首先,到底什麼是AI運算,它跟一般的運算有什麼不一樣?其實它是有點不一樣,因為AI運算是專門處理AI應用的一個運算技術,是有很具體要解決的一個目標,而其對象就是要處理深度學習這個演算法,而深度學習跟神經網路有密切的連結,因為它要做的事情,就是資料的辨識。
它跟一般的傳統運算是很大很大的不一樣,它是很多的乘法加法的累計,所以要處理這種應用,一般的運算架構其實是會有點使不上力。也因為這樣子,會去開發出特別的運算技術專門解決它。也因此AI的系統或處理AI的運算裝置,都會有相對應的軟硬體去解決,它跟一般的產業應用,也會被劃分開來。
AI運算與記憶體的關聯
至於AI運算在硬體架構上有什麼不同?對此我們必須要從資料處理的發展來理解。
在早期的時代,一般的資料只需要用CPU來處理,但隨著大數據應用的崛起,以及人工智慧逐漸展露頭角,資料量也開始呈現爆炸性的成長。而由GPU多核心與利於平行運算的特性,於是就被用來作為AI運算的主要處理單元。但隨著資料量持續的成長,僅使用GPU似乎又不是個最好的解決方案,除了成本高昂之外,也存在著高功耗的問題,並衍生出散熱與系統穩定度的議題。
對此,運算架構就再多了一個運算晶片,也就是AI加速晶片。它主要是加速資料運算,尤其是針對神經網路這類資料處理與分析應用,且它是作為一個加速的輔助工具,並不是一個主要的運算的單元。
至於AI的應用,目前聲勢最大,也最廣為人知的,就非生成式AI莫屬。但這個部分是屬大型雲端服務商的領域,也就是AMD和NVIDIA主攻的市場,主要的業者包含AWS、微軟和Google等,一般的中小型企業並無法進入,多數僅是成為其供應鏈的一員。
但除了雲端的AI應用之外,還有另外一塊也是AI的重點應用,就是邊緣運算,而它跟雲端運算不一樣,是跟我們日常生活的裝置都能有結合之處,包含AR/VR、智慧家庭、智慧音箱、智慧穿戴等,幾乎所有東西都可以有那種邊緣運算的功能,而這裡面,都會用到這種深度學習這種技術,因此也都有需要這種AI加速晶片的機會。
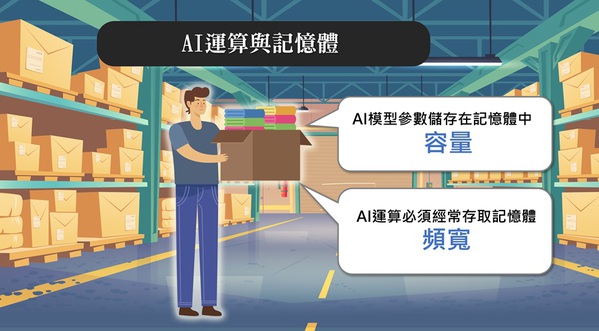
| 圖一 : AI運算模型參數都是存在記憶體當中,容量需要更大一點,同時要經常去存取記憶體,對頻寬有更大的要求。 |
|
一般來說,AI世代的這個記憶體,主要是聚焦在運算輔助的記憶體,也就是揮發性的記憶體。那它跟AI運算有什麼關係呢?
我們可以想像在一個倉庫裡面,那裡堆了很多的資料,而記憶體其實扮演的就是要把資料拿出來拿進去的角色。到了AI運算時代,這個人他會遇到什麼問題呢?首先,就是AI這個模型參數都是存在記憶體當中,所以第一個影響,就是容量需要更大一點,因為當模型參數都放到裡面,就會對執行的運算空間產生影響。
第二個影響,就是AI運算必須要經常去存取記憶體,這樣就會對頻寬有大更的要求。就譬如一次拿的東西如果多一點的話,運作的效率也會比較高,處理的速度也會比較快;另外一個問題,是傳統的運算的架構,記憶體多是屬於外部存取的形式,所以當資料存取很頻繁的時候,自然就會牽涉到效率與IO瓶頸的問題。
AI世代的關鍵記憶體技術
也因為這些容量、頻寬、IO瓶頸的挑戰,讓AI世代的記憶體,開始朝向更大的容量、更大速度,同時也衍生出新的晶片架構,並刺激新的商業服務模式與新的記憶體技術的出現。
HBM高頻寬記憶體
AI世代的第一個關鍵記憶體技術,就是目前火紅的HBM(High Bandwidth Memory)高頻寬記憶體。這個是由三星、AMD跟SK海力士共同發起的一個3D DRAM技術,現在已經變成一個產業標準。它最大特色就是一種採用TSV(Through-Silicon Via)技術的3D堆疊DRAM。
它的特色就是它的高容量,因為採用堆疊的方式,所以單一個晶片的容量就很大,另外也因為採用堆疊的方式,也會需要用新的方式-「Silicon interposer」來連接GPU。目前HBM已經到了第三代「HBM3e」這個版本,其頻寬達到了每秒1.2TB,單晶片就具備24GB的容量。以美光的產品為例,其Host的這個設計就有8顆DRAM Die,並用TSV把它串起來,一層是3GB,8層的單晶片有24GB。

