NOR與NAND快閃記憶體從於1986年問世至今,20年間已延展9個世代。記憶體種類和MLC技術的延展帶給手機與數位相機市場高密度的程式碼與可移除資料儲存媒體。本文將討論快閃記憶體延展將如何繼續催生新解決方案,包括行動通訊與個人電腦運算平台。新 DDR NOR快閃記憶體介面將使行動應用(如3G/UMTS手機)以更高效能(133MHz與更高)執行程式碼。非揮發性記憶體 (NVM) 磁碟快取記憶體正開始成為個人電腦運算與其他應用重要與可行的子系統。將NAND Flash 加入個人電腦記憶體階層可提生效能、減少耗電、並提供更豐富的使用經驗。雖然記憶體技術延展仍存在挑戰,快閃記憶體解決方案將持續進化,以更低耗電,以及更多元和高效率的解決方案,滿足種類不斷變化的應用需求。
簡介
對系統平台設計師而言,快閃記憶體延展的優點包括密度更高、效能提升、與耗電減少。但對快閃記憶體晶片設計師而言,延展不僅帶來製程與原件層面的優點,也帶來新設計挑戰。技術核心電壓 (VCC)、輸入/輸出 (VCCQ)電壓、與外部programming電壓 (VPP) 也隨之延展。
為了維持和提升讀寫效能水平,並盡量將讀寫快閃記憶體單元所需的電力維持不變,這些延展因素帶來設計挑戰。
技術延展對NOR和NAND快閃記憶體的影響
在帶動技術延展的因素,以及使用者平台需求方面存在著微妙的平衡,NOR的需求如手機和內嵌式應用,NAND快閃記憶體的需求如記憶卡。NOR和NAND有各自的設計延展挑戰。對NOR而言,挑戰在於更快的讀取和 programming 並減少耗電,NAND的挑戰為更高的密度與更快的programming
電壓延展
在很多狀況下,NOR 的應用或通訊處理器邏輯電壓與 NAND 的記憶體控制器電壓會影響或主宰供應電壓roadmap。不論是減少耗電,還是搭配平台的電源供應,供應電壓 (VCC) 的改變都代表對內部快閃記憶體 voltage pump 架構和線路設計的挑戰,因為它們要維持輸出電流,也要保持參考與讀取偏壓,以感測與修改記憶陣列資料。
降低電壓時,維持NOR voltage pumps Iout的CHE programming特別重要。要維持pump負載線的fCstage/n或1/Rtheory,「n」代表pump階數,「C」代表pump電容,必須隨任何恆定的pump時脈「f」增加。
Voltage pump面積隨著階數「n」的平方增加。為了減少voltage pump對晶粒大小的影響,曾使用更高容量的pump電容。為了緩和電壓延展的挑戰,pump架構曾從2相時脈pump改為4相時脈pump。
對 NAND 而言,因為單元 FN programming機制的不同,programming電流需求要小的多,但從較低起點(如1.8伏)產生programming和刪除電壓需要的階數是另一種挑戰。從較高的電壓起點(如3伏)改成較低電壓起點會大幅影響pump大小。
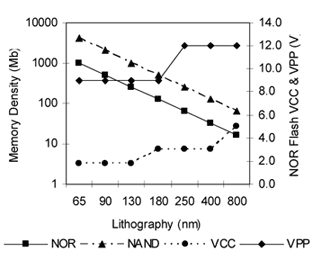
VPP programming電壓延展也更為困難。快閃記憶體陣列電晶體programming的時候,不論是從多工的內部pumped高電壓路徑還是外部的高電壓路徑,VPP電壓延展都要符合可靠度要求,即使電晶體閘級氧化層上一直有恆定的高電壓壓力。從下面的(圖二)可以清楚看出,從初始的12 V產品到現在的9 V應用,要維持相同的可靠度標準,VPP電壓延展會隨HVT閘級氧化層的厚度而增加。.
