強化學習(Reinforcement learning)潛力無窮,能解決許多開發應用上面臨的艱難決策問題,包括產業自動化、自主駕駛、電玩競技遊戲以及機器人等,因此備受矚目。
強化學習是機器學習(Machine learning)的一種,指的是電腦透過與一個動態(dynamic)環境不斷重複地互動,來學習正確地執行一項任務。這種嘗試錯誤(trial-and-error)的學習方法,使電腦在沒有人類干預、沒有被寫入明確的執行任務程式下,就能夠做出一系列的決策。最著名的強化學習案例就是AlphaGo,它是第一支打敗人類圍棋比賽世界冠軍的電腦程式。
強化學習的運作主要是仰賴動態環境中的資料—也就是會隨著外部條件變化而改變的資料,像是天氣或交通流量。強化學習演算法的目標,即是於找出能夠產生最佳結果的策略。強化學習之所以能達成目標,是藉著軟體當中被稱為主體 (agent)的部分在環境中進行探索、互動和學習的方法。
自動駕駛範例
自助停車(self-parking)是自動駕駛功能中極為重要的一環,目標是要讓車輛中的電腦(主體,agent)能準確地尋找位置並將車輛停入正確的停車格。
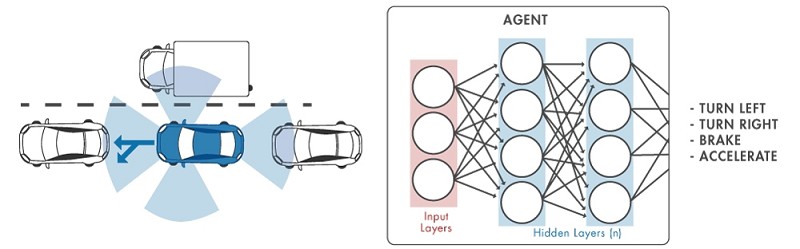
在以下的範例中,「環境」指的是主體之外的所有事物—比如車輛本身的動態、附近的車輛、天候條件等等。訓練過程中,主體使用從各種感測器如攝影機、GPS、光學雷達(LiDAR)以及其他感測器讀取的資料來產生駕駛、煞車與加速指令(動作)。為了學習如何從觀察去產生正確的動作(也就是策略調整,policy tuning),主體會不斷反覆地嘗試錯誤來試著停車,而正確的動作會得到一個獎賞(reward)(強化,reinforced)以數值訊號表示(圖1)。
以此範例來說,訓練是透過一個訓練演算法(training algorithm)來監督。這個訓練演算法(即主體的大腦)負責根據從感測器收集而來的資料、動作、與獎賞來調整主體的策略。經過訓練之後,車輛上的電腦應該只要使用調整過的策略和感測器資料便能進行自主停車。
用於強化學習的演算法
到目前為止,已經有許多強化學習訓練演算法被開發出來,其中某些最熱門的演算法是以深度類神經網路來建構。類神經網路最大的優勢,是可以將複雜的行為編譯為代碼,讓強化學習可以處理許多對傳統演算法來說可能是非常具有挑戰性的任務。
舉例來說,在自動駕駛任務上,類神經網路可以取代駕駛者,透過攝影機的畫面、和光學雷達的量測值等多種感測器的輸入資料進行解讀,並決定如何轉動方向盤(圖2)。
若沒有類神經網路,這種問題會被分解為更細微的部分:首先,一個能分析攝影機輸入資料並找出有用特徵的模組、另一個能過濾光學雷達量測值的模組、可能還需要一個將感測器的輸出資料進行融合、並將車輛周邊環境繪製出來的元件、也就是一個「駕駛」模組等等。
強化學習的工作流程
利用強化學習來訓練一個主體,主要包含五個步驟:
1. 建立環境:定義出一個環境,讓主體可以在裡面進行學習,包含主體與環境之間的介面也須被定義出來。這個環境可以是一個模擬模型,也可能是真實的物理系統。經過模擬的環境通常是作為第一步的較好選擇,因為它較為安全且容許實驗操作。
2. 定義獎賞:具體定義獎賞的訊號,供主體用來衡量其表現(與執行目標相比),以及訊號如何在環境中被計算。獎賞的設計可能會需要經過幾次的疊代才能達到完備。
3. 建立主體:主體由策略和訓練演算法組合而成,所以你會需要:
選擇一個代表策略的方法(比如利用類神經網路或是查找表)。思考一下,你希望如何去建構這些參數和邏輯以成為主體的決策部分。
選擇適當的訓練演算法。現代大部分的強化學習演算法多仰賴類神經網路,因為這是處理大量狀態/動作空間和複雜的問題的好方法。
4. 訓練及驗證主體:你還需要設置訓練的選項(例如停止的標準),並訓練主體來調整策略。驗證經過訓練策略最簡單的方法就是模擬了。
5. 策略的佈署:如何呈現已經被訓練好的策略?舉例來說,可以用C/C++或CUDA程式碼等方式來表示。此時你已經不需要擔心主體和訓練演算法了—因為到此階段,策略已經被轉為一個獨立的決策系統可直接執行。
疊代流程
利用強化學習來訓練主體,所牽涉到嘗試錯誤的次數是相當可觀的,即使已經到較後面的決策與結果階段了,你可能還會需要重新回到較早的學習工作流程步驟中。舉例來說,如果訓練程序沒有在一段合理的時間之內收斂到最佳的決策,你可能會需要在重新訓練主體之前,先去更新下列某些項目:
訓練的設定
學習演算法的配置
策略的表現方式
獎賞訊號的定義
動作與觀察訊號
環境動態
哪些情況適合使用強化學習?
