本文描述设计MCU和ADC之间的高速串列周边介面(SPI)关於数据交易处理驱动程式的流程,并介绍优化SPI驱动程式的不同方法及其ADC与MCU配置等,以及展示在不同MCU中使用相同驱动程式时ADC的吞吐率。
随着技术的进步,低功耗物联网(IoT)和边缘/云端运算需要更精准的数据传输。图1展示的无线监测系统是一个具有24位元类比数位转换器(ADC)的高精度数据撷取系统。在此我们通常会遇到的问题,即微控制单元(MCU)能否为数据转换器提供高速的序列介面。
本文描述了设计MCU和ADC之间的高速串列周边介面(SPI)关於数据交易处理驱动程式的流程,并介绍优化SPI驱动程式的不同方法及其ADC与MCU配置,以及SPI和直接记忆体存取(DMA)关於数据交易处理的示例代码,最後展示在不同MCU中使用相同驱动程式时ADC的吞吐率。
通用SPI驱动程式简介
通常,MCU厂商会在常式代码中提供通用的SPI驱动程式/API。通用SPI驱动程式/API通常可以涵盖大多数用户的应用,这些代码可能包含许多配置或判断语句。
然而在某些特定情况下,例如ADC资料撷取,通用的SPI驱动程式可能无法满足ADC数据的全速的吞吐率需求,因为通用的驱动程式中有过多的配置,而未使用的配置会产生额外的开销并导致时间延迟。
设计思路与实践架构
我们通常会选择低功耗高性能的MCU作为主机透过SPI撷取ADC的输出数据。但是,由於ADI的SPI驱动程式的数据交易处理命令存在冗馀,因此数据输出速率可能被明显降低。
为了充分释放ADC的潜在速率,本文使用ADuCM4050和AD7768-1进行实验并尝试可能的解决方案。尽管在使用预设滤波器的情况下,ADuCM4050的最大数据输出速率可达256 kHz,但在目前的情况下,其速率被限制在8 kHz。提高输出速率的潜在解决方案包括删除不必要的命令以及启动DMA控制器。以下将介绍这些思路。
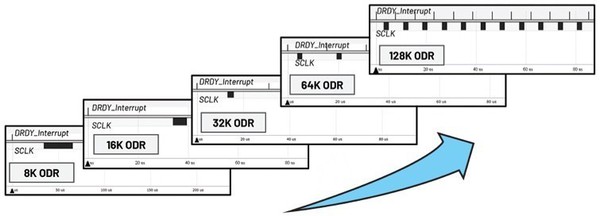
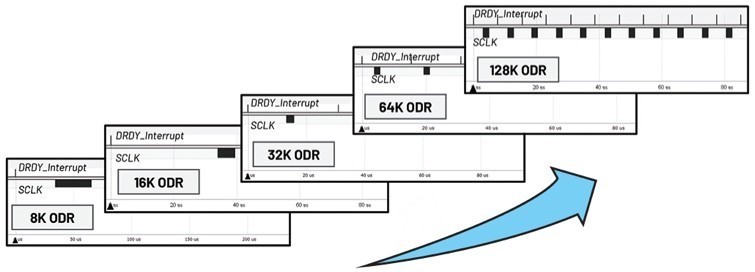
| 图3 : 不同ODR以及DRDY与SCLK之间的关系 |
|
以MCU作为主机
ADuCM4050 MCU为一款主时脉速率为26 MHz的超低功耗微控制器,核心为ARMR CortexR-M4F处理器。ADuCM4050配有三个SPI,每个SPI都有两个DMA通道(接收和发射通道)可与DMA控制器连接。DMA控制器和DMA通道可实现记忆体与周边之间的数据传输。这是一种高效的数据分配方法,可将核心释放以处理其他任务。
以ADC作为从机
AD7768-1为一款24位元低功耗、高性能的Σ-Δ ADC。其数据输出速率(ODR)和功耗模式均可根据使用者的要求进行配置。ODR由抽取系数和功耗模式共同决定,如表1中所示。
(表1)数据输出速率的功耗模式配置
|
功耗模式
|
抽取系数
|
OOR
|
|
快速功耗(MCLK/2)
|
×32
|
256 kHz
|
|
快速功耗(MCLK/2)
|
×64
|
128 kHz
|
|
