除了使用電話或手機之外,你會如何連絡親朋好友、同事、或客戶?是ICQ、Yahoo/MSN Messenger、還是e-mail?
目前在一般使用電腦的族群中,有相當高的比率以e-mail作為最主要的通訊工具。相信大多數人都有這樣的經驗:每天上網收e-mail就開始了一天的惡夢,數十封信中可能只有極少數是真正感興趣的...。根據統計,截至2003年底為止,已有超過50%的電子郵件是垃圾郵件,平均每人每天收到超過3封以上,其中大部份屬於產品廣告或成人情色類。
更嚴重的是,如果你在網路上還訂閱(subscribe)了一些電子報(newsletter)、加入了討論群組(mailing list)、或是你把郵件地址(e-mail address)直接公布在網頁或討論區上,那麼,恭喜你!你很可能會收到更多的垃圾郵件,因為你的郵件地址已經早已被收錄在電子郵件名單中,廣為流傳...
隨著電子郵件廣泛的使用,垃圾郵件(SPAM;Solicited Pornography and Marketing)造成個人時間浪費,以及網路使用效率不佳,不僅對個人使用者造成困擾、降低生產力,同時對企業、甚至是整體網路環境都造成不小的衝擊。
什麼是e-mail SPAM?
通常我們將不請自來的(unsolicited)、大量寄出的(bulk)廣告信(commercial e-mail)稱為垃圾郵件(e-mail SPAM or junk e-mail),而這些寄出垃圾郵件的人稱為spammer。
究竟為什麼會有那麼多垃圾郵件呢?首先,由於免費的郵件地址取得容易,許多spammer可以註冊多個地址備用,一方面身份不易曝光,另一方面萬一郵件地址被封鎖,還有其他地址可以繼續寄信。
其次,因為spammer寄信的成本很低,只須收集郵件地址清單或選擇一個大量寄件軟體 (bulk mailer),就可以開始寄信了,但多數收件者卻必須先收下這些垃圾,然後一封封手動殺掉,相對上收信成本就很高。
而最重要的一項因素其實是e-mail的傳輸協定SMTP (Simple Mail Transfer Protocol) [10] 太過於簡單,因而存在許多漏洞,並可能遭攻擊,垃圾郵件的問題才會日益嚴重。
SMTP的缺點
首先我們來看看 SMTP的基本運作原理。如圖一所示,當寄件者寄出一封信時,mail server會先檢查DNS server上的MX (Mail eXchanger) record,得知收件地址該往哪裡寄,然後一站一站轉寄(store-and-forward)到收件者的 mail server,放入信箱。等到收件者想收信時,再用mail client透過POP3 [12]或IMAP4 [1]連上mail server,收下信件。這種作法原本就是為了確保信件一定能送達收件者手中。但由於 SMTP 過於簡單,並未做好寄件者身份驗證的工作,因此,才會造成 spammer可以假造寄件者地址,隱藏真實身份,避開一般網域的mail server檢查,直接寄給收件者的 mail server。
![《圖一 電子郵件傳輸過程運作原理示意圖 [20]》](/art/2004/01/151401547781/p1.gif)
| 《圖一 電子郵件傳輸過程運作原理示意圖 [20]》 |
|
究竟垃圾郵件是怎麼辦到的?
首先,許多的“spambot”(robot for spammer)不斷在網頁或討論區中自動收集郵件地址。如果再經過假的自願退出名單(opt-out list)或是其他方式確認後,更可篩選出正確有效的電子郵件名單。而這樣的名單,不但的確存在,而且還很容易以低價買到。
另外,因為SMTP並沒有確認寄件者身份,spammer寄信時就可以假造寄件人位址 (sender address),或是利用 open mail relay或open proxy server1來轉信。因此,spammer可以躲開身份認證,肆無忌憚的發廣告信。
注釋:
Open Mail Relay指的是一個SMTP (mail) server並未限制轉寄(relay)對象,因此,所有人都能透過它來轉寄信件。而 Open proxy server指的是一個proxy server並未限制任何人經由它來存取資料,因此SMTP packet也可能透過open proxy來轉寄信件。
常見的系統解決方法(heuristic-based approach)
