目前市面上的高階智慧型手機(Smartphone),甚至是一些高檔的消費性電子產品,都已經可以提供即時3D顯示的效果,用來做為人機介面呈現、路況導航或是遊戲等即時互動應用。可以預期的Graphics Processing Unit(GPU)將被安裝在許多裝置之上,而這類Mobile GPU最重要的技術挑戰就是低耗電。近幾年VLSI技術的快速演進,讓晶片運作時脈越來越快、面積越來越小,但電池容量的進步卻遠慢於運算的需要。因此EDA業者、IC設計與系統開發業者,無不想盡辦法在電路層次或系統層次上有所突破,讓他們的產品具有低耗電並保證不影響消費者的使用經驗。
本文將介紹在Mobile GPU上有目前那些創新的系統設計,可以達到低耗電且不影響應用程式在3D表現上的效能。我們將先介紹Mobile 3D之應用發展趨勢以及規格現況,並簡單描述Dynamic power與Static power,接著本文將介紹在Mobile GPU上廣為使用的Tile-based Rendering架構以及台大資工所如何應用Power-gating技術來減低GPU之漏電耗損。我們期望可以透過本文讓各位讀者對於Mobile GPU之省電架構有個初步的瞭解。
Mobile GPU應用趨勢
Mobile 3D目前最夯的應用之一就是人機介面。自從Apple Inc推出iPhone引起廣大消費者瘋狂搶買後,越來越多人相信行動電話的介面將走向更精緻與高互動的呈現方式。台灣HTC的最新一款產品-HTC Touch Diamond所標榜的重要產品特色就是3D UI,NTT DoCoMo部分手機也搭載Acrodea設計的3D UI。我們認為3D UI將會是日後中高階手機之主要介面呈現方式之一。

| 《圖一 Mobile phone 3D UI(圖片來源:TAT、Apple與HTC)》 |
|
除了3D之外,透過軟體引擎的方式(Tessellation on CPU),Mobile GPU也可以支援向量圖形的繪製。包括Imagination Technology之PowerVR以及ARM的Mali graphics等都採用這樣的解決方案,在他們的3D產品上支援OpenVG介面。因此Mobile GPU更可以讓系統開發者在其平臺上架設Flash lite之類的向量引擎,發展具有Scalable或是漫畫風格的人機介面。
另一個值得觀察Mobile GPU應用趨勢的面向則是Java規格(Java Specification Requests;JSR)的發展。Java可以說是手機上提供行動服務的重要介面之一,不論是Feature phone或是以Symbian或MS Windows Mobile發展的智慧型手機,幾乎都搭載了Java 2 Micro Edition(J2ME) Virtual Machine。新一代的J2ME「標準配備」規格已經由JSR185移至JSR248或JSR249。JSR248/249是由多位重量級電信業者(Vodafone、NTT DoCoMo、Orange France等)與行動電話業者(Nokia、Motorola、SonyEricsson等)所共同制定。
相較於JSR185,JSR248/249在介面呈現上納入了JSR184(Mobile Graphics API)與JSR226(SVG)此兩個與互動圖形展現有關的規格。這意味著電信業者與行動電話業者皆認為豐富圖像呈現是行動服務重要的規格。配合新一代具programmable功能(透過shader)之OpenGL ES 2.0規格的Mobile 3D Graphics JSR(JSR297)與SVG JSR(JSR287)已經在制定中,而去年底推出的Android也支援3D與SVG技術。可以預期的,將會有越來越多的Mobile Java application應用3D或向量圖形來發展其使用介面。
除了行動電話之操作介面與行動服務介面之外,具備低耗電功能的Mobile GPU也可以應用到STB、DTV、TV Gaming、Navigation或是博奕機臺等領域,讓這類消費性電子產品有不同於以往的使用或瀏覽介面。總而言之,基於其低耗電與低成本的本質,Mobile GPU可應用的範圍包含了行動電話、隨身裝置、掌上遊戲機、甚至是隨身玩具等,其範圍遠大於PC GPU。
