「積木化、跳島式」乍聽之下是筆者在故弄文字玄虛,但這確實是目前運算領域發展的最新趨勢,更簡單來說就是一般常言的模組化運算、分散式運算(Distributed Computing)、平行運算(Parallel Computing),與此相關所常提及的名詞則有叢集(Cluster)、網格(Grid)、雙核(Dual Core)、多核(Multi Core)。
或許讀者尚難體會這些新詞語間有何共通點,且讓筆者以技術演化觀察的角度,逐一為各位說明各種新技術的成因,以及各技術如何走向理念性的匯集。
指令級、晶片級的分拆加速運算
一人要十小時才能完成的事,若兩人同時進行則可縮短至五小時,這就是平行處理的概念,將完整事務以不違背正確性、不矛盾衝突為原則進行多份拆解,然後多份同時執行以求加速,許多運算新技術、新架構都是因此而來。
例如超純量(Superscalar)架構,即是在一顆CPU內設置兩組以上的執行管線,讓原本要前後依序執行的指令,在研判無運算相依性後,同時交付給兩個執行管線一起執行(如電影售票窗口從一個變成兩個),以此來加速,這也是Pentium在效能上能大幅超越80486的主因。
不過,程式指令不可能隨時保持無前後相依性,一旦前後相依(來源相依或結果相依)就無法平行執行而需要恢復成排隊式的依序執行(恢復成單一窗口),為了提高平行執行的運用機會而有了亂序執行(Out Of Order Execution),在發現相依後則開始進行相依排解,以不影響運算結果的方式將指令執行順序及計算方式加以改變(這時會搭配運用暫存器重新命名Register Rename技術),如此就能保持雙線同時執行。
當然!Superscalar也可以持續平行化設置,如過去的RISE mP6處理器即具有三個執行管線,比Intel Pentium、Cyrix 6x86的兩管線還多,但是業界並沒有以持續增加平行管線的方式來加速,因為相依排解有其限度,程式指令要同時能三線、四線執行的機會極低。
從指令執行層面進行平行拆解加速已到極致,因此有人提出更提前性的相依排解(平行化),即是在程式開發過程中就做到最高程度、最佳化的相依性拆解,既然指令執行時的相互關連性降至最低,CPU就可以同時執行更多組指令,以此種概念設計的CPU有Intel的Itanium、Transmeta的Crusoe/Effineon等,此種技術學名上稱為VLIW(Very Large Instruction Word),不過HP與Intel對此另有其稱:EPIC(Explicitly Parallel Instruction Computing),但意義相近。

| 《圖一 Transmeta的Effineon處理器與前一代的Crusoe處理器相同皆採VLIW架構,但Effineon將指令載入的平行寬度再提升,從128-bit增加至256-bit》 |
|
<資料來源:Transmeta.com>
但是,VLIW作法的缺點是要從程式編譯過程中就要改變,且必須搭配能將指令達到最透徹平行化拆解的最佳化編譯器(Compiler,軟體),才能完全發揮VLIW架構的功效,現有以傳統方式編譯完成的程式無法獲得發揮,必須用最佳化編譯器重新編譯(Recompile)才行。或者是運用即時性的動態轉譯器(軟體),電腦執行時轉譯器常駐於系統內(多在記憶體中),把即將要執行的程式立即進行平行拆分的轉化動作,再送給VLIW CPU執行,此種轉譯軟體目前常見的有Transmeta的CMS(Code Morphing Software)或Intel的IA-32 EL(IA-32 Execution Layer)。
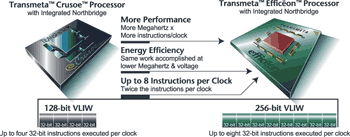
| 《圖二 Transmeta的VLIW執行架構設計是每個指令32-bit寬,Crusoe一次能載入四個指令,而更先進的Effineon可載入八個》 |
|
<資料來源:Transmeta.com>
系統層面的分拆加速:SMP、NUMA
