從1990年代開始半導體產業的快速進步使設計師能夠用功能強大的DSP和微處理器晶片來解決非常複雜即時的軟體應用。電信產業便是由這些發展成果大幅得到好處的重要領域之一。有許多標準化團體和特殊利益論壇主動形成並發展新的應用方案所需的專門知識。
本文提供讀者對於典型以軟體為主的產品,如行動電話的語音編解碼器,其發展方法的實務概論。特別對GSM行動電話應用的適應性多重速率(Adaptive Multirate;AMR)編解碼器軟體發展作簡介,包括發展經過、硬體使用,以及使用標準化團體所開發的參考程式碼。雖然討論的部份只針對此演算法和架構,移植和測試程式碼的基本步驟其實可應用到所有的嵌入式演算法和硬體平台。參考資料[1]是實用的概論。如果想要了解DSP處理器架構概念,可以參閱參考資料[2]。
AMR語音編解碼器與GSM環境
在新的千禧年開始之初,超過六億的GSM用戶以使用語音為主要服務項目。電信業者的挑戰在增進通話品質的同時還要將頻譜效率最佳化,在用戶密集的市區尤其如此。1990年代後期GSM業者和開發人員建立了一套語音處理標準,用以處理非最佳分割的來源和頻道編碼速率。在固定頻道編碼速率下,想要最佳使用錯誤校正(Error Correction)是不可能的。當頻道狀況差時,頻道加密器所加入的多餘位元可能不足以改正傳輸錯誤。同樣地,當頻道狀況好時,在來源編碼多加入一些位元能夠改善語音品質。AMR標準採用一種智慧的結合方法解決此問題。
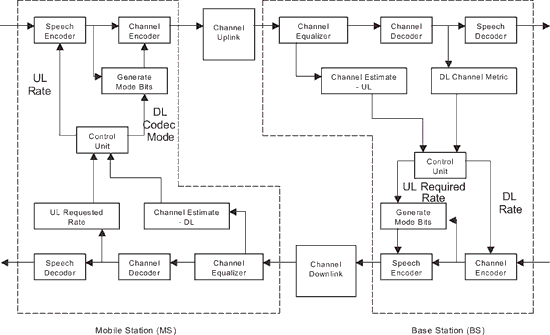
(圖一)描述AMR語音傳輸系統的基本概念。基地台(Base Station;BS)和行動台(Mobile Station;MS)都是由下列主體所組成:
- ●可變位元速率的語音編解碼器(語音編碼器SP-Enc和語音解碼器SP-Dec);
- ●可變錯誤保護率的頻道編解碼器,配合語音編解碼器的位元率[頻道編碼器(CH-Enc)和頻道解碼器(CH-Dec)];
- ●頻道估計主體(CH-Est);
- ●速率適應控制單元。
基地台是系統中的主宰,決定了上傳(UL)和下載(DL)的速率。有一個用來控制編解碼器速率的頻道品質參數是來自於行動台上的等化器(Equalizer)所產生的軟式輸出(Soft Output)。行動台在上傳方向的訊務頻道(TCH)傳送模式位元(Mode bits;頻道速率資訊),而DL頻道量度(DL Channel Metric;下載頻道品質資訊)則使用控制頻道(SACCH)傳送到CH-Dec。在接收方首先作頻道解碼,接著是語音解碼。在同時BS頻道量測器會對UL頻道作出測量。量到的UL頻道品質和DL頻道量度(從MS接收)送到BS控制單元,在那裡會決定現行的DL速率和所需要的UL速率。
在DL方向中,現行DL模式和所需要的UL速率會在下載方向的TCH頻道裡一起傳送到MS。與上傳相似的是,MS的頻道量測器對DL頻道品質作出測量,而所需要的UL速率會從接收到的位元串流(Bitstream)中解碼得出。MS控制單元由測量到的DL頻道品質計算出DL頻道量度,再經由SACCH傳送到BS。此時語音編碼器是以新獲得的UL速率在運作。AMR的概念允許在頻道狀況差的時候能有接近固網的通話品質,而當狀況好的時候品質會更好。如果想知道更多關於AMR和可變速率編解碼器的細節,可以參閱參考資料[3]和[4]。
數位訊號處理器架構概論
微處理器和微控制器通常用於需要處理有共同順序活動的應用程式,而有時候要能將不論頻繁與否的通話分離成不儘相同的順序。舉例來說,在一具行動電話上輸入一組號碼,則微處理器子系統內部的號碼處理演算法會負責此行為並掌控整個過程。當接到一通來電時,手機的微處理器與基地台之間會啟動多項程序,然後開始語音交談。在這個例子裡,處理器子系統等待與按鍵活動相關的打斷動作,或是射頻(RF)系統偵測到來電。