中速功耗(MCLK/4)
|
×32
|
128 kHz
|
|
中速功耗(MCLK/4)
|
×64
|
64 kHz
|
|
低速功耗(MCLK/16)
|
×32
|
32 kHz
|
|
低速功耗(MCLK/16)
|
×64
|
16 kHz
|
AD7768-1的连续读取模式也是该产品的一个重要特性。ADC的输出数据储存在暂存器0x6C中。一般而言,每次读/写操作之前,ADC暂存器中的数据都需要位址才可以存取,但是连续读取模式则支援在收到每个数据就绪讯号後直接从0x6C暂存器提取数据。ADC的输出数据为24位元的数位讯号,对应的电压如表2所示。
(表2)数位输出码和类比输入电压
|
说明
|
类比输出电压
|
数位输出码
|
|
+全摆幅–1 LSB
|
+4.095999512 V
|
0x7FFFFF
|
|
中间位准+1 LSB
|
+488 nV
|
0x000001
|
|
中间位准
|
0 V
|
0x000000
|
|
中间位准-1 LSB
|
–488 nV
|
0xFFFFFF
|
|
-全摆幅–1 LSB
|
–4.095999512 V
|
0x800001
|
|
-全摆幅
|
+4.096 V
|
0x800000
|
接脚连接示意图
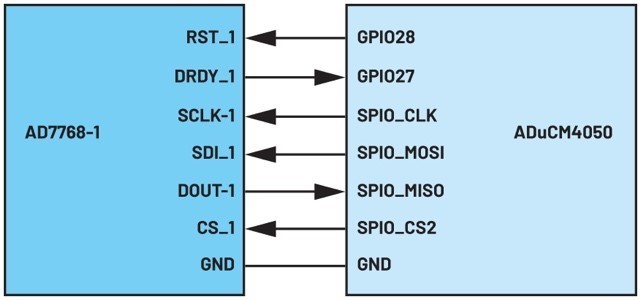
ADuCM4050和AD7768-1组成的数据交易处理示例模型的接脚连接状况,如图4所示。
ADC的重设讯号接脚RST_1连接至MCU的GPIO28,而数据就绪讯号接脚DRDY_1则连接至MCU的GPIO27。其馀接脚则根据通用的SPI配置标准进行连接,其中MCU为主机,而ADC为从机。SDI_1接收MCU发送的ADC暂存器读/写命令,而DOUT_1则将ADC的输出数据发送至MCU。
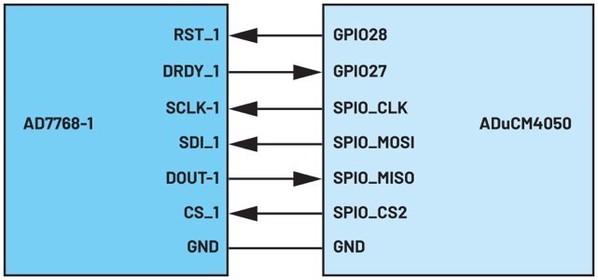
| 图4 : AD7768-1和ADuCM4050的介面接脚连接 |
|
数据交易处理的实现
中断数据交易处理
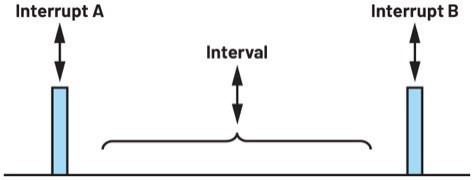
为实现连续数据交易处理,本文将MCU的GPIO27接脚(连接至ADC的DRDY_1接脚)用於中断触发接脚。ADC将数据就绪讯号发送至GPIO27时会触发MCU包含数据交易处理命令的中断回呼函数。如图5所示,数据撷取必须在中断A和中断B之间的时间间隔内进行。
利用ADI的SPI驱动程式可以在ADC和MCU之间轻松实现数据交易处理。但是,由於驱动程式记忆体在冗馀命令,ADC的ODR会被限制在8 kHz。本文尽可能精简了代码以加快ODR,将介绍实现DMA数据交易处理的两种方法:基本模式的DMA交易处理和乒乓模式的DMA交易处理。
基本模式的DMA交易处理
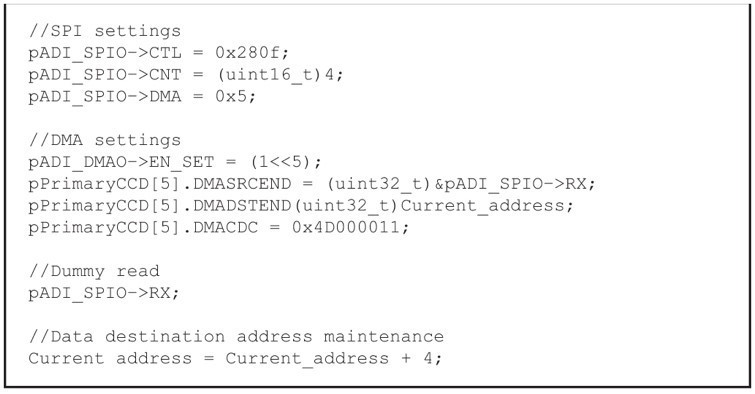
在实现每个DMA交易处理之前需要对SPI和DMA进行配置(叁见图6中的示例代码)。SPI_CTL为SPI配置,其值为0x280f,源於ADI的SPI驱动程式的设定值。SPI_CNT为传输位元组数。