平行加速的作法不僅於此,RISC、UNIX陣營也有其作法,即是朝SMP(Symmetric Multi-Processing)對稱性多處理的架構發展,事實上相對於SMP的是ASMP(ASymmetric Multi-Processing)非對稱性多處理,兩者的差別是ASMP在運算(CPU)、儲存(Memory)、通訊(I/O)等各系統環節都設置執行單元以求加速,但經實際證明成效不彰,而SMP則只在運算(CPU)環節不斷增加執行單位,此方式成為今日高階伺服器的主流架構。
SMP作法是讓一部電腦擁有多顆CPU,而程式如何拆分、派送給各CPU執行是由OS負責,且CPU間若需要協調溝通是透過記憶體來達成,這也是多執行緒(Multi-Threading)的執行架構,一顆CPU可處理一個執行緒。
多執行緒作法原本不適合PC,因為PC程式多數是以單執行緒的方式編譯而成,即便在多執行緒的系統內執行也無法加速(僅在一顆CPU上執行,其餘閒置),所以SMP架構初期只在大型、高階的系統上使用(如UNIX Server上的軟體),然而在Java程式流行後,多數程式都已改採多執行緒的方式開發、編譯,所以SMP作法在PC上也日漸可行。
更平心而論,無論Superscalar、VLIW、SMP等都需要倚賴編譯器的支援才能更有效發揮,只是倚賴程度的多寡有別,Superscalar倚賴最小、VLIW倚賴最高、SMP居中。此外作業系統的良善與否也會多少影響已進行多執行緒編譯後程式能否在SMP硬體系統中徹底發揮。
然而SMP也有其困擾,SMP架構無論有多少顆CPU,都維持著單一作業系統、單一記憶體,記憶體成為整體系統的效能瓶頸,為改善效能CPU與記憶體間採行Crossbar方式的連接,之後衍生出了NUMA(Non-Uniform Memory Architecture)架構,將實體記憶體進行多塊拆分配屬,但邏輯上仍維持以單一的作業系統在運行。
此外,為了降低CPU對記憶體的存取,現今的CPU都內建著L1、L2 Cache,使得CPU間的溝通不見得非透過記憶體不可,透過L2 Cache亦是可行,CPU間透過L2 Cache溝通資訊,會依循MESI協定(MESI cache coherency protocol)來運作,將Cache分區塊進行四種運用狀態(Modified、Exclusive、Shared、Invalid)的標示以利溝通,且在L2 Cache有寫入改變時,會自動對應改變記憶體的資料,或利用離峰時間再進行改變,立即改變者稱為Write Through,離峰時改變者稱為Write Back,今日為求系統高效能多半選擇Write Back設計。此種用Cache溝通取代記憶體溝通的方式被稱為cc-NUMA(Cache Coherent NUMA)架構,不過這只是溝通方式的改變,運作本質上依然是NUMA架構。
既然CPU間改透過Cache溝通,且Cache多已內建在CPU內,那麼若使用更精密的半導體製程工藝,就可在單一裸晶(Die)上同時置入兩顆CPU,且CPU間可透過Cache進行溝通,如此不僅CPU間的溝通能更快速(直接在精密的晶圓電路上傳遞,省去用CPU外的慢速線箔),SMP系統也能以更小的體積實現,此即稱為雙核(Dual Core)處理器,IBM於2001年率先以此種方式開發出Power4 CPU(晶片上有兩個前一代的Power3核心,並進行再強化設計),且只要製程技術再精進,未來即可成就出多核處理器。
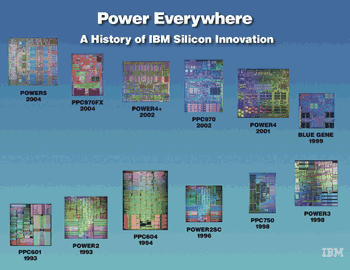
| 《圖三 IBM的Power4開啟雙核追隨風,往後的Power4+、Power5也一樣具備雙核設計》 |
|
<資料來源:IBM.com>
在IBM推出雙核後,其他業者也加緊仿效學習,2004年HP推出雙核的PA-8800(兩顆PA-8700核心),Sun推出雙核的UltraSPARC IV(兩顆UltraSPARC III),而今AMD、Intel也推出雙核的Xeon、Opteron,甚至全系列x86晶片(指IA-32、AMD64、EM64T)都在未來逐一落實雙核化設計。