雖然強化學習被視為大幅進化的機器學習,不過它卻不一定是適用於所有情況的最好方法。如果你考慮嘗試使用強化學習,請記住以下三點:
它不具備所謂的樣本效率(sample-efficient)。這指的是,如果要達到可接受的表現,需要有大量的訓練。即使是在相對簡單的應用,可能會花費幾分鐘、幾小時、或甚至是幾天的訓練的時間。AlphaGo就是經過了好幾天沒有間斷、幾百萬次比賽的訓練,等同人類幾千年知識的累積。
問題的正確設定可能很棘手。可能會需要很多的設計決策、相當次數的疊代來達到正確的行為。這些決策包含了選擇合適的類神經網路架構、調整超參數、以及塑造獎賞訊號等。
訓練過的深度神經網路策略是一個「黑盒子」。也就是說,網路內部的結構(通常由幾百萬個參數構成)可能複雜到幾乎難以了解及解釋、以及去評估它所做出的決定,這使得利用類神經網路所建立的策略,很難用正式的性能表現來加以保證它的成效。
如果你所處理的專案攸關時間或安全性至上,你可能可以嘗試其他的替代方案,比如說控制設計,使用傳統的控制方法可能是較好的開始。
實際範例:自學走路的機器人
南加州大學(University of Southern California)Valero Lab的研究人員建造了一個簡單的機械腿,利用以MATLABR編寫的強化學習演算法,幾分鐘之內就讓它自己教導自己學會如何移動(圖3)。

| 圖3 : Valero Lab的新機械肢。圖片提供:USC。 |
|
這個機械肢含有三條腱、兩個關節會自主地進行學習,首先是先建立它的動態屬性模型,接下來則使用強化學習來進行學習。
在物理設計方面,機械腿採用了一個肌腱架構,大致上相當於驅動動物活動的肌肉和肌腱結構。接著研究人員利用強化學習去了解動態行為以達成在跑步機上行走的目標。
強化學習與運動蹣跚
透過運動蹣跚(motor babbling)與強化學習的結合,系統會試圖進行隨機的動作,並透過執行這些動作產生的結果來學習其動態的屬性。以這項研究來說,研究團隊一開始先讓系統進行隨機的運動,或運動蹣跚(motor babble)。只要每一次系統正確地執行了指定任務—在這個範例中,是在跑步機上向前移動,研究人員就會給予系統獎賞。
這個經由學習產生的演算法被稱為G2P(general to particular,從一般到特定的縮寫),它複製了生物神經系統從移動去控制肌腱移動時會遇到的一般問題(圖4)。隨後再強化(給予獎賞)任務的特定行為。在這個範例,任務是要成功地在跑步機上移動。系統透過運動蹣跚建立了自身動態的一般性理解,接著從每一次的經驗或G2P學習,最終開發出達到「特定」任務的行為。
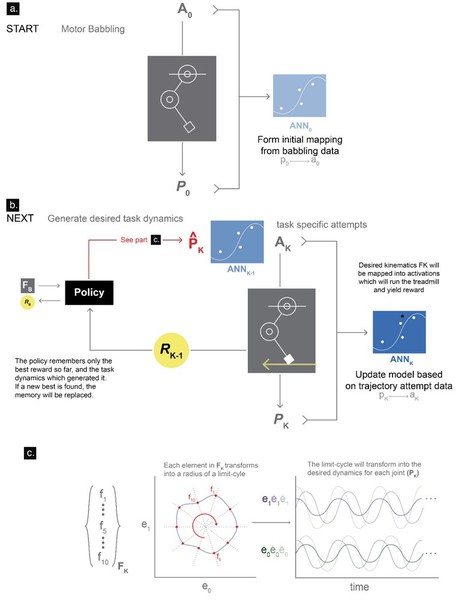
| 圖4 : G2P演算法。(source:Marjaninejad, et al.) |
|
這個類神經網路,是利用MATLAB和深度學習工具箱(Deep Learning Toolbox?)來完成的,它使用了從運動蹣跚得來的結果,建立一個輸入(運動學)和輸出(運動觸發)的反向地圖。該網路會依據強化學習階段所做的每一次嘗試來更新模型,而趨向期望的結果。網路會記住每一次的最佳結果,當新的輸入值創造出更好的結果,網路則會以新的設定來覆蓋原本的模型設定。
G2P演算法在僅僅5分鐘的無特定結構地執行運動蹣跚後,就可以自己學習新的步行任務,然後,它也不需要任何額外的編程,便能夠適應其他任務。
(本文由鈦思科技提供;作者Emmanouil Tzorakoleftherakis任職於MathWorks公司)