使得这些路径能够透过程式码来加以执行。如果不能进行统计上的描绘,巨集指令可以用来决定呼叫树(call tree),而透过此资料,未经测试的程式码能够被推论出。
AMR语音编解码器的最后包装与文件
在完成程式码移植和发展、除错与测试等步骤之后,该运算已准备供整合之用。搭配实际的来源程式码,文件是在传递工作进行时绝对重要的必需品。
对于一个嵌入式应用上的运算而言,清楚而完整的文件是需要的;因为在一个较大型应用的效能和相容性上,通常是依赖这些运算是如何被创造的知识以及由程式设计人员所设定的系统状态假设而定。这一些应该提供的基本文件应该包括下列各项:
- ●一个目录结构的总论(an overview of the directory structure);
- ●API的解释,包含所有输入与输出资料类型所需要的资讯,和供编码器与解码器所需的一个样本驱动程式;
- ●任何被假设的处理器状态,包含处理器的运作模式以及经过各种功能呼叫未被使用或修改过的暂存器;
- ●已被观察的MIPS,包含任何有关这些值(等待状态、快取记忆体的使用等等)如何计算的假设;
- ●整体的记忆体利用,包含程式记忆体、分散的记忆体、状态记忆体和表格;
- ●测试方法,包括任何未被ETSI所指名的测试,以及前述所建议的额外方法论测试(methodology tests)。
结论
为了可靠与有效的执行,本文试图说明参考C程式码在进行移植时参考C程式码的严谨要求。由一个标准团体所提供的参考程式码,有时不能让嵌入式硬体很容易使用。当AMR语音编解码器是针对在无线手持式装置上的应用需求来写成的时候,那么实际的运算便能够在现代的DPS上有效地执行,且初始的C语言执行也必须能够进行各种修改,以符合一个嵌入式应用和DSP的架构。完成此一专案所需的时间大约是40个人/月。本文所说明的步骤,能够作为在任何DSP硬体上开发即时语音编码运算的一般性指引。 (作者为美商ADI DSP软体工程师)