網際網路的蓬勃發展,造成了資訊急速地擴張;在這一波變革中,人類正快速地將現實生活中的資訊,如報紙,雜誌,書籍等,都延伸至虛擬的網際網路空間中。而虛擬的網際網路空間也因為人類的高度的依賴,而變成現實生活的一部份。
在追求速度的競爭環境中,面對網際網路中大量且多樣的資訊,如何快速且有效率地找到自己想要的資訊,儼然是一項重要的課題。而搜尋引擎在定位上,也從單純個人資訊檢索的位階,躍上了企業內部知識管理工具的重要角色。
搜尋引擎的應用層面相當廣泛,主要是針對不同的資料來源(網路資源)而有不同的應用,在Internet 中常見的網路資源為 web page、BBS、news等。另外,搜尋引擎也不再是一個被動的查詢工具,而在結合其他網路服務的情況下,已從被動的查詢工具變為一個主動的資訊收集者。
本文將針對網際網路的搜尋引擎來介紹其基本架構、功能及其應用面。
搜尋引擎基本架構
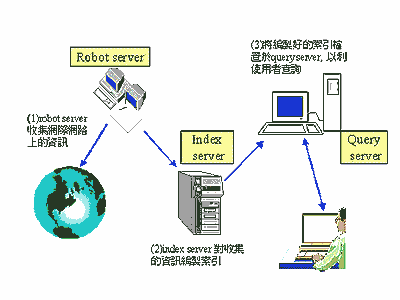
網際網路的搜尋引擎,其運作大概是這樣子的。首先搜尋引擎必須能根據我們所要搜尋的網路資源進行資料收集;例如,當我們要對新聞進行檢索時,搜尋引擎就必須把這些新聞全都收集回來。接著,搜尋引擎必須把這些收集回來的資料,進行一番處理。如果重複的資料是沒有意義的話,搜尋引擎在這一部份主要的工作就是去除重複的資料;然而有些情況下,重複的資料可能會賦予不同的意義,在這情況下,搜尋引擎就不會重複的資料刪除。而對web page全文檢索而言,通常也會去除html的標籤(tag),以確保有效資料量為最大。第三個步驟就是對處理過後的資料,進行索引的編製,而編製成一個索引資料庫,以供使用者來查詢。值得特別注意的是,能夠處理中文的搜尋引擎,通常會在這一部份加入一些「同音」及 「同義詞」的功能;因此,會使編製出來的索引資料庫比原來的資料大了許多。整個搜尋引擎的實際運作,如(圖一)所示。
在邏輯上,整個搜尋引擎的服務系統,是由「robot server (spider)」、「Index server」及「Query server」等伺服器來組成。然而在實際應用上,並不一定會把這些服務系統放在三台不同的電腦上,而會視實際資料量的多寡、網路頻寬、電腦硬體等級、搜尋引擎編製索引所需時間及處理使用者查詢的回應時間(response time)等因素,來調整這些服務系統所需使用的電腦數目。常見的一種情況是,由於網際網路上的資料量相當大,為了以更短的時間來收集這些網路資源,搜尋引擎會啟用更多的spider 程式或更多的robot server 來收集這些網路資源。因此,對於一個好的搜尋引擎而言,除了系統穩定、執行速度快,查詢結果精確等條件外,它也必須具備橫向擴充的功能;也就是可以支援多台robot server 去收集網路資源,支援多台index server 同時來編製索引檔,當然也必須支援多台query server 以平衡使用者查詢負載(loading)。
從理論來看,搜尋引擎有四個主要的部份:
(1) 資料蒐集子系統:
資料蒐集子系統,乃是用來蒐集網路上之資訊。一般通稱網路蜘蛛,也就是我們前面所提到的spider 或robot server。
(2) 資料分析管理子系統:
資料分析管理子系統,可用來過濾分析摘要轉換或管理資料,並可去除重覆多餘的資料。如果是要對網頁進行全文檢索的話,通常在這一部份會保留所有實際的資料;另一種可能是,搜尋引擎並不對網頁中每一文字進行全文檢索,而是只對網頁中某些特殊資料進行檢索,如標題或摘要等;在這種情況下,就有賴於資料分析管理子系統來萃取有用的資訊了。能夠有效率且精準的萃取有用的資訊,意味著在使用者查詢時,會有更快速及更精準的查詢結果。因此,全球資訊網協盟(W3C)也在HTML中制定更多語意性彙總資料(Meta data),就是希望在萃取有用的資訊時更有效率。