由於每个DMA交易处理只能发送固定的16位元数据,因此SPI_CNT必须是2的倍数。本例设定SPI_CNT为4,以满足ADC的24位元输出数据要求。SPI_DMA暂存器为SPI的DMA致能暂存器,设定其值为0x5以使能DMA接收请求。命令pADI_DMA0->EN_SET=(1<<5)致能第五个通道的DMA,即SPI0 RX。
(表3)DMA结构暂存器
|
名称
|
说明
|
|
SRC_END_PTR
|
来源端指针
|
|
DST_END_PTR
|
目标端指标
|
|
CHNL_CFG
|
控制数据配置
|
每个DMA通道都有一个DMA结构暂存器,如表3中所示。需要指出的是,这里的数据来源位址的结尾(即SPI0 Rx,亦即来源端指标SRC_END_PTR)在整个操作期间无需增加,因为Rx FIFO会自动将暂存器中的数据推送出去。另一方面,数据目标位址的结尾(即目标端指标DST_END_PTR)根据ADI的SPI驱动程式的使用函数计算得出,即目标位址+ SPI_CNT -2。
目前位址为内部阵列缓冲区的位址。DMA控制数据配置CHNL_CFG包括来来源数据大小、来源位址增量、目标位址增量、剩馀传输次数和DMA控制模式等设定,其值0x4D000011按照表4中所述的设定配置。
(表4)控制数据配置0x4D00011的DMA配置
|
暂存器
|
说明
|
值
|
|
DST_INC
|
目标位址增量
|
2位元组
|
|
SRC_INC
|
来源地址增量
|
0
|
|
SRC_SIZE
|
来源地址增量
|
2位元组
|
|
N_minus_1
|
目前DMS周期中的
总传输次数- 1
|
1 (N = 2)
|
|
Cycle_ctrl
|
DMA周期的工作模式
|
基本模式
|
SCLK时脉透过伪读取命令SPI_SPI0 -> RX启动,输出数据透过MISO从ADC传至MCU。MOSI上其它的数据传输可以忽略不计。一旦完成Rx的FIFO填充,DMA请求就会产生进而启动DMA控制器,以将数据从DMA来源位址(即SPI0 Rx FIFO)传输至DMA目标位址(即内部阵列的缓冲区)。值得注意的是,SPI_DMA=0x3时会产生Tc请求。
最後,透过将目前目标位址加4的方式,将目标位址用於下一个4位元组的传输。
请注意,SPI0 DMA通道的pADI_DMA0->DSTADDR_CLR和pADI_DMA0->RMSK_CLR必须在首次中断触发之前在主函数中设定。前一个为DMA通道目标位址减量致能清零暂存器,用於在增量模式下设定每次DMA传输後的目标位址移位(目标位址计算函数仅在增量模式下有效)。後一个为DMA通道请求遮罩清零暂存器,用於将通道的DMA请求状态清零。
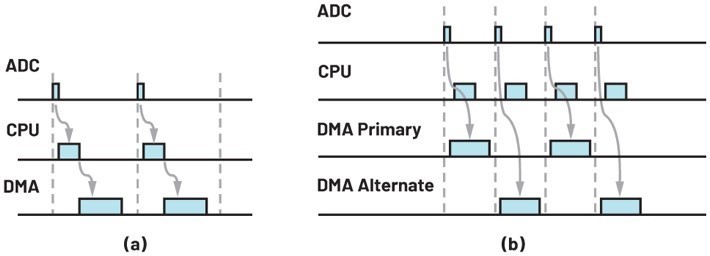
基本模式的DMA交易处理时间图如图7a所示。图中三个时隙分别代表DRDY讯号、SPI/DMA设定和DMA数据交易处理。在该模式中,CPU的闲置时间较多,因此希??DMA控制器在处理数据传输时能将任务分配给CPU。