Mobile 3D Graphics技術規格介紹
目前Mobile 3D Graphics規格主要是Khronos Group所制定之OpenGL ES,現在主流的規格為OpenGL ES 1.1。最新一代的繪圖介面標準是OpenGL ES 2.0,在2006年的SIGGRAPH會議中正式推出。現階段具有OpenGL ES 2.0硬體的消費性產品尚未在市場上出現,但包括NVIDIA Tegra與TI OMAP3等高階應用程式處理器(Application Processor)都已經標榜支援OpenGL ES 2.0標準,而根據ARM的預估,在2010年始將會有少量的高階智慧手機開始內建OpenGL ES 2.0圖形加速器。
為了支援更精緻與擬真的3D繪圖品質,針對OpenGL ES 2.0標準Khronos Group一改過去OpenGL ES 1.X版本的固定功能(Fixed-Function Hardware)架構,而是引進桌上型OpenGL所使用的可程式化硬體架構(Programmable Hardware)。但OpenGL ES 2.0與桌上型OpenGL 2最大的不同是,不像OpenGL 2仍有固定管線(Fixed-Function Hardware)架構,OpenGL ES 2.0則是完全移除了固定管線之功能,使得OpenGL ES 2.0在Vertex處理階段與Pixel處理階段是一個完全可程式化硬體的架構。
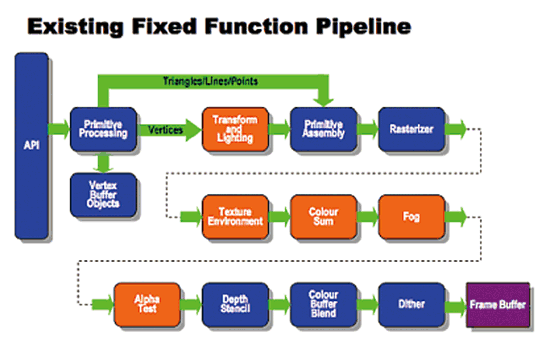
| 《圖四 OpenGL ES 1.1繪圖管線(pipeline)(資料來源:Khronos Group)》 |
|
上圖為OpenGL ES 1.1版本的繪圖管線圖,其中橘色部分所表示的處理階段如:3D空間坐標轉換、光照計算(Lighting)、材質環境、顏色、霧化及透明測試等,在OpenGL ES 2.0皆被著色器(Shader)所取代;其中3D空間坐標轉換與光照計算將會被頂點著色器(Vertex Shader)取代,而其餘部分將由片段著色器(Fragment Shader,又稱Pixel Shader)所取代。OpenGL ES 2.0的繪圖管線圖,如下圖所示。
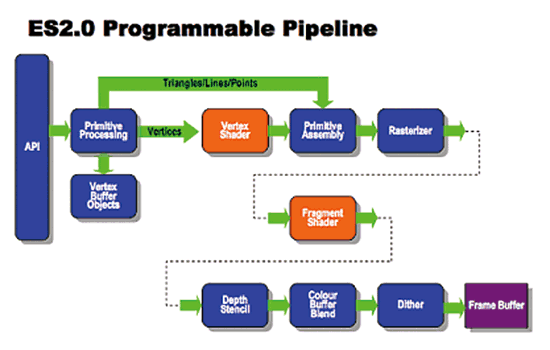
| 《圖五 OpenGL ES 2.0 Rendering Pipeline(資料來源:Khronos Group)》 |
|
在OpenGL ES 2.0的架構內,可程式化繪圖硬體(shader stage)全面支援浮點數運算,在使用浮點數的運算與上個版本相比有很大的進步。受惠於可程式化繪圖硬體上有浮點數向量與矩陣計算的硬體,OpenGL ES 2.0的Vertex Shader與Pixel Shader可以執行複雜且精確的數學運算,讓OpenGL ES 2.0可支援的功能或效果有非常高的彈性。
在編寫控制頂點著色器(Vertex Shader)與片段著色器(Fragment Shader)之程式碼(即shader code)所使用的程式語言方面,Khronos Group定義了OpenGL ES著色語言(OpenGL ES Shading Language;ESSL)。ESSL是根據OpenGL 2.0著色語言(OpenGL Shading Language;GLSL)當作參考依據,針對嵌入式裝置的需求以簡易使用與實作目標而設計出來的。在使用的語法及流程上皆與桌上型OpenGL著色語言相同。
ESSL是類似C語言的著色語言,對於C/C++/Java的程式開發者而言,它很容易學習且使用。不同的是在著色語言內並沒有指標的存在,這意會著shader程式開發人員無法直接地控制記憶體。由於著色器內的暫存器數量有限,shader程式的複雜度與暫存器的使用必須非常謹慎,過度複雜的著色器程式將會有非常差的執行效率,甚至是無法正確的執行。
另一個ESSL與GLSL之不同點是,它新追加了三個精度修飾詞:highp、mediump、lowp,目的是為了增加嵌入式系統硬體使用彈性與效率,讓不同的使用狀況可以應用不同的精確度來作運算。以浮點數為例,highp的使用範圍是(-262, 262),大小範圍則是(2-62, 262),mediump的使用範圍是(-214, 214),大小範圍則是(2-14, 214),lowp的使用範圍是(-2, 2),大小範圍則是(2-8, 2)。
