介紹:即時機器學習推論
機器學習是支撐新型服務的技術,透過使用自然語音互動與影像辨識提供無縫社群媒體或客服中心體驗。此外,它能夠在與大量變數相關的巨量資料中辨識出模式或異常,因此經訓練的深度學習神經網路也將透過數位分身(digital twin)與預測性維護等服務,轉變我們進行科學研究、財務規劃、智慧城市營運、工業機器人編程和執行數位業務轉型的方式。
無論經訓練的網路是部署在雲端還是在網路邊緣的嵌入式系統內進行推論,大多數使用者都期望能夠達到確定性的傳輸量和低延遲。然而,想在可行的尺寸和電源限制下同時達到這兩個要求,需在系統的核心架構高效且大規模的平行運算引擎,以有效率地傳輸資料,而這需要彈性的記憶體階層和靈活應變的高頻寬互連等功能。
一般用於訓練神經網路且以GPU進行運算的引擎運算週期皆相當耗時,且會產生teraFLOPS運算次數,其固定式的互連結構和記憶體階層難以滿足即時推論的要求,與上述的需求成為對比。由於資料重複、快取遺失和阻塞(blocking)等問題時常發生,因此,為達到可滿足需求的推論效能,需要一款更加靈活且具可擴展性的架構。
專案善用FPGA的可配置性
現場可編程邏輯閘陣列(FPGA)整合了最佳化的運算磚(compute tile)、分散式區域記憶體和自行調適、無阻塞的共用互連(shared interconnect),能克服傳統的限制並確保確定性的傳輸量和低延遲。隨著對機器學習作業負載的需求變得越來越嚴苛,像微軟「Project BrainWave」這類先進的機器學習專案已採用FPGA執行即時運算,可達到GPU無法企及的成本效益和極低延遲。
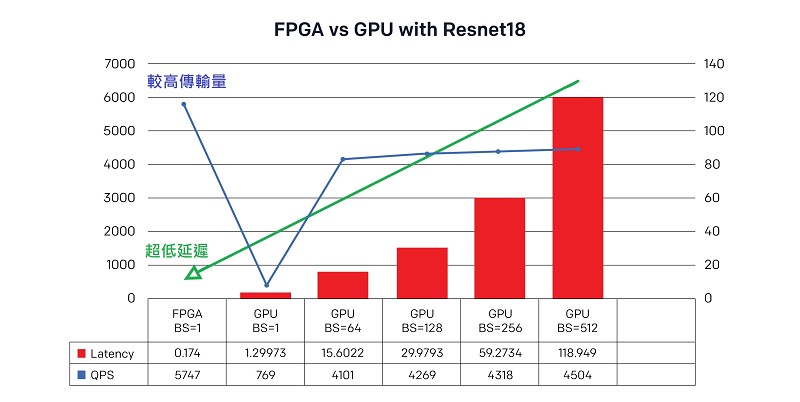
全球運算服務供應商阿里雲的先進機器學習專案也選擇FPGA作為其運算基礎,為影像辨識和分析建構深度學習處理器(DLP);該公司的基礎設施服務事業群認為,FPGA讓DLP具備GPU無法達到的低延遲和高效能。圖一所示為該團隊使用ResNet-18深度殘差網路進行分析所得的結果,顯示採用FPGA的DLP能達到低至0.174秒的延遲,比同水準的GPU速度快86%,而以每秒查詢率(QPS)測量的傳輸量則提升7倍以上。
微軟的「BrainWave」和阿里巴巴的DLP等專案皆成功建構出能加速AI作業負載的新型硬體架構。然而,這只是落實機器學習加速的開端,最終它將被雲端服務、工業與汽車產業的客戶廣為應用;其中,工業與汽車產業對網路邊緣嵌入式系統部署機器學習推論有更頻繁的需求。
另一方面,部分的服務供應商熱衷於將機器學習融入到現有系統中,以強化和加速既有的使用案例。例如在網路安全方面,機器學習能強化模式辨識,驅動惡意軟體和危險異常的高速偵測。其他案例包括將機器學習應用於臉部辨識或干擾偵測,協助智慧城市更順暢地運作。
為非FPGA專家打造的AI加速
賽靈思已建立起具備豐富資源的產業生態系,讓使用者能充分發揮FPGA的潛力,以加速雲端或邊緣AI的作業負載。
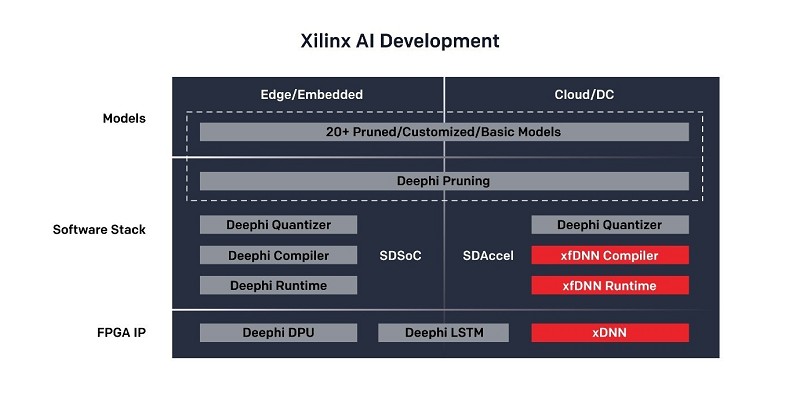
在可用的工具中,ML套件(圖二)負責編譯神經網路,以便在賽靈思FPGA硬體中運作。它能與TensorFlow、Caffe、MxNet等常見的機器學習框架所生成的神經網路共同運作,而Python API可簡化與ML套件的互動。

| 圖二 : 賽靈思ML套件為機器學習開發提供具備豐富資源的產業生態系 |
|
因為機器學習框架常常生成採用32位元浮點運算的神經網路,因此包含量化器工具的ML套件能將其轉換成定點等效網路,更適合在FPGA中運作。該量化器是整套中介軟體、編譯與優化工具及運轉時間的一部分,整體稱為「xfDNN」,它能確保神經網路在FPGA晶片上發揮最佳效能。
在賽靈思收購深鑒科技(DeePhi Technology)後,其剪枝技術也被納入賽靈思的產業生態系中,用於刪除近零權重(near-zero weights)、壓縮和簡化網路層。深鑒科技的剪枝技術能在不影響整體效能和精度的情況下,將神經網路速度提升10倍並顯著降低系統功耗。