乒乓模式的DMA交易处理
在执行伪读取命令後,DMA控制器会开始数据交易处理,进而使得MCU的CPU处於空闲状态,而不处理任何任务。如果能够让CPU和DMA控制器同时工作,那麽任务处理就从串列模式转变为并行模式。如此就可以同时进行DMA配置(透过CPU)以及DMA数据交易处理(透过DMA控制器)。
为实现这一思路,需要设定DMA控制器处於乒乓模式。乒乓模式将两组DMA结构进行了整合:主结构和备用结构。每次DMA请求时,DMA控制器会在两组结构之间自动切换。变数p的初始设定为0,其值表示是主DMA结构(p = 0)还是备用DMA结构(p = 1)负责数据交易处理。
如果p = 0,则在收到伪读取命令时启动主DMA结构进行数据交易处理,同时会为备用DMA结构分配值,使其在下一个中断周期内负责数据交易处理。如果p = 1,则主结构和备用结构的作用互换。当仅有主结构处於基本DMA模式时,在DMA交易处理期间对DMA结构的修改会失败。乒乓模式使得CPU能够存取和写入备用DMA结构,而DMA控制器可以读取主结构,反之亦然。
如图7b所示,由於DMA的结构配置是在最後一个周期内完成的,因此在DRDY讯号从ADC传送至MCU後DMA数据交易处理可以被立即执行,使得CPU和DMA同时工作而无需等待。现在,ADC的ODR得到了提升空间,因为整体工作时间已大幅缩短。
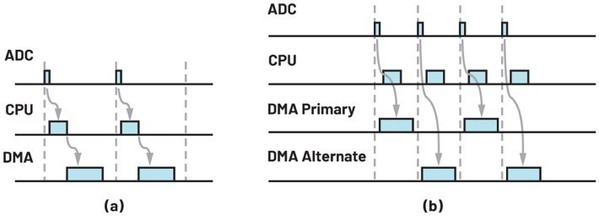
| 图7 : (a)基本模式DMA和(b)乒乓模式的时间图 |
|
中断处理常式的优化
两次DRDY讯号之间的时间间隔不仅包括了中断回呼函数的命令执行时间,还包括了ADI的GPIO中断处理函数的命令执行时间。
当MCU启动时,CPU会运行开机档案(即startup.s)。所有事件的处理函数均在该档中定义,包括GPIO中断处理函数。一旦触发GPIO中断,CPU就会执行中断处理函数(即ADI的GPIO驱动程式中的GPIO_A_INT_HANDLER和GPIO_B_INT_HANDLER)。通用的中断处理函数会在所有的GPIO接脚中搜索触发中断的接脚并清零其中断状态、运行回呼函数。
由於DRDY是本文应用的唯一中断讯号,因此可以对函数进行简化以加快进程。可选的解决方案包括:(1)在开机档案中重新定位目标;(2)修改原始的中断处理函数。重新定位目标表示自订中断处理函数,并替换开机档案中的原始的中断处理函数。
而修改原始的中断处理函数只需要增加一个自订的GPIO驱动程式。本文采用第二种方案修改原始的中断处理函数,如图8所示。该方案只将连接至DRDY的GPIO的接脚中断状态清零,并直接转到回呼函数。请注意,这里需要透过取消选择build target中关於原始GPIO驱动函数的勾选框内容来隔离原始的GPIO驱动程式。
结果
速率性能