Dynamic Power與Static Power概述
在CMOS電路裡,能量的耗損與功率(Power)相關。功率是電路的瞬間消耗量,而能量則是連續時間之功率耗損的總合(亦即是功率對時間之積分結果)。功率主要包含Dynamic Power與Static Power,且在CMOS電路中static power的耗損主因是漏電(leakage),包括了:Sub-threshold Leakage、Gate Leakage、Gate Induced Drain Leakage以及Reverse Bias Junction Leakage等四種主要的消耗源,其中又以Sub-threshold Leakage為主要的消耗源,然而當製程進步至65nm以下Gate Leakage將有可能成為另一個主要的消耗源。功率之耗損可以簡化成以下的公式來說明:
其中CV2αf表示Dynamic power部分,VIdq表示Static power部分。在Dynamic power耗損上,除了透過EDA工具來改善電容部分(C)的耗損,透過EDA之協助或是於架構層級(architecture level)上也可以應用clock-gating來讓電路元件停止運作以節省耗損。由公式可觀察到操作電壓的影響是二次方的結果,透過劃分整個系統成多個運作電壓區塊的方式,讓非效能瓶頸的區塊運作於較低之電壓,可以降低整個系統的功率消耗。
近年來許多文獻都在探討應用Dynamic Voltage & Frequency(DVFS)技術,藉由同時調整電壓與操作頻率來達到三次方的功率耗損節省效益。在GPU上應用DVFS以降低功率耗損,在目前市場上仍未見到類似的產品。學術界則有韓國之Korea Advanced Institute of Science and Technology (KAIST)半導體實驗室提出Triple Power-domain DVFS的GPU架構,將GPU切成RISC、Geometry Engine與Render Engine三個電壓區塊。在他們的架構下,Render Engine的供電壓與運作頻率是利用Frame與Frame之間的變化來推估下一個Frame 時Render Engine所需的值;並依據FIFO queue之狀態來判定RISC與Geometry Engine區塊目前的工作量多寡,進而決定區塊之供電壓與運作頻率。
至於Static power,除了降低電壓(V)外也可以透過降低Idq達到節省耗損。目前最常用的方式是使用Multi-Threshold函式庫,根據電子元件之特性,透過選擇Low VT(速度快但漏電量高)、Standard VT、以及High VT(速度慢但漏電量低)來合成不同部分之電路以降低功率消耗。下圖說明Multi-Threshold函式庫之delay與leakage的關係。
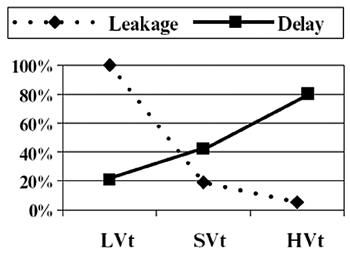
| 《圖六 Leakage vs Delay for a 90nm Library(資料來源:Synopsis)》 |
|
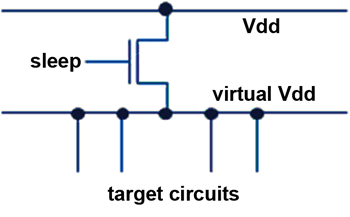
除了Multi-Threshold Library外,另一個可以應用於架構設計層次來降低Leakage的技術就是Power-gating,透過把整個電路供電關閉的方式來節省dynamic power與static power。在Power-gating實作上,通常會將一群需要一起控管電路的Vdd連接到一起,並在外面加一個transistor來控制,如下圖所示。