在部署轉換後的神經網路時,ML套件提供xDNN客製處理器疊加,讓設計人員從複雜的FPGA設計工作中抽身,且有效率地運用晶載資源。每個疊加一般都有配套自己的優化指令集,用於運作各類型神經網路,使用者可透過RESTful API與神經網路進行互動,同時讓自己在偏好的環境中工作。
對於在地(on-premise)部署,賽靈思Alveo?加速器卡能克服硬體開發的挑戰,並簡化將機器學習納入資料中心現有應用的作業流程。
該產業生態系支援將機器學習部署到嵌入式或邊緣實例時,不僅運用深鑒科技所提供的剪枝技術,還有其提供的量化器、編譯器和運轉時間,為資源受限的嵌入式硬體創建高效能、高效率的神經網路(圖三)。Zynq? UltraScale? 9卡和Zynq 7020模組系統等一站式硬體(turnkey hardware)可簡化硬體開發流程並加速軟體整合。
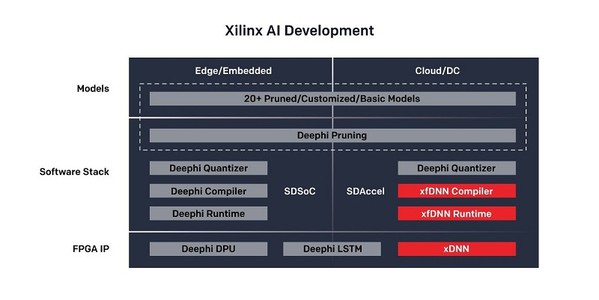
| 圖三 : ML套件提供專為雲端和邊緣/嵌入式機器學習進行優化的工具 |
|
此外,有些創新型獨立軟體廠商已經建構出能部署在FPGA上的CNN推論疊加。
Mipsology開發的Zebra是一種能夠輕鬆代替CPU或GPU的CNN推論加速器。它支援多種標準網路(如Resnet50、InceptionV3、Caffenet)和客製框架,並能在極低延遲下達到優異的傳輸量,例如在Resnet50達到每秒3,700個影像。
Omnitek DPU是另一個推論疊加的案例,能在FPGA上運作具有極高效能的CNN。例如,在GoogLeNet Inception-v1 CNN上,Omnitek DPU使用8位元整數處理執行224×224的影像推論,在賽靈思Alveo資料中心加速器卡上能完成每秒超過5,300次的推論。
可重配置運算滿足未來靈活性的要求
開發者在部署機器學習時,除了面臨需確保達到推論效能要求的挑戰外,還必須牢記機器學習和人工智慧的整體技術環境正快速變化。今日業界一流的神經網路可能很快會被更新穎、更快速的網路所取代,但原有的硬體架構可能無法良好地支援新網路。
目前,商用機器學習的應用往往集中於影像處理及物體或特徵辨識,這類應用透過卷積神經網路就能處理得很好。隨著開發者將機器學習功能用於加速字串排序或無關聯資料的分析等任務,未來這種情況可能會改變,因為使用其他類型的神經網路能夠更有效地處理該類型的作業負載,例如隨機森林(Random Forest)網路或長短期記憶(LSTM)網路。若要藉由更新硬體來處理不同類型的神經網路,就必須確保低延遲下的快速運算,然而這可能要數月或數年時間才能做到。
若使用GPU或固定架構的客製ASIC建構推論引擎,就無法輕鬆或快速地更新硬體。AI目前的發展速度已超越晶片的發展速度,因此在開發之初處於業界一流水準的客製ASIC也可能在即將部署之際成為過時元件。
相反地,FPGA的可重配置性和優異的資源客製靈活性是讓元件跟上AI發展速度的關鍵優勢。我們已知道FPGA適用於無監督學習的低延遲集群,而無監督學習是AI的新興分支,特別適用於統計分析等任務。
使用ML套件這類的工具來優化和編譯網路進行FPGA部署,能讓開發者在不具備指導編譯器決策所需的FPGA專業技術之情況下,也能在自己的環境中進行高層級作業,同時還能在未來靈活地重新配置硬體,支援未來數代的神經網路。
結論
FPGA以能提供機器學習從業者所需的效能加速和未來的靈活性而聞名。它不僅能建構高效能、高效率且可立即部署的推論引擎,還能適應機器學習領域技術和市場需求的快速變化。難題在於既要讓機器學習專家充分地發揮FPGA的架構優勢,同時又要建構能達到最佳效能、最高效率的設計,因此賽靈思產業生態系將業界一流的FPGA工具與便於使用的API相結合,讓開發者無需深入理解FPGA設計,就能充分發揮FPGA晶片的優勢。
(本文作者Daniel Eaton為賽靈思策略行銷發展資深經理)