採用更薄的閘級氧化層可改善轉導 (transconductance),但必須與閘級氧化層漏電取得平衡。為了達到更高的效能,可運用管理功率和閘級漏電設計的方式,進一步減少HPT閘級氧化層厚度。雖然HPT漏電的情形較為嚴重,卻能催生更高效能的架構,例如NOR Flash採用Mobile DRAM DDR介面,本文稍後會加以討論。
Periphery transistor延展
電壓也隨著技術延展。這樣的延展對快閃記憶體使用的periphery transistor有正反雙面的影響。(圖二)高效能電晶體(HPTs)與高電壓電晶體(HVTs)的電晶體閘級氧化層厚度演進趨勢和VCC與外部電壓VPP的關係。Periphery transistor的閘級氧化層厚度延展需巧妙平衡裝置轉導 (gm)與閘級漏電,以維持快閃記憶體一貫的低耗電。
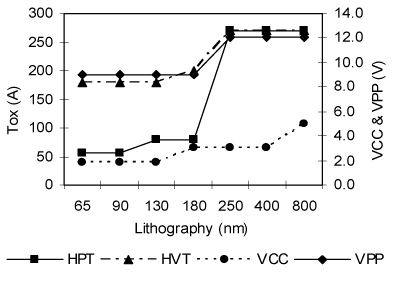
| 《圖二 NOR Periphery Transistor與供應電壓延展》 |
|
部分先導產品將180奈米(nm)技術節點的供應電壓從3.0伏降低到1.8伏,HPT閘級氧化層厚度也隨之減少,補償降低供應電壓導致的gm下降。(表一)相同電晶體尺寸的計算值,減少閘級氧化層厚度可補償轉導值。
(表一) Periphery Transistor轉導vs.Tox
VCC (伏) |
Tox (安培) |
W/L |
Gm |
3.0 |
280 |
10 |
6.6 |
1.8 |
80 |
10 |
9.3 |
NOR與NAND快閃記憶體未來演進與應用
快閃記憶體延展的確為手持式、內嵌式、和可移除資料儲存卡市場帶來很多好處。本節討論為何快閃記憶體延展的部分層面正創造新演進機會,並分別催生新 NOR 與 NAND 快閃記憶體應用。
Mobile DDR介面的NOR快閃記憶體
手機消費者希望利用3G/UMTS與HSDPA等更快速的數據傳輸標準,享受音樂和視訊多媒體內容,因此手機業者需要能更快上市、成本效益更高、效能更強的記憶體解決方案。除非手機記憶體介面能有效支援必要的速度,否則努力也是枉然。.
為了滿足這些平台目標,最佳解決方案就是根據標準非揮發性記憶體介面設計,提供高效能、管線式、同步存取,以及與DRAM相容的記憶體介面。這種策略使用並針對通用記憶體介面和執行匯流排設計 (例Mobile DDR ),將可簡化手機原始設備製造商(OEM)的記憶子系統,包括揮發性和非揮發性記憶體。Mobile DDR Flash/DRAM通訊協定與標準將提供差動時脈、各位元組巷道(byte lane)與來源同步的資料選通脈衝(data strobe)、與可設定組態的輸出驅動強度,以匹配組抗,將有利於所有可使用這些系統特性的記憶裝置。
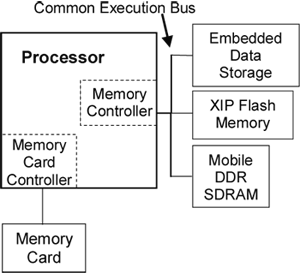
因為通用記憶執行匯流排的緣故,晶片設計可以簡化成單一記憶體控制器(圖三),並減少接腳數,並讓DRAM與快閃記憶體以同樣的最佳頻率運作。這能改善應用回應時間。通用雙倍資料傳輸速率(DDR)介面可在不同記憶體類型(NOR、NAND、DRAM)間建立管線,將記憶體匯流排使用率提升到最大,也就是改善匯流排效能。
技術延展的優點包括支援採Mobile DDR介面的快閃記憶體。業界曾提出多種採類似 DRAM介面的快閃記憶體,內部架構為NOR或NAND陣列,例如三星於1997年以及美光 (Micron)於2000年10月左右提出的「SynchFlash」。目前的65nm技術節點可提供多種技術優點,催生這種Flash產品。較小的快閃記憶體單元和銅互連技術可用來生產512 Mbit或1 Gbit的晶粒大小。改良過的HPT可提供高速解碼、列/行選擇、與感測所需的周邊速度效能。高速DDR管線架構也是催生因素之一。
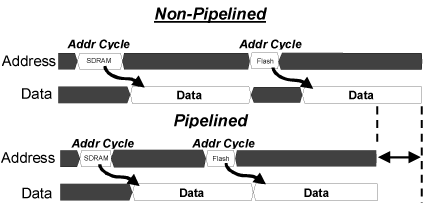
快閃記憶體的讀取頻寬不及一般DDR DRAM。但創意架構運用高速定址、解碼、和感測技術,因此可設計出高效能Mobile DDR Flash記憶體。管線式相較於非管線式匯流排協定 (圖四) 是催生這種零件的關鍵。這種架構和現在的同步叢發 (burst) 模式零件不同。管線可完全利用所有記憶元件間的匯流排,讓所有其他驅動資料匯流排的記憶元件都感測到初始資料。一旦偵測和鎖定 (latch) 初始資料,接下來雙倍資料傳輸速率就足以滿足記憶子系統的需求。
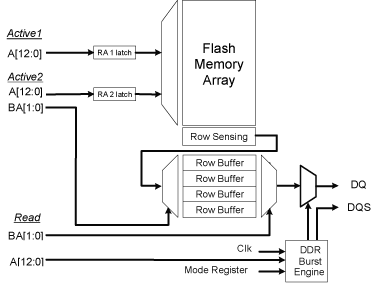
這種設計如果採用NOR Flash,就可以讓晶片架構與設計師完全利用NOR的短行 (short row) 陣列架構,有利於高速選擇列和感測低耗電。「圖五」描述採短行與SRDAM式定址介面的NOR快閃記憶體陣列如何定址和選擇。
記憶體控制器以三相提供陣列位址給記憶體 (圖五)。在執行ACTIVE1指令時,列位址的一部份(透過位址接腳傳送)被儲存在列位址暫存器(register) latches內(RA1)。在執行 ACTIVE2指令時,剩下的列位址也透過位址接腳傳送。這兩部分加起來可選擇記憶體陣列中的某一列。ACTIVE2也導致內部儲存線路將該記憶內容傳送到4個緩衝暫存器(buffer)之1,後者由BA1與BA0選擇。在執行READ與WRITE指令時,BA1和BA0會選擇4個列緩衝暫存器之中的1個,行位址則透過位址接腳傳送,選擇叢發讀取或叢發寫入的起始字組。如果想要的列緩衝暫存器已經有想要的記憶內容,就不一定要ACTIVE2指令。.