實際運行的時候需要額外的邏輯來判斷該電路是否可以關掉,一旦決定了就發出「sleep」訊號給sleep transistor,讓sleep transistor把virtual Vdd的電壓降到0;等到電路需要開始運作的時候,再把sleep訊號取消而讓virtual Vdd回復正常。使用power gating技術,可以同時節省dynamic和static power,但也因為需要額外的電路來執行開關的動作,導致消耗了額外的能量,必須在被控管電路進入power-gated mode一段時間之後系統才開始真正省到電。而且開關的動作需要時間,每一次要把電路從power-gated mode叫起來都需要幾個cycle的delay。因此,power gating需要一套完整的機制來決定什麼時候關和什麼時候開,且經過完整的分析驗證來確認有獲得效益。本文第六段將介紹台大資工所嵌入室計算實驗室嘗試應用Power-gating來降低GPU耗電之結果。
Tile-Based Rendering
漸成主流之 Mobile GPU 架構
Mobile GPU通常都以IP block之形式整合於系統晶(SoC)片中,並與RISC以及其他的IP block共同使用on-chip 記憶體。受限於die size之限制,on-chip 記憶體的容量通常不會很大,因此Mobile GPU在處理每個batch時(draw call為單位),必須存取存放於off-chip記憶體的texture、frame-buffer、Z/Stencil-buffer。存取off-chip記憶體通常都會耗用非常多的能量,因此在Mobile GPU之設計上,包括:Imagination Technologies、AMD、以及ARM等廠商,都採用Tile-based Rendering的架構,藉由一次完成畫面一部分(即Tile)之所有繪製動作,並以拼圖的方式將整個畫面繪製完成,來降低Mobile GPU存取外部off-chip記憶體的次數。下圖說明Tile-based Rendering的繪製概念。
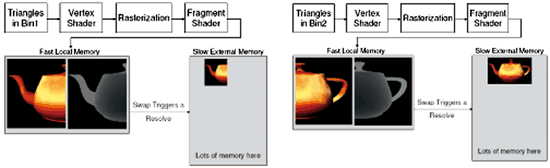
| 《圖八 Tile-based Rendering(資料來源:AMD)》 |
|
Tile-based Rendering其實源自Parallel rendering技術,透過同時平行繪製高解析度螢幕上相互不重疊的區間(tile)來加速繪製速度。Tile-based Rendering屬於sort-middle的繪圖架構,會在vertex處理完並組成三角片後對所有的tile以bounding box或其他方式進行比對,判斷該三角形屬於那個tile。並在程式發出Swap Buffer指令後逐一對每個Tile上的所有三角片以其對應的render state設定來進行繪製。
![《圖十 三角形之Bounding Box與Tile示意圖[2]》](/art/2009/02/051742270261/p10.gif)
| 《圖十 三角形之Bounding Box與Tile示意圖[2]》 |
|
相較於標準的3D繪圖流程(又稱Immediate mode)之GPU,Tile-based Rendering的GPU在繪圖過程中多了一個對三角形排序的動作,因此也需要一個Scene Buffer來存放各Tile上之三角形,且這些三角形會依Render state進行分群,來降低繪製不同render state所需之切換負擔。下圖為Imagination Technology之PowerVR SGX架構圖,其相較於一般之GPU多了負責做tile sorting的Tiling processor。
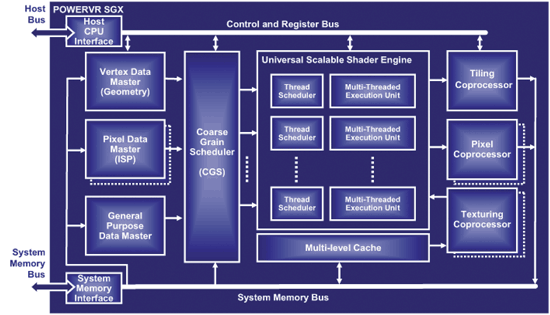
| 《圖十一 PowerVR SGX架構圖(資料來源:PowerVR)》 |
|
根據Antochi[3]等人的研究,在一個具有Tile-based Rendering的Fixed-function Mobile GPU架構下,以他們所開發的GraalBench測試程式集所測得之結果,Tile大小為32×32 pixel的設定是off-chip memory的存取量以及on-chip scene buffer需求之最佳平衡的取捨值,且相較於Immediate mode可以減少對off-chip memory存取量達1.96倍。
