想要玩邊緣智慧(Edge Artificial Intelligence, Edge AI)前,我們首先要先認識什麼是類神經網路(Neural Network, NN)、深度學習(Deep Learning, DL)及為什麼需要使用AI晶片,而AI晶片又有那些常見分類及未來可能發展方向。接下來就逐一為大家介紹不同類型的AI晶片用途及優缺點。
1.什麼是神經網路?
人工智慧自1950年發展至今已經過多次起伏,從最簡單的「符號邏輯」開始,歷經「專家系統」、「機器學習」、「資料採礦」等多個時期。直到2012年Alex Krizhevsky和其導師Geoffrey Hinton推出基於類神經網路擴展出來的 「卷積神經網路」(Convolutional Neural Network, CNN)「AlexNet」,以超出第二名10%正確率的優異成績贏得ImageNet大賽後,「深度學習」(Deep Learning, DL) 架構正式開啟新一波的AI浪朝。
此後持續衍生出各種不同的網路架構,如能處理像聲音、文章、感測信號這類和時間相關的 「循環神經網路」(Recurrent Neural Network, RNN) ,或者能自動生成影像、風格轉移(Style Transfer)的 「生成對抗網路」(Generative Adversarial Network, GAN) 等一系列網路架構。
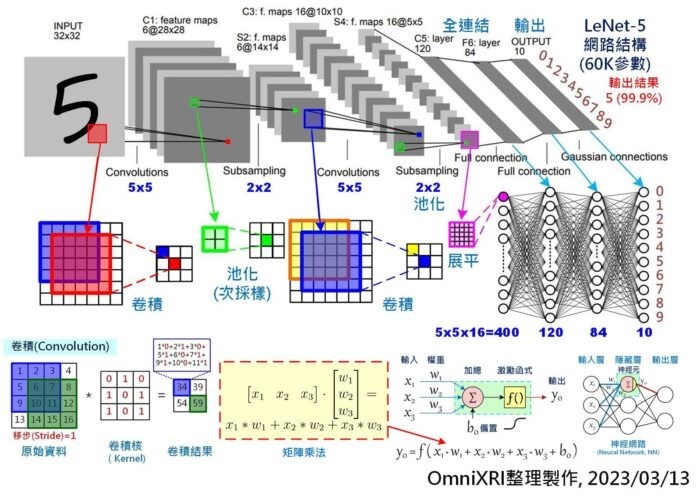
這些網路(或稱模型)都有一個特色,就是有大量的神經元(Neural)、神經連結權重(Weights)、層數(Layers)及複雜的網路結構(Network Architecture)。而其中最主要的運算方式就是矩陣(Matrix)計算,若再拆解成更小元素,即為 y = a * x + b ,又可稱為 「乘積累加運算」(Multiply–accumulate, MAC) 。一個小型模型少則數千個神經元、數萬個權重值,多則可能數十萬個神經元、數十億個權重值。以常見手寫數字(0-9)辨識小型CNN模型LeNet5為例(如Fig.1所示),它約有6萬多個權重,當模型推論(Inference)一次得到答案時,約需經過42萬多次MAC運算。而像大型的VGG16模型則有1.38億個權重,推論一次則約有150多億次MAC計算。
一般來說模型的初始權重值通常都不太理想,所以根據推論後得到的答案,必須再反向修正所有權重值,使其更接近正確答案。但通常一次是很難到位的,所以要反覆修正直到難以再調整出更接近正確答案為止,而這個過程就稱為 「模型訓練」(Model Training) 。
通常這樣修正的次數會隨著資料集(Dataset)的大小、權重的數量及網路結構的複雜度,可能少則要幾千次,多則要幾萬次甚至更多次數才能收歛到滿意的結果。由此得知訓練模型所需的計算量有多麼巨量了。
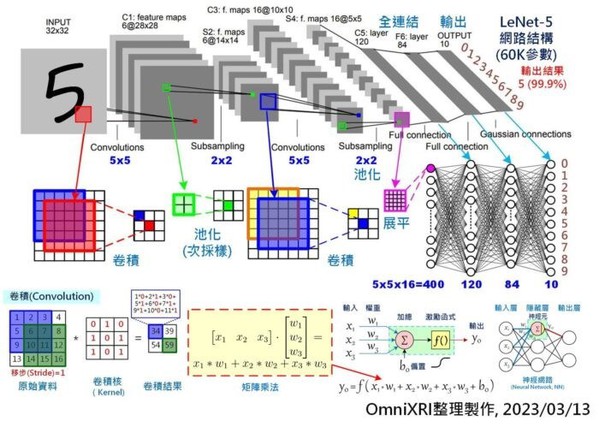
| 圖一 : 手寫數字辨識LeNet-5卷積神經網路模型及卷積、矩陣乘法示意圖。 |
|
2. AI晶片類型
為了解決如此龐大且性質單一的計算量,於是就有了硬體加速計算的需求,通常會將此類硬體稱呼為 「AI晶片」(AI Chip)或者「深度學習加速器」(Deep Learning Accelerator, DLA)或者稱為「神經網路處理單元」(Neural Network Processing Unit, NPU) 。
在AI晶片領域中主要分為訓練用及推論用。前者重點在效能,所以功耗及成本就不太計較。而後者會依不同應用場合會有高效能、高推論精度、低功耗、低記憶體空間、低成本等不同需求。尤其在Edge AI上更強調低功耗、低記體體空間及低成本需求,而效能表現通常就只能遷就不同硬體表現。
近幾年手機成長迅速,有很多晶片為了整體表現,因此整合了很多功能在同一顆晶片上稱為SoC (System on Chip),包含CPU, DSP, GPU, NPU及像影音編解碼的功能等。而FPGA的開發板也有反過來不過全部都自己設計,而把常用的CPU, DSP, AISC等整合進來,讓使用者能更專心開發自己所需的特殊功能,包含AI等應用。
2.1 中央處理單元(CPU)