雙核、多核是運用製造工藝而有的加速作法,而Intel則在設計上構想出另一種平行加速技術,由於Intel工程師發現CPU內除了暫存器最忙碌外,核心的相關單元與資源是處在相對閒置,為了讓相關單元與資源更有效的利用,因此在CPU內設置了第二套暫存器組,如此在核心資源不衝突時兩套暫存器可同時運算執行,以此獲得加速,此稱為HyperThreading(超執行緒),具此種概念技術的除了Intel CPU外還有IBM的Power5,IBM稱為Multi-Threading,且在設計增加了核心資源用量偵測、調度,以及衝突排解等功能,使此種技術獲得更有效發揮[1]。
不僅資訊系統需要雙核,就連繪圖系統、通訊系統、儲存系統也有需求,例如nVIDIA提出的SLI(Scalable Link Interface),以及ATI提出的Cross Fire,都是運用兩顆以上的GPU(Graphics Processing Unit)協同分工所成就的更高加速法,而PMC-Sierra所推出的RM11200網路處理器(Network Processor),內部也是由兩個MIPS64核心所構成,該晶片可用於Switch、Router或儲存設備中。此外EMC的高階網路型儲存系統:Symmetrix,也是用上八十顆的PowerPC晶片,在單一完整系統內有如此高的CPU用量,相信未來也必然迫切換用雙核。

| 《圖四 PMC-Sierra的RM11200雙核晶片,內有兩個MIPS64(64-bit)核心,此類運用不需浮點運算,所以RM11200內也無浮點運算單元》 |
|
<資料來源:PMC-Sierra.com>
雙核成功後,多核計畫也在各家的規劃中,Sun方面對於多核計畫稱為高通量運算(Throughput Computing),過去已運用初步技術研發出MAJC(Microprocessor Architecture for Java Computing,諧音Magic)晶片,並用於Sun自身的XVR-1000、XVR-4000等專業工作站級繪圖卡中。
SMP強調一致性集中,MPP、Cluster強調寬鬆
談論了這麼多,其實都是想辦法在單一運算系統上力求平行加速,不是在CPU內想辦法平行執行,就是希望用多顆CPU來平行執行,即是在晶片或電路板的層面推展平行化,然而還有一種平行化手段,那就是將多部電腦進行串連,將工作拆分成數份後交付給多部電腦同時運算,一樣可以加速獲取答案,此即是平行處理,過去此方式的架構代表為MPP(Massively Parallel processing)巨量平行處理,但近年來則又多了Cluster(叢集)可用。
先就MPP來說明,MPP與SMP不同,SMP是多顆CPU共享單一記憶體、單一作業系統,但MPP是各顆CPU擁有其獨自的記憶體及作業系統,而硬碟、I/O等部分依然保持單一共享,所以MPP系統從外觀而言仍多是單一完整機身,如IBM的AS/400(今日稱eServer iSeries)迷你電腦,或NCR/Teradata伺服器,或Cray XT3超級電腦(體積龐大,由多個機櫃組構而成)等。

| 《圖五 Cray的XT3超級電腦使用MPP架構,單一系統可達200~3000顆CPU,XT3的CPU為AMD Opteron,MPP作業系統為Cray自有的UNICOS/lc》 |
|
<資料來源:Cray.com>
MPP其實是資源共享度低於SMP的架構,而Cluster的設計又比MPP更寬鬆,連硬碟部分也不共享,多部獨立電腦僅以I/O相連,如此有優點也有缺點,優點是各部電腦的規格、組態不必一致性要求,串連中的A電腦可以是單CPU的系統,B電腦則可以是四顆CPU的系統(若B電腦未參與叢集串連則等於是一部SMP架構的電腦),缺點是各電腦間的溝通速度不如MPP,想以追加電腦數目的方式來獲得平行效能擴展,其擴展瓶頸經常發生在I/O傳輸上。
不過,Cluster是今日的新主流,理由無他,由於x86伺服器的價格效能比不斷飛躍成長,以多部x86伺服器串連而成的Cluster也能獲得低廉且優異的效能,此優點遠勝其缺點,因此Cluster逐漸受到重視。