(3) 索引/查詢子系統:
索引/查詢子系統,乃是搜尋引擎系統最重要的核心技術,它必須能夠高效率的處理巨量的資料索引與執行強大的搜尋功能。
(4) WWW界面軟體子系統:
WWW界面軟體子系統,乃是一些界面程式,用來將搜尋引擎與在網頁整合。這個子系統最主要的功能是接受使用者的查詢需求及呈現查詢結果。
對搜尋引擎而言,索引/查詢子系統還攸關著一個相當重要的議題,那就是查詢結果的精準度。所謂「精準度」,我們可以用一個例子來說明,假設搜尋引擎透過網路蜘蛛收集的網頁中,只有1000個網頁有出現「周蕙」這個詞句。當使用者查詢「周蕙」時,如果搜尋引擎能夠把這1000個網頁完整的找出來,那麼這個搜尋引擎的精準度是高的;若是搜尋引擎無法完整地找到這1000個網頁,或是把沒出現「周蕙」的網頁也找出來,則可以理解的是這一個搜尋引擎的精準度是比較差的。
但是從更深一個層面來看,一個搜尋引擎雖然能夠完整地找到這1000個有出現「周蕙」網頁,它的「精準度」仍然可能會受到使用者的質疑。從經驗上我們知道,當查詢的輸出結果太多時,對使用者其實是不具任何正面意義的。因此,一個精準度高的搜尋引擎,必須還要依據這1000個網頁的重要性來進行排序(ranking)。有許多方法可以評估搜尋引擎的好壞,而ranking的技術則是使用者最容易感受到的一個評比項目。感受之深就好比在路上有人問您「榮總」在哪裡?精準度高的搜尋引擎會告訴他「台北榮總」、「台中榮總」或是 「高雄榮總」的網址,而不會先告訴他「台北榮總教學研究部」或「高雄榮總胸腔內科」的網址,如(圖二)所示。
當然一個適合的ranking 演算法,往往是相當複雜的。通常會以關鍵字所出現在網頁的次數、與網頁總字數的比例、出現的位置及被其他網頁參考(reference)的多寡等因素來決定ranking 的權重,再予以排序。
搜尋引擎的功能
常聽人提到,在軟體產業中必需發展沒有文化區隔的軟體,才會有進軍國際市場的競爭力。掃毒軟體就是一個很好的例子,事實上,全世界的電腦都可能受到同樣病毒所感染;另外一個例子,大概就是搜尋引擎了。我們知道有些國外開發的搜尋引擎,面對華文資料(big5)的檢索是有問題的;因此,對於國外的搜尋引擎而言,這是一個進入障礙。然而,對國內廠商來說,卻能輕易地檢索英文或其他語系的資料。由此可見,國內的搜尋引擎只要能提供完整的檢索功能,將會有進入國際市場的優勢。
在這個段落中,我們會從使用者的觀點來探討搜尋引擎應該具備的功能。
全球語文檢索核心
可檢索的內容不分語文種類,而不會有中文比較快,英文比較慢,或多種語系合併查詢時產生謬誤的現象(如查詢「WWW網站」在某些中英文網頁全文檢索系統中會先轉成「WWW*網站」的查詢字串,所以除了找到該找的網頁外,還會找出同時包含「WWW」和「網站」的其它錯誤或不必要的網頁。
中文同音功能
針對中文中同音近義字特別多的特性設計,能解決諸如「臺灣」和「台灣」的同義詞,或「意大利」及「義大利」的譯名差異等問題,讓使用者能輕鬆找到該找到的資料。
全球語文容錯功能
提供語文模糊容錯功能,能判斷依近似程度依序列出,例如輸入「電子書」能查到「電子圖書、電子百科全書」;又如我們想查「貝多芬」, 正確的單字應為「Beeth- oven」,如果輸入「Beathoven」 或 「Beethaven」都能查到正確的「Beethoven」的資訊。
多項目查詢功能