不論是像Arduino、小型IoT裝置使用的單晶片(Micro-controller / Micro Controll Unit, MCU),如STM, Microchip, ESP32, Pi Pico, Arm Cortex-M, RISC-V等,或者是像樹莓派、手機使用的微處理器(Micro Processing Unit, MPU),如Arm Cortex-A系列、Qualcomm Snapdragon系列等,甚至是桌機、筆電常用的主晶片,如Intel, AMD x86系列等,都會有負責運算的中央處理單元(Central Processing Unit, CPU)。
CPU可運行各種形式的AI模型,不限矩陣運算類型,彈性極高,但一次只能執行一道運算指令,如一個乘法或一個加法或一個乘加指令,效能極低。若搭配單指令流多資料流(Single Instruction Multiple Data, SIMD)指令集,如INTEL的AVX、ARM的NEON、RISC-V的P擴充指令集,則可將32/64/128/256/512 bit拆分成8/16/32 bit的運算,如此便能提高4~64倍的運算效能。另外亦可透過提高工作時脈頻率(MHz)或增加核心數來增加運算速度。
2.2 數位信號處理器(DSP)
在MCU / MPU尚未有MAC及SIMD指令集前,當遇到需要對數位聲音或影像進行時間域轉頻率域計算如快速傅立葉轉換(Fast Fourier Transform, FFT),常會遇到大量定點數或浮點數的的矩陣計算,此時就需要專用數位信號處理器(Digital Signal Processor, DSP)來加速計算。
此類處理器在AI專用晶片未出現前,亦有很多被拿來當成浮點數矩陣加速計算使用,如Qualcomm Hexagon, Tensilica Xtensa, Arc EM9D等系列。它在開發上彈性頗高,價格居中,但僅適用於矩陣計算類的應用,在MCU / MPU開始加入MAC、SIMD指令集及GPU技術大量普及後,逐漸被取代,目前大多只有少數獨立存在,大多依附於中大型微處理器中,或者整合至小型MCU晶片中代替NPU的工作。
2.3 圖形處理器(GPU)
圖形處理器(Graphics Processing Unit, GPU)是用於處理電腦上數位繪圖用的專用晶片,而其中最主要的功能就是在處理矩陣運算,因此它能將CPU一次只能處理一個MAC的計算變成一次處理數百到數萬個MAC來加速運算,同時可以分散CPU的計算負荷。早期有些科學家發現其特性,因此開發出GPGPU (General Purpose computing on Graphics Processing Units)函式庫來加速科學運算。
2012年AlexNet透過GPU來加速訓練深度學習模型,從此開啟GPU即為AI晶片代名詞的時代。目前主流GPU供應商包括Nvidia (GeForce, Quadro, Tesla, Tegra系列) , Intel (內顯HD, Iris及外顯Arc系列), Arm (Mali系列)等。
由於GPU原本是用於電腦繪圖,有大量電路、處理時間、耗能是用來處理繪圖程序,因此後續許多AI晶片的設計理念就是保留計算部份而去除繪圖處理部份,來提升晶片面積的有效率。目前使用GPU開發的彈性尚佳,但不適用於非大量矩陣計算的模型及算法。
另外為了容納更高的計算平行度,一次能處理更多的乘加運算,因此晶片的製程也隨之越來越小(從數百nm到數nm)、晶體數量和晶片單價也越來越高,較適合大模型訓練及高速推論用。
2.4 現場可程式化邏輯閘陣列(FPGA)
一般開發如影像分類、聲音辨識、物件偵測、影像分割等AI專用型應用甚至是MCU / MPU等通用型應用晶片前,為確保投入像台積電等晶圓代工廠生產前沒有電路及計算功能的問題,通常除了會使用軟體進行模擬分析外,亦會使用FPGA (Field Programmable Gate Array)來進行硬體驗證。常見的供應商有Xilinx(已被AMD收購)、Altera(已被Intel收購)、Lattice等。
