何謂開放性的設計資料庫?
一個新世代IC設計資料庫大部分的內容,涉及IC設計中用以完成目的(intent)與履行(implementation)的綜合資料模組。而具備的高效能、物件導向API(Application Programming Interfaces;應用程式介面)等特質的設計資料庫,更可讓應用程式開發人員在無須其內部履行細節的情況下輕鬆使用。
優良的設計資料庫是一複雜、精密,支援EDA應用程式中涵蓋RTL到光罩(mask)廣大範圍資料模組的軟體系統,且非隨著其可用壽命越來越短而老化之過時產品;以Cadence的設計資料庫OpenAccess為例,該資料庫為一重新設計且具備API定義、參照履行(Reference implementation)、實用層級(Utility classes)、翻譯、API使用說明,以及確認套件(Validation Site)等特性的現代化資料庫系統,該資料庫的設計亦符合業界公用標準,希望能藉此達到資源共享的目的。
為共享資源而設計
現今大多數的“開放性”軟體很少由私人專有的軟體捐贈而不收取任何費用,這些“開放性”軟體從未依據各式各樣的社群使用需求而設計,不但在功能上有限制,使用上也常令人充滿了挫折感。以LEF和DEF為例,由於皆依據Cadence專有的標準所開發,而非開放性軟體,因此在軟體的使用上將會是一項挑戰。相對地,設計資料庫軟體若能基於“開放性”而制定、設計,對於資源的共享、內容的擴充以及使用端人員來說,都具有重要的意義。
三個建立於相同平台的資料庫
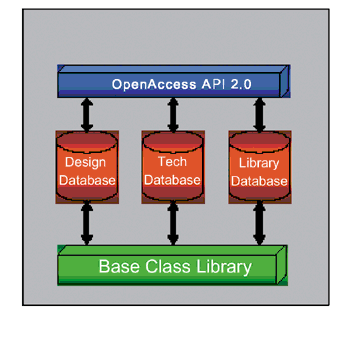
以OpenAccess為例,它實際上是由三個建立於相同平台上的資料庫所組成;如(圖一)所示:一為設計資料庫(Design database),二為技術資料庫(Technology database),而第三則為程式庫資料庫(Library database)。三個子資料庫共通的特色,讓設計資料庫的效能與多功能可維持在一定水準;以下為各子資料庫的內容以及所扮演的角色功能:
設計資料庫(Design database)
設計資料庫提供了設計的資料模型,包括原始外形、實例分層(Instance hierarchy)、邏輯連結、繞線構思(Routing constructs)、空間規劃物件(Floorplanning objects)、寄生 (Parasitics)、元件萃取資料(Cell abstract data)與延伸。此資料庫陳述著一項設計的區塊或模組,而設計資料庫的階層架構允許模組可以參照其他的模組。
技術資料庫(Technology database)
技術資料庫提供了設計技術上壓縮過的資訊,如:光罩階層(Mask layer)、規則、限制,與延伸。此資料庫陳述並管理了由資料庫提供的技術相關資訊;在設計過程中技術資料是為所有的模組所共享。
程式庫資料庫(Library database)
程式庫資料庫則包含了設計與參照程式庫、元件、視野、元件視圖(Cellviews),存取管理與延伸等。此資料庫陳述了一項設計的組織與架構。使用者通常會自行設計設計程式庫(Design library)與參照程式庫(Reference library),典型的參照程式庫中包含了曾為其他模組使用一次(以上)的模組。相較於參照程式庫,設計程式庫中的模組則專用於一特定設計。每一種型態的程式庫通常只因一特定技術而設計;因此,每一個常見的程式庫中只有一個技術資料庫。
基本功用
在EDA資料模組中遍佈了許許多多的基本元件,簡單者如:boxes、 points、pointArrays...等在典型的資料模型中均隨處可見。開放性存取(Open-Access)的好處在於,它所包含的基本功能物件,除了可讓本身的設計資料庫之資料模組使用外,其他的應用程式亦能使用。