採Tile-based Rendering架構之GPU雖然可以因為降低對off-chip memory的存取達到省電,但需付出的代價,就是進行Tile sort所需的硬體與計算Tile sort造成的延遲、以及存放Tile資訊所需的Scene buffer。當3D場景越來越複雜且加入越來越多的視覺特效,則會有多個來自不同batch的三角形畫在同一個螢幕範圍的情形。隨著over-draw的情形越嚴重時,Tile-based Rendering架構將會因大幅減少不必要之off-chip memory存取而顯得越來越重要。
創新嘗試
應用Power-gating降低GPU之漏電耗損
要應用Power-gating來降低GPU的漏電耗損,第一個要考慮的就是GPU運作的那個元件的那個階段有足夠的空閒時間,可以被整個關閉來節省功率耗損,且整個開關的結果是確實有節省功率耗損並不影響應用程式的執行效能。
台大資工所嵌入室計算實驗室自去年開始針對GPU應用Power-gating技術之可能性進行研究;我們利用一個cycle-accurate的unified shader GPU simulator並執行四個實際遊戲的trace,來尋找可能被Power-gate的模組以及可以利用的時間點。此GPU simulator之架構接近AMD R6系列,具有六組shader processor。因為shader processor會對每個點與每個像素執行vertex shader與pixel shader,且shader程式可能包含了許多浮點數運算,所以我們認為如果能夠在shader processor中找到應用power-gating,對節省GPU功率耗損將有非常大的效益。
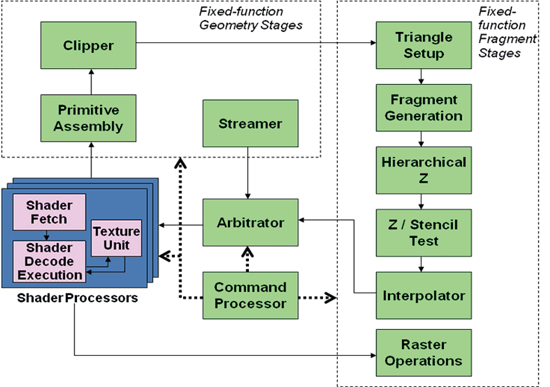
| 《圖十二 Unified Shader GPU架構圖》 |
|
下圖是我們實驗在不同運作數目的shader processor條件下對遊戲之frame-rate的影響。對PC遊戲而言,尤其是第一人稱射擊遊戲,FPS(frame-rate-per-second)需達到60,遊戲的行進才會流暢。由下圖可以觀察到,運作shader processor數目對FPS有直接的影響,運作shader processor數目越高,則FPS越高且有很多時候高於60。這意味著在此GPU架構設定下,shader processor是整個GPU運作效率的關鍵與瓶頸,且在遊戲執行過程中有很多時候不需要用到那麼多的shader processor。
因此若能在每個frame繪製前,事先決定出每個Frame需要的運作shader processor數目,並關閉不需要的shader processor,就可以節省GPU功率耗損。在這個Frame層級對shader processor進行power-gating的另一個好處,就是可以利用每個frame一開始需要對frame buffer進行clean up動作同時,對shader processor進行開關設定,如此便不會擔擱到每個frame的運作時間。
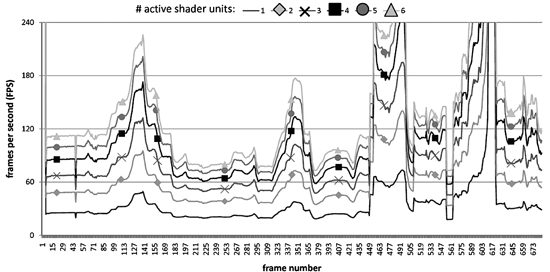
| 《圖十三 frame-rate與shader processor運作數量的關係》 |
|
我們嘗試利用Frame-rate來代表一個frame的工作量,建立frame-rate與運作shader processor數目之關聯;並利用History-based Prediction的方式,由前三個Frame的frame-rate來推測下一個Frame之frame-rate,進而求得下一個frame所需的shader processor數量。下圖是本計劃之History-based方法可以達到之leakage saving值以及最佳節省值之比較。由圖中可以看到,本計劃所發展的方法雖然簡單但確有非常好的結果。
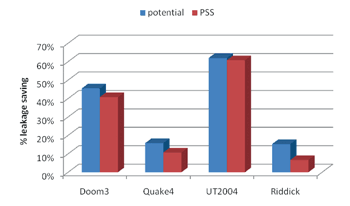
| 《圖十四 實驗結果History-based預測方法與理想結果的差異》 |
|
下圖說明本計劃的方法可以如何整合到GPU中及其與運作流程。
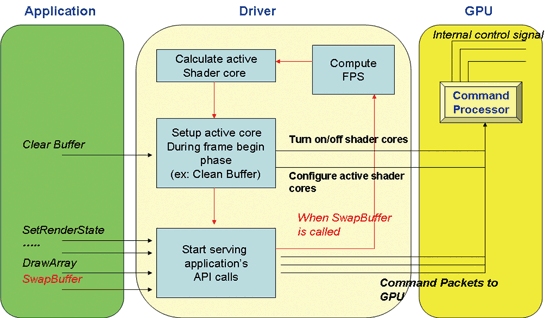
| 《圖十五 History-based預測方法運作流程》 |
|