假定现在需要读取200个24位元的ADC输出数据,并且SPI位元速率设定为13 MHz。将DRDY讯号和SCLK讯号的接脚连接至示波器,则能透过观察DRDY讯号与SPI数据交易处理(亦即DMA交易处理)启动之间的时间间隔方法,量化本文所述的每种方法对速率的改善程度。这里将DRDY讯号至SCLK讯号开始的时间间隔记为?t,那麽对於13 MHz的SPI速率,测量得出的?t为:
· (a)基本模式DMA Δt = 3.754 μs
· (b)乒乓模式DMA Δt = 2.8433 μs
· (c)乒乓模式DMA(使用优化的中断处理函数)Δt = 1.694 μs
方法(a)和(b)可支援64 kHz的ODR,而方法(c)可支援128 kHz的ODR。这是因为方法(c)的?t最短,进而使得SCLK讯号能够更早结束。如果SCLK讯号(即数据交易处理)能在T/2之前完成(T为目前ADC的数据输出周期),则ODR可实现翻倍。这相对於原始的ADISPI驱动程式可以达到的8 kHz的ODR性能是一次巨大的进步。
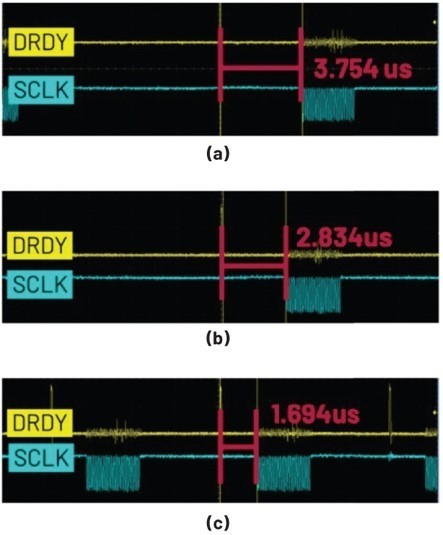
| 图9 : (a)基本模式DMA、(b)乒乓模式,以及(c)乒乓模式(使用优化的中断处理函数)的Δt |
|
使用MAX32660控制AD7768-1
使用主时脉速率为96 MHz的MCU MAX32660控制AD7768-1)时的结果如何?在该情况下,使用优化的中断处理函数的中断设定,可在不使用DMA函数的情况下实现256 kHz的数据输出速率。叁见图10。
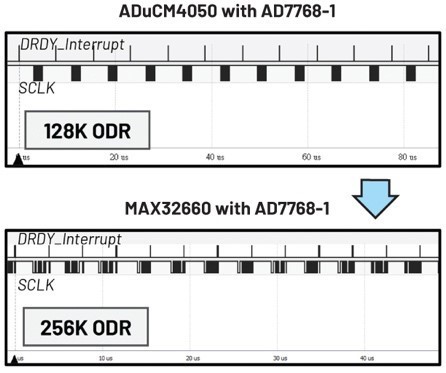
| 图10 : 不使用DMA时MAX32660的ODR |
|
结论
本文利用选定的ADC(AD7768-1)和MCU(ADuCM4050或MAX32660)透过SPI实现了高速的数据交易处理。为实现速率优化的目标,本文简化ADI的SPI驱动程式执行数据交易处理;此外,并提出启动DMA控制器释放核心,也可加快连续数据交易处理的流程。
在DMA的乒乓模式下,DMA的配置时间可透过适当的调度来节省。在此基础上,还可透过直接指定中断接脚的方式优化中断处理函数。在13 MHz的SPI位元速率下,本文提出之方案的最隹性能可达到128 kSPS的ADC ODR。
(表5) 高速SPI连接实现ADuCM405和MAX32660
|
|
ADuCM4050(MCU)
|
MAX32660(MCU)
|
|
数据交易处理
|
未经优化的中断
|
基本模式DMA
|
乒乓模式DMA
|
经优化的中断
|
经优化的中断
|
|
汇流排类型
|
SPI
|
SPI
|
SPI
|
SPI
|
SPI
|
|
主时脉速率
|
26 MHz
|
26 MHz
|
26 MHz
|
26 MHz
|
96 MHz
|
|
DRDY与SCLK
之间的时间间隔
|
6.34 µs
|
3.754 µs
|
2.834 µs
|
1.694 µs
|
1.464 µs
|
|
数据输出速率
|
8 kSPS
|
32 kSPS
|
64 kSPS
|
128 kSPS
|
256 kSPS
|
(本文作者Denny Wang、Sally Tseng为ADI应用工程师)