開放性資料庫為EDA工具的新核心
一個開放性設計資料庫,不僅是單純提供資料交換的一種格式,而是可將資料由一應用程式搬移到另一應用程式,或是由一製造供應商軟體(Vendor's tool)搬移到另一個,且能達到精確地呈現設計資料與設計目的,並在低度使用記憶體空間的情況下仍能達到高效能目標。低度記憶體使用量與高度效能似乎兩相衝突而無法同時兼顧,但以若能充分使用資料雜湊(Data hashing)與快取(Caching)等複雜的技術,在執行效能衰減極低的前提下,儘可能地壓縮記憶體的使用量,即可大幅度地壓縮在記憶體中的資料,並於資料存取或快取時解壓縮,使資料在讀、寫或修改時能直接使用而不必解壓縮。
開發優質的軟體為必要條件
能將設計資料庫設計成符合EDA標準,是需要在架構設計與程式開發兩方面投注大量心力的,過去的軟體的功能在撰寫完成後雖可正常運作,但其語法通常不夠簡潔、說明文件不夠詳盡而令人難以理解,或需要一大群的程式開發人員來維護;很顯然地,這些缺點是無法由社群(Community)所擁有、維護的資料庫程式碼所接受。為解決這樣的問題,開發團隊必須在“表現特殊的資料庫”與“易於維護與發展的程式碼”兩大議題上進行資料庫的設計;而資料庫內容的簡化,以及資料庫應用程式介面是否方便使用者學習使用等議題,都是必須考量的重點。以下為設計資料庫架構的兩大核心技術(以Open Access為例):
1.物件導向結構與設計
物件導向架構使得資料模組更加易於了解與使用,物件導向的架構除了在“設計(Design)”與“履行(Implementation)”的組織上是一個非常有效的方法外,更使資料模組在運轉(work)與發展(evolve)上更為容易。而在確保可建構出一功能(Function)的同時,亦需兼顧到使用介面的簡潔與效率,經由此介面,設計應用程式可以接觸到預期中的資料模組,而在履行(Implementation)的過程中所做的變更並不會對應用程式碼造成影響。
2.最新的C++ Implementation
開放性資料庫具備了公有(Public)與私有(Private)兩種類別的特質;公有類別僅以一無任何資料使用的介面作為公有應用程式介面,在公有應用程式介面中,其參數是經過驗證且執行緒的安全性是得到保證的;公有的方法所著重的是只需犧牲些微的執行效能便可得到更容易的使用方式。
對於私有類別而言,執行(Implementation)屬於完全隱藏的內部行為。由於沒有參數驗證,使得開發人員必須處理執行緒的同步(Synchronization)。私有類別在使用上需要開發人員所擁有的專業知識,然而這對一般使用者並非一項難題,因為只有開發人員在資料庫上對自身進行存取(Implementation itself)時才需要私有類別。
共同API的主要特色
應用程式介面(Application Programming Interfaces;API)在此被特別強調,原因在於大部分應用程式開發錯誤皆發現於編譯時期。API不使用內嵌方法(In-line method),而相反地改採完整封裝的履行方式(Implementation),使其在變更後無需將應用程式重新編譯。在設計上為了執行緒的安全,API亦提供了內建式名稱映對(Name-mapping)。在類別管理上並不依賴建構子(Constructor)與解構子(Destructor);在虛擬方法(Virtual method)時,並不使用虛擬表格指標(Virtual table pointer),而改為儲存至少4位元組的資料庫物件。
例外(Exception)