對許多人而言,將Power-gating應用到GPU中的shader processor可能是一件有點誇張的事。但是在我們的成果接近完成之際,我們得知ARM宣稱他們新一代的Mali Graphics產品可以依據Frame的工作量,動態Power-gate GPU上四個Pixel shader core的某些core。這意味著我們的研究成果實際可行,且我們是第一個分析探討Power-gating應用到GPU可行性的研究,有一定程度的學術價值。當然,我們探討的標的(baseline)並沒有考量DVFS機制的影響,對於已經有DVFS GPU而言,我們提出的方法未必可以有節省那麼多的leakage好處。由於現階段並沒有論文深入探討GPU應用DVFS的架構設計分析,以及同時應用DVFS與Power-gating來節省能量耗損之可行性。基於其對產業之重要性,我們將進一步朝這方向繼續深入研究。
結語
隨著越來越多的行動服務應用需要使用到3D方式呈現其操作界面或內容,可以預期的日後將會有越來越多的行動裝置支援3D硬體加速。OpenGL ES 2.0規格的推出,則象徵行動裝置上顯示的品質將會超過PSP掌上遊戲機。但要達到如此高品質的效果,首先要克服的就是耗電的問題。本文簡單介紹了幾個應用在GPU上的省電架構,希望可以讓各位讀者對低耗電GPU架構有初步之認識。台大資工所嵌入計算室實驗室將持續與資策會合作研究低耗電GPU架構,日後我們將會再與各位讀者分享我們所研究的成果。
---作者楊佳玲為台灣大學資工系副教授、王柏翰為台灣大學資訊工程研究所研究生、鄭育鎔任職於資訊工業策進會網路多媒體研究所---
<參考資料:
[1] S. Monlar, M. Cox, D. Ellsworth, and H. Fuchs, A Sorting Classification of Parallel Rendering, IEEE Computer Graphics and Applications, 14(4), July 1994, 23-32
[2] D. Crisu, S. Cotofana, S. Vassiliadis, and P. Liuha, Efficient Hardware for Tile-Based Rasterization, Proceedings of 15th Annual Workshop on Circuits, Systems, and Signal Processing(ProRISC 2004), pp. 352-357
[3] I. Antochi, Suitability of Tile-based Rendering for Low-Power 3D Graphics Accelerators, PhD Dissertation
[4] PowerVR Insider, http://www.imgtec.com/powervr/insider/powervr-insider.asp
[5] B-G Nam, J. Lee, K. Kim, S-J Lee, and H-J Yoo, “A Low-power Handheld GPU using Logarithmic Arithmetic and Triple DVFS Power Domains”, Proc. Graphics Hardware, pp. 73-80, August 2007
[6] Synopsis, Low Power Methodology Manual
[7] OpenGL ES, http://www.khronos.org/opengles/
[8] E. Lindholm and S. Oberman, “NVIDIA GeForce 8800 GPU”, Hot Chips 19 Symp, August 2007.
[9] M. Mantor, “Radeon R600, a 2nd Generation Unified Shader Architecture”, Hot Chips 19 Symp, August 2007.
[10] Acrodea, http://www.acrodea.co.jp/
[11] TAT, http://www.tat.se/ >




![《圖九 Sort-Middle示意圖[1]》](/art/2009/02/051742270261/p9.gif)