但是,現階段推展Cluster也一樣有隱憂,情形與VLIW架構完全相同,程式若不能重新最佳化編譯就不能在Cluster上發揮功效,所以Cluster初期都只在科學研究、重度工程運算等高效運算(High Performance Computing;HPC)領域中使用,然而商務運算界也希望重用Cluster的平價、高效優勢,試圖在Cluster系統上建立商務執行平台與應用程式,如Oracle提出的RAC(Real Application Cluster)即是最明顯的例子。
網格運算:更寬鬆的系統型態、連接型態
Cluster在系統相連性上已是比MPP寬鬆,但如今又有比Cluster更寬鬆的作法,此即是網格運算(Grid Computing亦有人稱棋盤式運算),Cluster必須是各機都採行相同的作業系統,且各獨立電腦間的連接拘限於區域內,即是用Gigabit Ethernet(Gigabit級乙太網路;GbE)網路、Infiniband、或Fibre Channel(光纖通道;FC)等方式相連,必須在數公尺至數百公尺內完成連線,而目前多半在數十公尺。
至於Grid Computing,強調的是「異質、分散」,所謂「異質」即是各電腦可以使用不同的硬體及作業系統,以及各電腦間可以使用不同的方式相連,如A電腦連至B電腦用Ethernet(區域網路),B連到C用Internet(廣域網路),C連到D用WiFi(無線區域網路),而既然可用各式網路相連,也就不拘限在同一機房內連接,A電腦在甲地,B電腦在乙地,並用Internet相連,也依然可視為同一運算系統,這即是所謂的「分散」,所以Grid Computing也被人稱為異質分散式運算[2]。
Grid化的好處正是不拘泥地點與系統型態,最寬鬆的連接卻也帶來另一種好處,由於今日Internet無遠弗屆,有成千上萬的電腦與Internet相連,如此即可視為一個龐大、連續的運算體,並在此運算體中幾乎無限制的取用運算資源、儲存資源。
最有名的例子就是Berkeley大學的SETI@HOME計畫,該大學運用電波望遠鏡來尋找外太空是否有生物(尋找外星人),將電波發射至外太空,然後接收電波的反射波,再對反射波進行分析運算來求取答案,而分析運算需要大量的高階電腦才能及時求出結果,不幸的是電腦申購預算遭刪,所以該計畫的研究員就自行撰寫一個螢幕保護程式(Screen Saver),號召網友下載安裝,如此安裝者的電腦一旦閒置至螢幕保護程式執行時,便會暫借電腦的運算及儲存資源,以分攤方式協助電波解析運算。
透過Internet上多部電腦的分擔運算,一樣可以快速求取答案,這就是Grid Computing,不需要在意幫助解析運算的電腦位在何處,也不需要在意電腦是UNIX還是Windows(只有安裝螢幕保護程式前需要知道),任何類型的電腦都可以幫助運算。
也因為可從廣大且近乎無限的Internet上調度運算及儲存資源,就像是個龐大的運算發電廠般想用多少就有多少,所以也被人稱為Utility Computing(公用運算),如同電力公司、自來水公司等公用事業一樣,用戶使用運算資源、儲存資源就如同使用源源不絕的電力、自來水一樣,且不用去理會資源取用時的複雜過程,亦即資料在哪運算?儲存在哪等都不需要在意,但依然可自然、正常使用,如同不需要知道自來水廠如何沈澱、殺菌,電廠如何機組規劃、調度等,用戶只要安心、專注於使用就行。
此外,此種資源運算方式不僅想用多少就有多少,不想用時什麼都無須相關準備,因此也被稱為On-Demand Computing(隨需運算),一切只依據適度的需要來啟動、取用。
不過,SETI@HOME畢竟是科學計畫,一般商業用途可行否?2002年IBM為美國一家線上遊戲業者:Bufferfly.Net導入Grid Computing,該業者過去須在營運機房內準備大量的伺服器以因應寒暑假的尖峰遊玩,如今只要準備比離峰稍多的系統及資源,當需要更多運算時則向附近社區的眾多電腦中進行運算與儲存等資源的調度、借挪。
Grid立意雖佳,但眼前依然有四項因素要克服,包括在廣域網路調度時的服務反應時間不確定,資料傳遞時的安全性不確定,資訊系統的資產權歸屬認定開始模糊化,資源分享後的收益拆帳商業模式也還在摸索。
結語