針對垃圾郵件問題,目前最常見的解決辦法大多採用過濾 (filtering)的方式,分別在伺服器(server)及用戶端(client)進行篩選,但是作用各不相同。 Server端所須要的filter是儘早將大家所認定可能的spam擋下來。如果server已經把信收下來,到了client才發現是SPAM,則從 server傳輸到 client的頻寬資源就浪費了。因此,有各種收集SPAM sample的方法,如: DCC [2]、Vipul's Razor [19]、peer-to-peer spam filtering [18]...等,這些都能早期發現可疑e-mail的特徵,並將其篩選出來。
但是有些情形必須在 client 過濾,例如:每個人的白名單都不太一樣,比較難在server統一做個整體的白名單。因此,個人化的過濾需求就比較適合在client做,以免將頻寬浪費在client-server的溝通上。以下分別就各種常見的過濾方法加以探討,其中黑名單/白名單/灰名單是屬於header-based,也就是只看header就能判斷出來; 而rule-based關鍵詞比對主要是屬於content-based,必須看到內容才能判斷出來。
黑名單 (black list) - 攔下可疑人物寄出的信
常見的黑名單有 Realtime Blackhole List (RBLs) [11]、open mail relay、open proxy server等。其原理基本上都是將可疑的主機名稱或是IP address,以 DNS record形式存在 DNS server上。如果可疑人物在黑名單中,則查詢該筆紀錄時,會傳回特定的值,例如“127.0.0.2”,如此一來,便可辨認出可疑人物。
不過這種作法的缺點是,各地的spammer可能不相同(有區域性,如:不同語言的特性),因此必須將各地的名單都納入,才能有效全面防堵。而且黑名單基本上較難維護,因為spammer只要假造郵件地址,或是不斷換新的身份來寄信就很難抓到。
白名單 (White List) - 只讓好人寄出的信通過
另一種作法就是將每個人所認為沒問題的人加入白名單,從這名單寄出的信,就自動讓它通過。其他不認識或是第一次連絡的寄件地址就須要收件者按鈕確認,才會被加入白名單。
這個方法的缺點是,第一次連絡的人,例如新認識的朋友或是失散多年的好友,就必須要經過身份認證的手續,對使用者來說會比較麻煩。
灰名單 (Grey Listing) [7] - 扣留所有陌生人寄出的信
最近還有人提出一種新的方法,觀念上很簡單,就是從沒看過的郵件地址寄出的信,一律先拒收。因為正常信件會重寄,所以經過一段時間的delay後還是會收到。但是大部分大量寄信軟體比較笨,沒有考慮(也不須考慮)重寄的問題,因此一旦被拒收後,那封信就不會再重寄,所以可以擋掉一些垃圾信。
此法通常會搭配黑名單/白名單,但缺點是,所有人只要還沒被加入白名單的,都會被 delay,因此寄件效率會變差。它的假設是,如果SPAM的比例遠高於正常郵件,則SPAM被延後的時間加起來,就遠大於正常郵件被delay的時間,就可以認為有效果。
郵件規則(Rule-based) - 關鍵詞比對(keyword spotting)
通常現有的實際電子郵件過濾系統大多採用經驗式規則(heuristic rule-based)的方法,以易懂且易修改的郵件過濾規則(rule),來偵測某些關鍵詞的出現。只要該信出現某些字詞的組合,就認為它一定是垃圾信。這種作法,一開始效果還不錯,因為垃圾信常常為了達到其吸引客戶的目的,喜歡以誇大聳動的標題來引起人們注意。例如,通常信件中出現“免費”、“便宜”的字眼,大部分都是一種廣告信。然而,隨著過濾技術的進步,垃圾郵件偽裝的技巧也逐漸進步,單憑關鍵詞要寫出能精準分辨正常與垃圾郵件的規則,越來越困難,而且垃圾郵件時常改變,規則必須常視需要更新。例如,spammer可能會以同義詞或是比較模糊的字眼來代替一些比較敏感,容易被過濾的字詞。
當然,模糊的字眼吸引力就比較小了,但是只要有一小部份人被騙或是不小心點選了,則spammer廣告曝光的效果就達到了。畢竟spammer成本太低,所以比起傳統廣告所要求的曝光率,可以寬鬆許多。
其他的經驗式法則
其他常用的方法包括:根據郵件標頭欄位(header fields)、根據寄信流量等來判斷是否為垃圾郵件。例如:有些大量寄信軟體在發信時,會假造一些欄位,如:寄件人、收件人、寄信時間...等。所以我們可以根據這些欄位來判斷是否為垃圾郵件,例如:收件人如果根本不包括你,那一定是垃圾信。但是,密件副本 (Bcc)、mailing list寄出的信、或是 all users 這一類的帳號就不適用了。