例外處理在C語言中並不存在,但它在C++中卻屬於一般的技能。透過典型的資料庫應用程式介面,每一次的資料庫呼叫皆會回傳一狀態值(Status)。應用程式開人員花費過多的時間在先產生呼叫(Calls),在依據回傳的狀態值判斷呼叫的過程是否正常。對於每一個發出的資料庫呼叫,皆必須對其回傳值進行 相同次數的錯誤檢查(Error checking),如此大量的錯誤檢查動作使得該執行哪一段的程式碼變得很難抉擇,也迫使大多數的應用程式開發人員省略了錯誤檢查的步驟,更極有可能因尚未檢測出的錯誤而導致程式碼毀損。
若利用了C++的例外處理機制,資料庫呼叫就不會回傳狀態值;相反地,程式開發人員只寫入程式碼,插入中央例外處理裝置(Exception handler)並省略錯誤檢查的手續。當有錯誤發生時,資料庫會發出一“例外”(Exception)訊號,而此呼叫將不被傳回;而發出的例外訊號將由應用程式的例外處理機制所“捕獲”。集中式錯誤處理能在確保程式碼健全的同時,將履行的困難度降至最低。
復原與重做
將變更復原的能力對於互動式的應用程式而言是很重要的;復原與重做這兩項功能支援所有的應用程式呼叫,應用程式可制定其復原檢查點(Undo checkpoint),而且每一資料庫皆擁有多達128的復原層級(Undo level)。在任一個復原檢查點,應用程式皆可對資料庫發出“復原”的要求;而資料庫中的資料也會依據要求而倒回(Rewound)至上個檢查點。同樣地,應用程式亦可對資料庫發出“重做”(Redo)的要求,則資料庫中該點的資料將被回復至上次使用'復原'指令時的最新狀態。由於執行“復原”需要適當的資源開銷(Overhead),因此該功能的提供與否是可以選擇的,此選項在進行大範圍的修改時是很方便的。
集合(Collections)與游標(Iterators)
“集合”一詞在API中代表著1:N(一對多)關係的意思,如元件視圖(Cell-views)中的實例目錄(Instance list)或網絡中的路徑(Route)。這些集合可能是實際或虛擬的,但它們全都支援方法中的共同集合(Common sets)。API的游標列舉了集合(Collection)中的內容;而集合(Collections)與游標(Iterators)的輕量性(lightweight),更在資料庫內容的取得上提供了最快速的方法。另外,為了使用上的便利性,其履行(Implementation)將以樣版(Template)完成。
擴充性(Extensions)
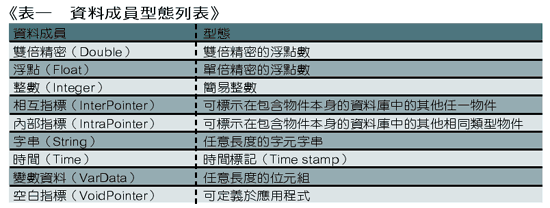
無論多麼完善的資料庫,應用程式仍會依其需求將資料庫加以修改,其根本原因在於單一資料模組是無法滿足每一種應用程式的需求。因此需提供許多機制允許應用程式去擴充資料庫的資料模組,其中一項便是增加應用程式專屬的資料成員(data member);這項機制需適用於資料庫資料模組中的每一個物件,如此應用程式便可依設計需求而增加其資料成員。資料成員的型態可能為(表一)的其中一員。
設計上,應用程式也會產生其專屬的資料庫物件;藉由應用程式專屬的資料庫物件與資料成員的輔助,應用程式的資料模組延伸得以更加複雜。
應用程式專屬的延伸(Extension)與資料庫原本的資料物件、資料成員同樣都具備小而快的特質,這是因為其履行方式與資料庫原本的資料物件及資料成員相同的緣故;過多的一般延伸機制(Common extension mechanisms)所造成的大量負擔,只會使效能低落和增加記憶體的消耗。
名稱映對的重要性
似乎所有的EDA應用程式都各自獨立開發且漸趨成熟,也同時採用各自所宣稱的“合法名稱(legal name)”標記法則,而這些名稱必須遵循一包含向量標記(Vector notation)、保留符號(Reserved symbol)與保留關鍵字(Reserved keywords)之特定語法。由於兩種應用程式所使用的名稱空間可能不同或相互衝突,使其在合作的應用上顯得困難重重,其原因可能在於某一名稱(Name)對於某一應用程式是合法的(Legal),但對於另一者而言卻是不合法的(Illegal)。