經過上述的演化說明,是否已體會運算架構與技術的新趨勢及箇中真義呢?很明顯的,雙核、多核、多緒等是以既有SMP架構為基礎的更高度化發展,設計上更為集中、一致,相對的Cluster、Grid則是以過去的MPP架構為出發,進行更寬鬆、彈性的發展,包括不拘系統型態,也不拘連線長短。
雖然是兩種不同路線的再進化,但有一點卻是相同不悖的,那就是以積木式、模組化的方式來提升,雙核、多核不就是以同樣的核心為基礎模組所複製成?叢集不也是以多部相同電腦所串連成(雖然允許各部不同組態與規格,但如此容易使某部單機成為整體叢集系統的瓶頸所在,因此多半會力求串連各機的資源與規格能夠一致)。
不僅是Cluster電腦,就連SMP電腦、超級電腦等也都力求模組化設計,刀鋒伺服器(Blade Server)更是模組化的最新典範,只要不斷連接相同一致的系統,就能使效能與資源獲得擴增,模組化的作法也有助於讓硬體組件更為標準化及增加用量,透過標準化與用量的增加才能有效降低成本,快速降價是今日任何資訊硬體都要面對的課題,沒有任何系統能例外。
至於「跳島」,由於相連方式的多樣且不拘,若有某個運算點失效(停電、當機),也可透過其他相連路徑去他處取得運算奧援(跳跨效用),不僅資源運用更為活化澈底,也多了錯誤容忍的彈性。
<參考資料:
[1]HyperThreading、Multi-Threading技術不需倚賴重新編譯就可發揮加速效果,但若能重新編譯則可更快速。
[2]有些資料認為Cluster已允許各機使用不同作業系統,只要相互間的溝通訊息達成默契即可。>
表格:
|
 |
下一代的網格運算正在建構之中,它包括對公用計算能力、 內容管理、應用和存儲的支援。雖然早期的應用還只是理論上的,但是它的商業潛力已經得到了認可。 現在普遍的輿論認為網格運算是未來發展的必然方向,但是向這個新模型的演化必將依賴經濟學。相關介紹請見「網格運算:分散式的優勢」一文。 |
|
不可否認,單純從晶片設計角度考慮,AMD的確做得比英代爾出色,至少從目前來看是這樣子的,但這種設計上的優勢能否轉移成銷售上的優勢?這也許是現在AMD 的痛處所在。你可在「AMD雙核Opteron徘徊在愛與痛的邊緣」一文中得到進一步的介紹。 |
|
電腦不用的時候,除了掛在線上遊戲練功、利用P2P抓歌之外,有沒有更有意義的用途?其實只要下載一個簡單的軟體,立刻就能讓自己的電腦成為「全世界最大的電腦」之一,而且不論是預測全球暖化、研究愛滋病、尋找重力波或是接觸外星人,各種影響人類未來發展的重大突破,都有可能在自己的電腦上被完成。在「分散式運算把電腦變大、拉近科學距離」一文為你做了相關的評析。 |
|
|
 |
|
|
美商甲骨文公司今天發表亞太地區第一波「甲骨文網格指數」(Oracle Grid Index)研究報告,結果顯示亞太地區在網格運算建構要件方面得分相當高。這套網格指數研究是甲骨文推動網格運算的行動之一,主旨在於調查企業對於網格相關技術之接受態度,以了解企業界對於網格運算所採取的進程,並以特定指標加以測量。相關介紹請見「甲骨文第一波網格指數 顯示亞太地區網格運算風潮領先世界」一文。 |
|
在Intel發布採用雙核心架構的Pentium D與Pentium XE之外,身為微處理器龍頭大老之一的AMD也正式將宣布Athlon64 X2雙核心版本的推出,預計將於5/31 Computex Taipei 2005開展當天,正式Release Athlon64 X2這個新版本的雙核心架構版本,Athlon64 X2目前將推出4200+、4400+、4600+以及4800+等。你可在「AMD雙核正式發布─Athlon64 X2 5/31登場、6/7開賣」一文中得到進一步的介紹。 |
|
每年分別於春季、秋季舉辦的英特爾科技論壇(Intel Developer Forum;IDF),一向為高科技電子產業的例行盛事。2004IDF主題為“Converging Technologies,Growing Opportunities ”(匯流中的科技,成長中的機會),眾多Intel產品事業群的高階主管,都為此特別撥出時間,前來台北發表專題演說,並與產業人士及媒體面對面,交換對於產業發展趨勢及英特爾產品新訊的看法。
在「英特爾揭櫫2005概念趨勢」一文為你做了相關的評析。 |
|
|
 |