此外也可以由郵件伺服器來統計出寄件者每天發出的信件數量、大小等,這也是一個特徵。通常在寄信時,server還會先利用DNS反查,檢查寄件者的IP address是否如其所述是合法位址。然而寄件者身份的查驗就比較困難了,目前仍有IRTF(Internet Research Task Force)的ASRG(Anti-SPAM Research Group) [9] 在研究各種改進、或取代現有SMTP protocol的方法。
學術研究上文件分類的方法 (classification-based approach)
同樣是做郵件過濾或郵件分類,在學術界卻有著不同的解決方式。在研究上大部分是以傳統的文件分類 (text categorization)方法,運用機器學習(machine learning)的技術來完成。基本上郵件可看成是一份文件 (document),包含了一些結構化的欄位,如:寄件者、收件者、主旨...等,以及非結構化的本文,也就是郵件內容。只要從大量資料中統計出郵件可能出現的字詞特徵,找出不同文件的相似程度(similarity),就可以套用文件分類的一些方法,如:TF-IDF (Term Frequency-Inverse Document Frequency)、Naive Bayes、SVM...等,來分辨是否為垃圾郵件。
雖然機器學習的方法準確率很高,但也存在著一些缺點。例如:
- (1)機器學習須要大量的訓練資料(training data),尤其在SPAM特徵不斷改變的情形下,須要更多樣本才能學習出個別特徵的差異。
- (2)spammer也在不斷學習:我們找出如何過濾的方法,spammer就會想出逃避的方法,如(表一)所示。
- (3)個人化(personalization)的趨勢:垃圾郵件的認定非常主觀,每個人感覺都不盡相同。有些廣告大部分人認為是SPAM,但某個人可能很喜歡。因此,SPAM的概念如果單從一個 server 的角度來看,未免太狹隘。因此,個人化(personalized)電子郵件過濾是必要的。例如我們可以經由某個人電子郵件信箱的使用情形,來了解他對各種電子郵件的偏好。
表一 Spammer常見的把戲
| 欺騙 |
有些電子郵件,會提供讓你選擇是否不想要繼續訂閱(opt-out)的功能,但是絕大部分的opt-out是沒有作用的,甚至不少opt-out
option已被用來確認這個郵件地址還在使用中... |
| F R E E |
在文字之間加入空格、-、=、*、$、!、...等字元,使得關鍵詞比對heuristic
rule甚至是文件分類都可能失效。 |
| Vlagra |
將常見字元用人眼不太分辨的相似字元來替換,例如:
i-> 1->!->l、 o->0、s->5、...等,這也是企圖混淆郵件規則的方法。 |
| 其他 |
運用人類視覺可辨識,但是電腦難以自動辨識的技巧。例如:
利用圖形,文件分類的方法便不適用了。 |
其他方法
除了過濾之外,當然還有各式各樣的方法來解決SPAM的問題。例如:電子郵資(postage)的方法希望經由增加寄件者的成本,來降低SPAM的成長,有寄信須付費(money)及須要耗費計算時間(computation)等做法。
另外,法律途徑可能是最後也是最有效的解決辦法。透過立法使得spamming成為一種犯罪行為,因此得以有效遏止SPAM。但是立法速度緩慢,要如何運用技術來輔助法律的舉證,也是一大重要課題。
因此如何有效整合 heuristic-based 以及 classification-based兩者優點的方法,透過各種現有技術,發展出更有效的電子郵件過濾系統,以進行個人化電子郵件過濾是目前最重要的方向之一。
以下我們提出一個可能的架構 [20],如圖二所示。
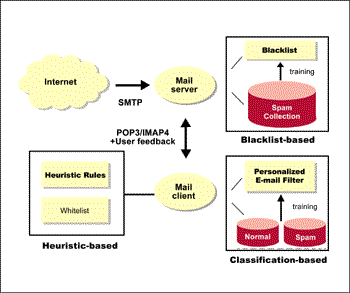
| 《圖二 整合heuristic-based 與classification-based架構圖 》 |
|
雖然本文提到的是 anti-spam e-mail filtering,但是對大多數企業而言,最嚴重的問題卻是機密文件的洩漏。也就是說,企業的郵件過濾只是其中的對外信件(outgoing e-mail)的應用而已。然而我們所提到的e-mail過濾觀念,基本上對於對內(incoming)或對外(outgoing)的信都適用。
未來該何去何從?