讓使用者能同時輸入幾個有興趣的關鍵字,並可要求某個關鍵字一定要或一定不要存在,而能進行方便且有效的查詢。例如輸入「+green, red, -blue」即代表查詢資料中一定要有「green」,一定不能有「blue」,「red」則可有可無,但是如果有的話排序比分會比較高。
自然語言查詢功能
讓使用者能輸入口語化的問題,例如「主機板的價格如何?」,系統會過濾出問題的重點再進行查詢。
全球語文片語查詢功能
讓使用者能以空白隔間數個字串形成片語以進行近似該片語之內容的查詢。例如使用者可輸入「apple pie」可查到含有「pie made of apple」的內容,輸入「民雄 中正大學」可以找到含有「中正大學在民雄」的內容。
繁簡中文對譯
提供使用者能輸入繁(或簡)體中文檢索簡(或繁)體中文內容,並以繁(或簡)體中文顯示網頁結果。
此外, 搜尋引擎也應該包括提除外字功能、同義字及布林運算檢索等功能。
搜尋引擎在網際網路的應用
對一個入門網站(portal site)經營者而言,必須思考許多重要的議題。例如如何吸引網路使用者第一次光臨這個網站?如何增加使用者駐留網站的時間?如何讓使用者願意重複上站,甚至每天上站?而搜尋引擎在這一連串的思考過程中的確扮演一個重要的角色。當一個使用者要尋找他想要的資訊時,往往會想到利用入門網站的搜尋引擎來幫忙,所以搜尋引擎至少能幫助入門網站經營者達到吸引網路使用者第一次上網及重複上站的目標。
在傳統應用上,搜尋引擎是入門網站必備的工具之一。所有入門網站幾乎都會準備好搜尋引擎「等待」使用者來查詢。然而這樣的觀念也在慢慢改變中,正如前面所提到的,搜尋引擎的應用已不再是被動地等待使用者查詢,而是會主動地去尋找使用者想要的資訊。
在這方面的應用,有一個簡單的例子,那就是個人化新聞。在某些網站中,使用者可以自訂自己想要的網頁資訊,假設您希望每次上站都能看到有關於「張惠妹」的新聞,您只要完成訂閱的程序後,就能在您每次登入(logon)這網站時,系統會立刻透過搜尋引擎把所有當天有關「張惠妹」的新聞找出來,並顯示在畫面上。
另一個例子就是把個人化新聞跟電子郵件作整合。現在大多數的網路使用者不見得每天會上哪個網站去看新聞,但卻有每天收發電子郵件的習慣。假設有使用者對「地震」的新聞有興趣,可以肯定的是,他幾乎沒有辦法完整的收集這些新聞;也不可能每天上入門網站或新聞網站來閱讀所有新聞。這種情況下,就可以發揮搜尋引擎的功效了。如(圖三)使用者只要到提供這些服務的網站訂閱想收集的新聞關鍵字,就可以每天收到包含這些新聞的電子郵件了。
另外,搜尋引擎還可以有不同的應用。例如您要購買某廠牌的A型號雷射印表機,也許有很多網站都有出售這一產品,如果您希望買便宜一點的話,就必須到每個網站進行「比價」,以確保價格最低。如果把搜尋引擎的技術運用進來,讓網路蜘蛛去把這些網站的資訊收集回來,然後再萃取這些會影響購買決策的資訊,再針對這些資訊加以編製索引就可以了。當使用者輸入「A型號雷射印表機」,就可以看到這些網站出售A型號雷射印表機的相關資訊了,以快速決定向哪一個網站進行購買。
結語
網際網路快速地累積資訊,象徵著這一波知識革命已在默默進行著。不論資訊或是知識的數量,己經多到人類無法掌握的地步了,在追求速度與品質的今天,唯有用最有效率的時間及最好的工具,才能獲得最有用的資訊, 這也才是2000年後的競爭法則。本文僅就個人對搜尋引擎粗淺的認識表達看法,事實上在無限的網際網路空間中,還有許多很好的工具可以讓我們來使用,也希望善用週遭的工具而達到掌控知識,駕馭知識的領域。
(作者任職於網擎資訊軟體公司)
(網際先鋒2000.1月號68期)