|
|
| 針對可調式視訊之影像編碼器 |
|
系統晶片設計專欄(13)
【作者: 陳翊豪,莊子德,陳宥任,陳慶曄,陳良基】 2008年01月30日 星期三
|
|
瀏覽人次:【15084】
介紹
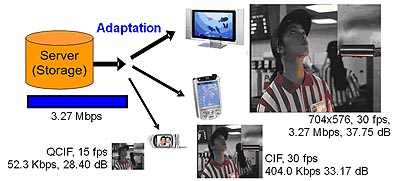
視訊壓縮編碼技術在壓縮率上獲得相當大的成功,此進展也推動了多媒體通訊相關產業的蓬勃發展,然而隨著多媒體應用高度多樣化的需求,使得除了壓縮率之外,視訊壓縮技術的其它功能性也越來越受重視,其中又以抗傳輸錯誤以及可調式視訊編碼尤為重要。鑑於傳統視訊壓縮標準在這些功能性上遭遇相當大的瓶頸,MPEG組織已著手制定未來下一代的視訊壓縮標準:Scalable Video Coding (SVC) [1],希冀能滿足工業界對多媒體功能性多樣化的需求。可調式影像編碼的目的是使單一壓縮位元串能在不同畫面大小、畫面速度以及畫質下都提供最佳傳輸效能如下(圖一)所示,然而其演算法設計實現上也和以往傳統壓縮系統迥然不同。
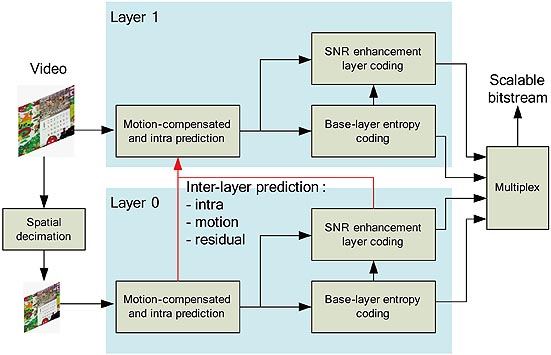
SVC於核心演算法上除了繼承之前H.264的封閉式預測結構的階層式雙向預測畫面 (Hierarchical B-frame scheme),在其開發階段也引進過全新的開放式預測結構的多重層級移動補償式時間濾波 (Multi-level motion-compensated temporal filtering),這兩種演算法皆可以達成影像撥出速率的可調性並同時提升整體影像壓縮的效率。另外為了達成影像解析度的可調性,SVC採用了一個接近金字塔型的編碼方式(Pyramid coding),同時為了移除各個不同畫面解析度間的多餘資料,三種畫面層級之間的預測 (Inter-Layer Prediction )工具一起被採用來增進壓縮效率。最後為了讓產生的影像品質也可以具有可調性,也就是說,解碼器端接收到越多位元串資料,就可以讓使用者觀看到越好的影像,SVC提供了三種不同精度的畫面品質可調性。一個完整的SVC編碼器可以如下(圖二)所示,基本上SVC編碼器是建構在原本的H.264/AVC之上,並引進了上述提到支援影像可調性的編碼工具。在SVC編碼器的硬體實現上,有幾個主要的設計要點,分別是晶片的外部記憶體頻寬、晶片的運算量、所需運算時脈數和內部記憶體頻寬。在下文中,我們將整理幾種針對可調式編碼器實現的創新技術及設計概念來解決上面的設計要點,分別是巨集區塊間的Level C+資料重複使用(Level C+ Data Reuse)[3]、畫面層級的資料重複使用 (Frame-Level Data Reuse)[4]和時間和空間上的階層式移動估計(Spatial-temporal Hierarchical motion estimation)[5]。
巨集區塊間的等級C+資料重複使用
圖三(a)中所示為目前在移動估計硬體模組中最為普及的等級C資料重複使用架構 (Level C data reuse scheme)[2],它可以達到水平方向的搜尋區域 (Search Region)資料的重複利用。然而隨著影像應用的解析度日趨增加以及雙向式畫面預測帶來的外部匯流排頻寬增加量,傳統的等級C架構已經無法滿足系統設計者的需求,然而在巨集區塊層級中同時具有完整的水平及垂直方向資料重複利用且具有最低頻寬的等級D架構會帶來過高的內部記憶體使用量[2],因此我們提出了等級C+資料重複使用架構 (Level C+ data reuse scheme)在兩者之中取的一個平衡[3]。如圖三(b)所示,等級C+架構會需要比等級C架構多出一部分的內部記憶體容量,但是可以相對的提供部分垂直方向的資料重複使用,以圖三(b)為例,上下兩條橫向的巨集區塊將可共用搜尋區域,約可減少50%的外部匯流排頻寬。
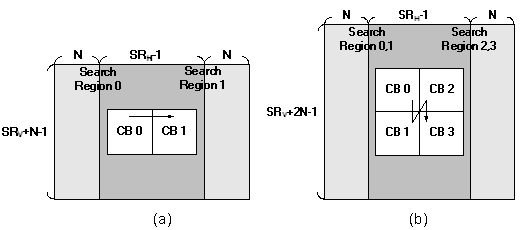
| 《圖三 (a)傳統的等級C資料重複使用 (b)等級C+資料重複使用》 |
|
畫面層級的資料重複使用
畫面層級的資料重複使用 (Frame-Level Data Reuse) 主要是針對SVC中大量使用的雙向式畫面預測 (B-frame) 提出的[4]。不論是開放式架構的移動補償式時間濾波(MCTF)或是封閉式架構的階層式雙向預測畫面 (Hierarchical B-frame scheme),都因為使用了雙向式移動估計,使的移動補償式時間濾波器以及移動估計/移動補償處理引擎對於外部記憶體的影像資料讀取加倍,這不僅讓外部記憶體的功率消耗因讀取次數上升而增加,更會造成系統對外部匯流排(External bus)的負載過重或是產生匯流排上資料壅塞的情形出現,使整個視訊編碼解碼系統的工作效率下降。