由於垃圾郵件不斷的變化,道高一尺,魔高一丈,因此,郵件過濾已成為一場永無止境的戰鬥。例如最近的SPAM郵件主題或內容會加入一些與收件者相關的基本資料 (姓名、日期、時間、...等),這樣一來每個人收到的SPAM就不太一樣,對文件分類的特徵而言增加了一些noise干擾。另外,有一種SPAM內容看起來和你的朋友寫給你的一封簡短的信沒什麼兩樣,只不過它的 link 指向為一個廣告網站,而不是朋友真的想和你分享的資訊。這就語意上來說,很難單憑一封信就判斷出是否為SPAM。
所以,必須根據一個人之前的收發信記錄,以及他所接受與不接受的郵件內容加以訓練,才能自動學習出某個人的喜好,「個人化」會是過濾垃圾郵件的一大課題。目前許多Open Source e-mail filter也正朝向這個方向努力,例如: SpamBayes、SpamAssassin、ifile等Bayesian filter。
另外也由於每封垃圾郵件的主題可能相當分歧(diverse),為了能清楚分辨,應根據比較仔細的分類來判斷是否為SPAM,其準確率必能提高。
最近,IRTF 的ASRG也在討論許多新 protocol 或是 SMTP的修正,例如:Designated Senders Protocol、CRI Framework、SMTP Sender authentication、e-mail path verification等,希望從protocol的根本來解決垃圾郵件嚴重的問題。這些方法不外乎加強寄件者身份的驗證、加重 spammer的成本,使其利潤降低,進而減少spamming。
如前所述,法律途徑可能是比較有效的解決方法,目前各國陸續制定了 anti-spam law [17],將spammer 的行為認定為犯罪,必須處以罰款,如此或許能有效扼止囂張的行為。例如美國在2003年十月與十一月底,分別由參議院與眾議院通過了反垃圾郵件法(CAN-SPAM Act, Controlling the Assault of Non-Solicited Pornography and Marketing Act),日前已經由美國總統簽字同意,成為美國第一個反垃圾郵件的聯邦法。然而在尚未有法可管的台灣,要如何提高技術的進步,以輔助法律上的不足,的確是刻不容緩的事,這有待你我的通力合作。(作者現職於中央研究院資訊科學研究所)
參考資料:
[1] M. Crispin, "Internet Message Access Protocol - Version 4rev1," RFC 2060, IETF, Dec. 1996.
[2] DCC (Distributed Checksum Clearinghouse), http://www.rhyolite.com/anti-spam/dcc/
[3] Joshua Goodman, "Spam Filtering: Text Classification with an Adversary," Invited Talk at Workshop on Operational Text Classification Systems, KDD 2003, Aug. 2003.
[4] Paul Graham, "The Future of Spam Filtering," Seminar by Greater Boston Chapter/ACM, Dec. 12, 2003.
[5] John Graham-Cumming, "Adaptive Filtering: One Year On," Invited Talk at Spam Mini Symposium, USENIX LISA 2003, Oct. 2003.
[6] John Graham-Cumming: The Spammers' Compendium, http://www.jgc.org/tsc/index.htm
[7] Evan Harris, The Next Step in the Spam Control War: Greylisting, http://projects.puremagic.com/greylisting/
[8] ifile, http://www.nongnu.org/ifile/
[9] IRTF ASRG (Anti-Spam Research Group), http://www.irtf.org/asrg/
[10] J. Klensin, Ed., "Simple Mail Transfer Protocol," RFC 2821, IETF, Apr. 2001.
[11] MAPS RBL (Realtime Blackhole List), http://mail-abuse.org/rbl/
[12] J. Myers and M. Rose, "Post Office Protocol - Version 3," RFC 1939, IETF, May 1996.
[13] Proceedings of Spam Conference 2003, available at: http://spamconference.org/proceedings2003.html
[14] Spam Conference 2004, available at: http://spamconference.org/
[15] SpamAssassin, http://spamassassin.org/
[16] SpamBayes, http://spambayes.sourceforge.net/
[17] SpamLaw, http://www.spamlaws.com/
[18] SpamWatch - A peer-to-peer spam filtering system, http://www.cs.berkeley.edu/~zf/spamwatch/
[19] Vipul's Razor, http://razor.sourceforge.net/
[20] Jenq-Haur Wang and Lee-Feng Chien, "Toward Automated E-mail Filtering - An Investigation of Commercial and Academic Approaches," Proceedings of TANET 2003, pp.687-692, Oct. 2003.
|
 |
教您七個妙招
- 遠離垃圾郵件困擾
從郵件伺服器的管理與設定,到選定電子郵件帳號的技巧,作者以其個人的經驗歸納出七個方法來避免垃圾郵件的困擾,依據垃圾郵件的特徵,建立起適用的郵件規則,並採取必要的防範措施。
|
|
打擊Spam總動員
- 談網路行銷與垃圾郵件
Spam原意為豬肉罐頭,現在則是垃圾郵件的代稱,為了反制垃圾郵件的氾濫,許多防止垃圾郵件攻擊的方法及工具應運而生,本文將介紹各種類型的防垃圾郵件軟體,以及學者們對這個“趨勢”所提出的未來解決之道。 |
|
對抗垃圾郵件 還是「法」寶最有用
在對抗垃圾郵件這件事上,軟體商的參與是不可或缺的,然而法律也是很重要的一環,文中舉出了目前使用法律來杜絕垃圾郵件的實例,也提出一套想法
- 以法律來對抗垃圾郵件的可行性。 |
|
善用「郵件規則」
向廣告信說No
這是一篇簡單的教學文章,讓讀者可以親自設定郵件的規則,建立防堵垃圾郵件的第一道關卡。
|
 |
|
|