Bank Address接腳(BA1與BA0)控制多工器,選擇記憶體4個列緩衝暫存器中的1個。但陣列解碼器不會使用BA,後者並不選擇陣列的一部份。任何邏輯位址可能傳送任何一種BA值。
非揮發性記憶體磁碟快取記憶體
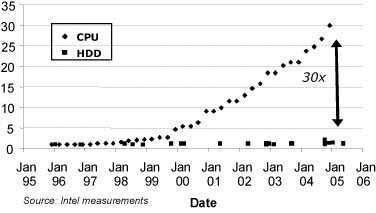
微影技術的改良和線路的進步使CPU的效能在過去10年間提升30倍,然而硬碟機件的讀寫延遲進步幅度並沒有這麼大。資料頻寬的差異限制了傳送給CPU運算或處理的資料流量 (圖六)。
增加系統DRAM的代價包括增加平台成本與耗電,對實際平台功能與使用者經驗並沒有什麼幫助。在硬碟與CPU間新加入一層非揮發性記憶體/儲存階層可回應硬碟讀寫延遲問題。
這種新記憶體層由最佳密度的NAND快閃記憶體組成。由於NAND記憶層讀寫速度快,可將磁碟讀與寫快取記憶體兩者合而為一。NVM 快取記憶體單元提供資料給CPU的速度快的多,而且在讀寫時可大幅延長磁碟機待機時間。此外,因為開機檔案與資料存在NAND快閃快取記憶體內,而非磁碟上,可顯著改善開機流程和速度。讀寫快取記憶體和集中寫入硬碟可顯著節約電池用電 (表二)。
(表二) 比較以NAND快閃記憶體作為快取的磁碟
功能 |
一般硬碟* |
以 NAND 快閃記憶體作為快取的磁碟 |
存取延遲 (毫秒) |
~ 7.5 |
~ 0.06 |
開機時間 (秒) |
- - |
~ 30 秒(減少) |
節約電力 (分鐘) |
- - |
~ 20 分鐘(延長) |
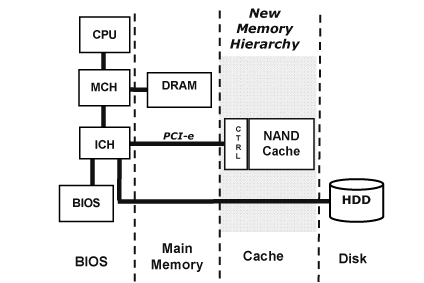
這種新非揮發性記憶體層需要英特爾設計的ASIC控制器,後者針對英特爾NAND快取記憶體最佳化與認證(圖八) 。
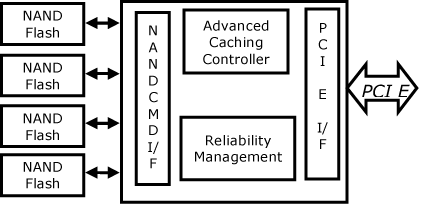
| 《圖八 NVM磁碟快取ASIC與NAND快閃記憶體模組》 |
|
業界以NAND快閃記憶體ASIC控制器配合大量的個人電腦平台使用模式研究,已開發出作業系統 (OS)內建驅動軟體,達成全方位、先進、與可靠的磁碟快取能力。本解決方案的架構非常類似在高效能PCI-E匯流排上運作的CPU處理器,可提供最高的硬碟讀寫快取能力。
結論
快閃記憶體晶片與架構設計師將與製程元件物理學家合作,利用新製程能力來提供新功能與應用,並透過創新晶片架構與線路技術,解決技術延展問題。
手機不斷演進,滿足3G/UMTS與HSDPA通訊協定對應用速度與讀寫資料回應時間的要求。很明顯地,高效能通用記憶介面可以派上用場;Mobile-DDR 匯流排介面是支援管線的業界標準。如果以包括最佳化NAND快閃記憶體密度的新非揮發性記憶層作為個人電腦主機板平台上的 NVM磁碟快取記憶體,可改善硬碟與CPU間的資料頻寬差異。新的記憶層也將減少耗電、縮短開機時間、執行使用者應用軟體的速度更快,進而提供更佳的整體個人電腦使用經驗。.
參考資料
[1] T-S. Jung, ISCC Digest, p.398 (1997).