一個具備開放與互通性的資料庫,則藉由訂定名稱與名稱空間的標示法則來解決此問題;名稱(Name)是一個類似字串(String)的物件,且在它被詳細規定的名稱空間中是唯一的;相反地,名稱(Name)無法直接被應用程式讀取,應用程式必須先定義一專司“觀看(View)”名稱的名稱空間,並由此名稱空間將其轉換成一字串後方可讀取。
名稱之直譯與轉譯
開放性資料庫的一項特色是具備直譯(Interpret)與轉譯(Translate)定義在不同名稱空間之名稱的複雜能力;能達成此目的之最主要關鍵,是將產生正確名稱的職責由“流程配給(Flow issue)”轉為“應用程式配給(Application issue)”。不論是何種類型的名稱空間(Name space)其名稱皆可以“識別碼(Identifier)”代表,其轉換方式可為“語義上一對一轉換(Semantically one-to-one)”、“演算法轉換(Algorithmic)”、以及“可逆式轉換(Reversible)”。
區域查詢(Region Querying)
@內文此特色使應用程式能夠有效地搜尋資料庫中某特定區域的資料內容,同時這也是資料庫對成果交付(Rendering)、互動選取(Interactive selection),與重疊測試(Overlap testing)等動作展現更加執行效能的另一方法,因為上述的動作並不需要資料庫履行(Database implemen-tation)。此項查詢功能是以階級的方式運作,而運作的內容則是由應用程式決定。以OpenAccess為例,該資料庫的區域查詢功能是利用動態二進制樹狀圖實作的;在設計上,此搜尋動作是可於任何時刻終止的,這對於和成果交付(Rendering)一樣需要“可中斷(Interruptible)”特性的應用程式是非常重要的。
召回(Callback)
這項機制允許多個應用程式在相同計劃運行,而僅需保持與資料庫和其他應用程式間的同步(Synchronization)。實際上,“召回”可被設定為用來告知應用程式資料庫的狀態已改變,這項功能對於彼此間獨立運作的應用程式而言是很重要的;對成批應用程式(Batch application)來說,應用程式間的自主性(Independence)似乎不存在,但對互動式應用程式而言,卻會造成複雜的問題。
舉例來說,某一應用程式在運作時也許必須精確地掌握資料庫的所有資訊,而其他應用程式對資料庫所做的變更,便會對前者產生了問題。基本來說,“召回”是一個透過虛擬呼叫,以告知應用程式資料庫的狀態已變更的單純物件,應用程式會建構自己專屬的“召回物件(Callback object)”,並提供其物件被呼叫時的相對應方法。
當召回物件產生、銷毀、或變更時,皆會“呼叫”(Invoke)其唯一的方法與之對應;其次,所傳回的資訊便會送至召回的擁有者(Callback owner;通常為應用程式)以作為檢測資料庫物件的參考。由於每當資料庫發生變更時就會呼叫一次“召回”,因此開發人員必須確認再處理“召回”的過程不會耗費過多的時間。
結語
建構具備開放與互通性設計資料庫的目的,是創造出一個所有EDA社群皆可共享的資料庫,它並不會為了符合某單一應用程式或公司的需求予以修改,並依循嚴謹的標準,為達到簡潔的程式碼、易於了解與維護的目的而撰寫。而目前針對資料庫開放的議題,部分EDA業者亦已組成了相關聯盟與社群,以針對開放性資料庫的功能持續進行改進,讓資料庫的發展能更加完備並符合往後新的需求。
(作者任職於Santos, Cadence Design Systems;編譯:Cadence Taiwan)
<參考文獻:
[1] http://www.si2.org/OpenAccess/faq.htm>