我們針對雙向式畫面預測的特性提出了畫面層級的資料重複使用,原本雙向式畫面預測的資料流程如圖四(a)所示,每一張目前畫面的預測皆需要讀取前後兩張參考畫面的資料;然而這些參考畫面實際上會分別被前後的目前畫面所使用到所以會造成兩倍的讀取頻寬,因此我們提出了圖四(b)的雙張目前畫面架構(Double current frame scheme, DCF)使參考畫面只需要被讀取一次而降低了接近一半的外部匯流排頻寬。另外為了提升在移動補償式時間濾波架構中的效率,圖四(b)的架構也可被延伸為圖四(c)的架構以進一步降低所需要的匯流排頻寬。此外為了能夠配合多重階層(Multi-Level)編碼中不同階層對應到的畫面群集(Group of Pictures, GOP),上述各種畫面層的的資料重複使用架構更可混合使用來達到最低的外部匯流排頻寬。
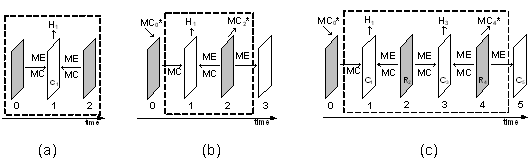
| 《圖四 (a)傳統雙向式畫面預測、(b)Double Current Frames (DCF)、(c)Extend-DCF的示意圖。》 |
|
時間、空間上的階層式移動估計
由於SVC編碼器必須對所支援的各種畫面解析度接進行預測編碼的處理, 另外還要配合階層式雙向預測畫面和多重層級移動補償式時間濾波架構中的不同畫面群集大小,我們提出了圖五中所示的時間、空間上的階層式移動估計演算法[5]。有別於傳統的階層式移動估計,我們使用了各個畫面解析度中得到的最好的移動向量 (Motion vector)來預測下一個畫面解析度中的移動向量,並以此為起點對移動向量進行一定範圍內的修正,另外還會統計屬於同一條巨集區塊的平均移動向量,使用中央移動資料暫存區 (Centric moving row buffer)來進行巨集區塊間的資料重複使用以進一步減少移動估計的運算量和搜尋資料的讀取量。另外在內部記憶體部分,我們提出了可重組化的內部搜尋範圍記憶體的配置方式,這是因為單向預測的畫面在多重階層的預測架構中會和時間距離較遠的畫面進行移動估計,而雙向預測的畫面是和時間距離較近的參考畫面進行移動估計,所以可以將一個雙向式畫面預測所使用到的兩塊搜尋區域記憶體可以合併成一個提供更大搜尋範圍的記憶體給單向預測的畫面使用,讓單向預測的畫面可以擁有比原來更好的預測品質。
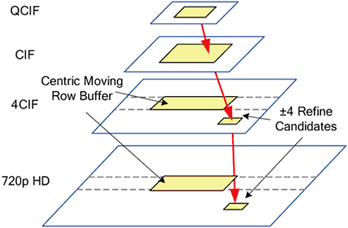
| 《圖五 時間和空間上的階層式移動估計的演算法示意圖,圖中的黃色區域為被讀取的搜尋區域資料,紅色箭頭代表了被放大的移動向量。》 |
|
合併的移動補償時間濾波和移動估計硬體架構
綜合了上述提到應用的SVC的硬體設計技術及概念,我們提出了一個合併的移動補償時間濾波和移動估計硬體,其細部架構如(圖六)所示,配合我們於[6,7]中所提出的交錯式巨集區塊運算排程(Interleaved MB-pipeline schedule)以及提升步驟(Update stage)架構,此硬體可分別支援開放式架構的移動補償時間濾波以及目前SVC採用的階層式雙向預測畫面等多種預測方式,並且節省了其中需要的暫存記憶體容量。
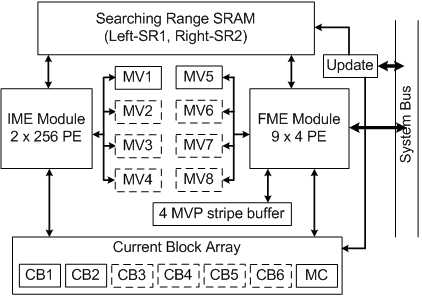
| 《圖六 合併的移動補償時間濾波和移動估計硬體示意圖,實線部分為所需要的資料暫存記憶體,虛線部分為採用交錯式巨集區塊運算排程後可節省的暫存記憶體。》 |
|
晶片實做
這顆晶片使用了台積電18微米製程,晶片大小為3.824x3.568 mm2頻率為60MHz。此晶片的功能特色如下(圖七)所示,量測到的功率為410mw,晶片如(圖八)所示。(圖九)中我們詳列了本晶片在各種運算模式下所需要的系統頻寬以及運算時脈數。在減少外部記憶體頻寬方面,藉由我們提出的畫面層級資料重覆使用,針對(5,3)移動補償時間濾波來看,約有13%至36%的頻寬減少,此外也可以套用在其他的雙向式預測畫面架構上,都可有著不錯的頻寬減少量。表二中也列出了各種編碼架構需要的運算時脈數,從29MHz對應的IPPP w 1-ref到所需時脈數最高的4 Level 5/3 MCTF的59.7MHz。同時各種架構的系統頻寬也從最低的24.05MByte/sec分布到最高的50.09MByte/sec,這兩個數據提供了這顆晶片運算量上的可調性,而上層的系統控制模組將可根據目前所擁有的資源,來調整最適合的編碼標準或編碼選項,讓整個編碼系統能在壓縮頻寬(bit-rate)、壓縮畫面品質(distortion)和系統運算量(computation)中取得最佳的平衡點。