FPGA除了可以驗證IC的功能外,另外由於其超高彈性,所以可以排列組合出超過CPU / DSP / GPU 功能的應用,且可以用最精簡的電路來設計,以達到最低功耗、最高執行效能。但此類型的開發非常困難,需要非常專業的工程師才有辦法設計,且需配合相當多的矽智財(Semiconductor intellectual property core,簡稱IP),因此大型FPGA的單價及開發成本是非常高的。
2.5 特殊應用積體電路(ASIC)
當使用FPGA驗證後,就可以將特殊應用積體電路(Application Specific Integrated Circuit, ASIC)送到晶圓廠及封裝廠加工了。完成後的晶片就可獨立運作,優點是可大量生產讓單價大幅降低,能滿足市場需求,同時擁有極高的執行效能和最低的功耗。但缺點是沒有任何修改彈性,萬一設計功能有瑕疵時就有可能需要全部報廢。因此當沒有明確市場及需求量時,通常會使用如CPU或GPU或CPU+NPU等通用型解決方案來取代。
2.6 神經網路處理器(NPU, DLA)
「神經網路處理單元」(Neural Network Processing Unit, NPU)或稱「深度學習加速器」 (Deep Learning Accelerator, DLA)是專門用於處理深度學習神經網路運算的特殊應用積體電路(ASIC)。它較接近GPU的用法,所以可以一次處理很多的乘加運算(MAC)。但因為只負責乘加計算,無法處理大量資料搬移及邏輯性計算,所以通常必須搭配CPU使用。
大多數的AI晶片都是屬於這一類型,使用上較有彈性,可適合各式新模型的變化。不過由於NPU的軟硬介面規格無法統一,因此在開發上能支援的AI框架(如TensorFlow, TensorFolw Lite, TensoFlow Lite for Micro, PyTorch等)或IDE(如Jupyter Notebook, Arduino, OpenMV, 各廠商MCU專屬IDE等)就有很大不同,選用前需考量自身工程能力。另外根據不同應用,小型NPU主要用於推論,可以放到MCU / MPU或手機中,如Intel(Movidius)Myriad, Arm Ethos U55, Google Corl等,大型NPU則可以放到桌機、雲端伺服器中,如Nvidia GTX / Tesla / A100, Google TPU等。
3. AI晶片最新趨勢
目前AI應用越來越強大,模型權重數量已從數萬個(如LeNet-5)激增到近一千多億個(如GPT3),傳統NPU, TPU及FPGA的速度已不夠快,功耗也大的驚人,因此近來開始有廠商在開發新的解決方案,企圖以更接近人腦運行方式或者減少在計算時權重大量搬移問題,甚至使用光子進行計算來進行改善。以下就簡單介紹幾種常見方案,如Fig. 3所示。
可重構型(Coarse Grain Reconfigurable Architecture, CGRA):可依不同需求以軟體重構位元寬度、MAC算子結構、矩陣計算結構、混合精度計算等。主要代表廠商如下:
‧耐能(Kneron)
‧Wave Computing
‧清微智能
‧雲天勵飛
‧燧原科技
類腦晶片(Neuromophic神經型態):主要模擬人類大腦神經脈衝計算方式。有以下幾種方式及代表廠商:
‧數位式:IBM TrueNorth, Intel Loihi, SpiNNaker
‧類比式:Neurogrid, BrainScales, ROLLS
‧新材料式:Memristor
記憶體內記算(Compute in Memory, CIM)(大陸稱為存算一體、存內計算):主要將記憶體和計算單元整合在一起,減少計算時大量記憶體搬移浪費的時間。主要括下列幾種技術:
‧靜態(電晶體式)隨機存取記憶體SRAM (揮發性記憶體)
‧磁阻式隨機存取記憶體MRAM (非揮發性記憶體)
‧可變電阻式隨機存取記憶體RRAM (非揮發性記憶體)
‧光子晶片:主要以光子代替電子,以提升運算速度。代表廠商包括:
‧Lightmatter
‧曦智(Lightelligence)
小結
歷經近十多年的發展,AI加速晶片不論是在雲端伺服器所需要的大型模型訓練或是模型高速推論,或者邊緣裝置所需小而美、高性價比的推論單元,都已有長足的進步。相信隨著半導體技術的提升,未來Edge AI能運行的模型大小、複雜度及所需的功耗都能有更棒的表現,能適用的AI應用也會更加寬廣。
(本文由VMAKER授權轉載;連結原文網址)