| 圖二 : HBM已經變成一個產業標準。它最大特色就是一種採用TSV技術的3D堆疊DRAM。 |
|
AI記憶體整合服務
第二個關鍵技術則是「AI記憶體整合服務」。不同於HBM是針對雲端運算伺服器,AI記憶體整合服務則是專門針對邊緣運算系統來提供的AI記憶體客製化的方案,它主要是透過結合3D堆疊與異質整合(先進封裝)技術,來提高記憶體頻寬與容量,同時也能減少系統功耗,並縮小晶片體積。而它可以採用2.5D的設計,也支援3D的記憶體設計。
目前市場上有提供此一服務的兩家廠商就是台灣的華邦與鈺創。華邦提出一個叫做Cube的解決方案,它是customize Ultra bandwidth element的縮寫.就是客製化高頻寬元件。它其實是直接把這個DRAM也用類似HBM的方式,把DRAM堆疊起來。而華邦用的是一個3D TSV DRAM的KGD(Know good die),並再提供2.5D跟3D的前後段的製程服務,再加上技術諮詢與interposer的附加服務。
鈺創則是提出一個叫做「memorial link」的AI記憶體平臺,搭配的則是他們獨家的RPC DRAM,並透過異直整合服務,協助客戶將邏輯處理元件與記憶體整合起來。同樣的,鈺創也提供一個軟硬體平臺,可以協助客戶進行設計,並搭配後端的封裝與製造服務。比較特別的是,鈺創的RPC DRAM是一種特殊規格的Reduced Ping Count DRAM,它的針腳只有標準DRAM的一半,但具備相同的頻寬,因此尺寸較小且電耗較低。
而值得注意的是,這兩家公司都是以提供記憶體晶片為主的公司,本身也有晶圓廠,其AI記憶體的服務方案是一種結合自家產品,再搭配上臺灣的半導體供應鏈的一種服務模式。

| 圖三 : 鈺創「memorial link」AI記憶體平臺,使用自家RPC DRAM,並透過異直整合服務,協助客戶將邏輯處理元件整合起來。 |
|
CIM記憶體內運算
第三個關鍵技術,則是記憶體內運算(compute-in memory;CIM)。它的技術概念就是在要減輕CPU存取記憶體的負荷,所以在記憶裡面先進行一些簡單的邏邏輯處理。它有兩個適用的場景,一個是分欄式資料儲存應用,另一個則是平行運算,而這些就很適合AI運算來採用。
目前臺灣的工研院也提出了這樣的技術,他們提供的是一個Marco IP,能夠直接在記憶體內進行運算,運算效能是傳統的10倍,而且功耗僅有十分之一。而採用此技術的運算效能最高可以達到30TOPs(@ 4bit)。
因應AI運算的需求,旺宏電子也提供了特殊的CIM的技術產品。他們是在自己的3D NAND和NOR記憶體加入了這種運算的技術,讓產品可以兼具儲存跟運算功能,也就是他們新的一個產品線叫「FortiX」。旺宏把它稱為「in memory search」,是在記憶體裡先進邏輯處理,不用透過CPU就直接做資料查詢,能夠加速資料運算速度。
另一個則是力積電的AI記憶體平台,它是與子公司愛普科技、智成電子與智慧記憶體科技組成的AIM(AI Memory)平台,訴求Computing in Memory技術。但其實是把DRAM嵌在MCU裡面,並把中間的I/O拿掉,整合無線的功能,接著透過堆疊跟封裝的方式架構出一個AI記憶體的平台。不過這平台在2019年發布,近期並未有新的進展。
創新的AI記憶體
除了既有記憶體技術的轉型和新型封裝方式之外,創新的設計方法才是關鍵所在。目前也有一些新創公司運用創新的架構,研發出新型態的CIM運算記憶體方案,來搶攻AI運算市場,包含TetraMem與Mythic。
TetraMem它是2018年才成立的一個美國新創公司,主要成員都是華人,他最近也跟臺灣的晶心科技進行合作,採用RISC-V的核心作為處理器。以其MX100 單晶片產品為例,該方案是一個邊緣運算的AI加速晶片,號稱是市場首款多層 RRAM(電阻式記憶體) 類比記憶體運算系統, 具有多個神經處理單元(NPU),每個 NPU 核心具有 64k 8 位元權重和 RISC-V 處理器,能夠為小型捲積神經網路提供高效能的乘法累加(MAC)效率。
至於Mythic,它則是一家稍有歷史的公司,目前是人工智慧方案的提供商,同樣也是採用CIM技術的產品,它的M1076晶片,提供高達 25 TOPS算力,整合了 76 個 AMP 區塊,可儲存多達 80M 權重參數,並執行矩陣乘法運算, on-chip的DNN模型執行與權重參數儲存,無需任何外部記憶體,適用於高階邊緣 AI 應用。
另外就是台灣的力旺(ememory),它們主要是記憶體IP供應商,近期也針對AI應用與神盾合作推出號稱是全球首顆類比 AI 晶片,可應用在屏下大面積光學指紋辨識系統,這個技術是透過將指紋辨識軟體和非揮發性記憶體(NVM)硬體技術結合,進行達成整合運算處理功能的記憶體。

| 圖四 : TetraMem採RISC-V的核心,推出一種CIM技術的AI加速晶片。 |
|
結語
根據IDTech EX的市場研究資料,AI晶片市場在未來十年內具有龐大的成長潛力,特別在BFSI(銀行、金融服務和保險業)、消費電子、IT和電信業等三大領域,其中IT和電信會位居主導的位置,並成為最大的市場,且其領先優勢會越來越大;至於BFSI 的成長速度將會加快,並逐漸超過消費電子產品。
整體來說,隨著AI應用的遍地開花,AI 晶片的市場也會隨之水漲船高,與此之時,與AI運算息息相關的記憶體技術當然也會跟著一起蓬勃發展,而且不只是應用的場域越來越多,同時技術規格也將逐步提升,包含容量與處理速度,並激發出創新的記憶體技術。而那臺灣這些老牌的記憶體公司也將獲得新的活力泉源,並在AI時代找到自己的利基市場。