|
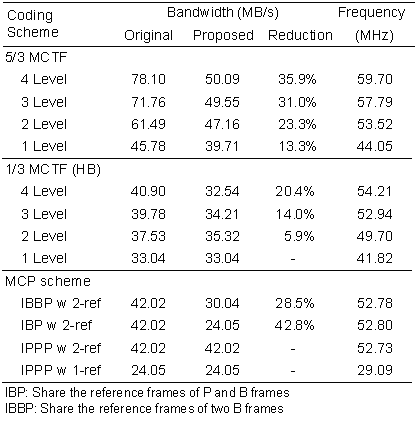
| 《圖九 本晶片在不同運作模式下所需要的頻寬以及運算時脈數的比較表。表中的Original是指直接實作的理論結果》 |
|
結論
在這裡我們以一個可同時支援移動補償時間濾波和移動估計硬體作為雛形來實驗上述提到的一些針對SVC的硬體設計概念,此硬體不僅可以提供原本SVC的預測模組中隱含的影像撥出速率上的可調性,更可以配合不同種預測架構給予硬體運算上消耗功率或是所需運算時脈上的可調性,這將會是之後SVC相關編碼器或是解碼器在設計實現上的一大特色。
參考文獻
[1]iko Schwarz, et al., “Overview of the scalable video coding extension of the H.264/AVC standard,” Transaction on circuits and systems for video technology, pp1103-1120, Sep. 2007.
[2]J.-C. Tuan, T.-S. Chang and C.-W. Jen, “On the data reuse and memory bandwidth analysis for full-search block-matching VLSI architecture,” IEEE Transcations on Circuits and Systems for Video Technology, vol. 12, no. 1, pp. 61-72, Jan, 2002.
[3]C.-Y. Chen, C.-T. Huang, Y.-H. Chen, and L.-G. Chen, “Level C+ Data Reuse Scheme for Motion Estimation with Corresponding Coding Orders” IEEE Transcations on Circuits and Systems for Video Technology, vol. 16, no.4, pp. 553-558, Apr, 2006
[4]C.-Y. Chen, Y.-H. Chen, C.-C. Cheng and L.-G. Chen, “Frame-level data reuse schemes,” in Proceedings of ISCAS 2006, Kos, Greece, pp. 5571-5574, May, 2006
[5]Y.-H. Chen, T.-D. Chuang, Y.-J. Chen, L.-G. Chen, “Bandwidth-efficient Encoder Framework for H.264/AVC Scalable Extension,“ in Proceedings of ISM 2007, Taichung, Taiwan, Dec, 2007.
[6]Y.-H. Chen, C.-Y. Chen, C.-C. Cheng, L.-G. Chen, “Scalable Rate-Distortion-Computation Hardware Accelerator for MCTF and ME,“ in Proceedings of 2006 IEEE International Conference on Multimedia & Expo, Toronto, Canada, July, 2006
[7]C.-C. Cheng, C.-Y. Chen, Y.-H Chen and L.-G. Chen, “Analysis and VLSI architecture of update step in motion-compensated filtering,” in Proceedings of ISCAS 2006, Kos, Greece, May, 2006
|