DSP是一種特別的微處理器,其架構特地針對嵌入式系統內的即時信號處理演算和應用程式所調整。這跟「通用型」微處理器的架構有所不同,微處理器通常是設計來處理很多不同種類的應用程式,且其系統通常能夠容許較大程度的總執行時間不確定性。例如說,在微處理器上花上19.9ms跟20.1ms的時間來執行一個與使用者介面有關工作的差異性很小,而且一般來說不太重要。然而這種因為計算上的延遲對DSP來說可能就代表著訊框中的資料順利進行處理或緩衝器溢出的差異。後者將導致輸出資料損壞或是通訊頻道中斷。
由於DSP被設計為一定要能以快速和有彈性的方式處理許多不同種類的數學運算,DSP的運算是採用同步雙資料存取的乘法累加(Multiply/Accumulate;MAC)的方式。除此之外,這種指令多半涵蓋在迴路(Loop)以內。所以DSP也包括對零負擔(Zero-overhead)迴路的準備(迴路計數器是由硬體而非軟體處理)。
MAC指令為諸如自動校正、有限脈衝響應(Finite Impulse Response;FIR)濾波,和迴旋(convolution)等演算法的系統核心,這些對於信號調變與分析都是非常重要的。一個簡單的迴路內含MAC指令範例(以C語言寫成)如下所示:
long correlate(short *input, short *coeff, int corrlen) {
long result = 0;
int i;
for (i=0; i<corrlen; i++) {
result=result+(((*input)++)*((*coeff)++));}
return result;}
此功能相乘input和coeff陣列並將累計總和當成變數result的值。在DSP上可以在一個循環之內執行MAC指令再加上維護迴路計數器的程式碼(忽略其他或許需要用來啟動硬體迴路計數器的週期)。DSP的累加器通常都會比乘積結果要大得多,這樣才能在一個迴路中執行多個MAC指令而不會使輸出暫存器發生溢流(Overflow)的現象。
通用型微處理器當然也可以計算上述的功能。但是微處理器原本並不是設計來運算信號處理密集的應用程式。較早期的微處理器在信號處理的演算效能極差。最近的主流桌上型處理器在DSP處理能力上已經有所改進,如Pentium產品加入的SIMD(Single Instruction Multiple Data;單一指令多重資料)和SSE(Streaming SIMD Extensions,串流SIMD延伸)以及PowerPC架構的AltiVec。實際上在從64位元的超純量(Superscalar)架構一直到最基本的8位元大眾化微控制器等許多微處理器的產品線中,均可看到以信號處理為中心的改善。然而即便如此,DSP在執行信號處理演算時經常還是比微處理器要有效率的多,在低電力的應用方案尤其明顯。
AMR語音編解碼器概論
適應性多重速率(AMR)語音編解碼器在1998年底推出時被視為是GSM無線網路的新型編解碼器和第三代WCDMA(Wideband Code Division Multiple Access;寬頻分碼多工存取)系統的內建語音編解碼器。到了2003年初時,AMR已經廣泛應用在現有的GSM系統中。這種語音編解碼器的一些特色包括:
- ●根據頻道特性和系統負載情形的不同,有8種介於4.75 kbps和12.2kbps之間的適應性資料速率可以選擇[5]。
- ●聲音訊息偵測(Voice Activity Detection;VAD)、?音描述(Silence Description;SID)、雜訊降低(Comfort Noise Generation;CNG),與在交談靜默時降低資料速率的不連續傳輸(Discontinuous Transmission;DTX)功能。
- ●因訊務頻道的誤差而產生訊框遺漏時替代或消音功能。
- ●定點DSP架構的有效實行方式。
AMR語音編解碼器的規格是由特別行動通訊團體(Special Mobile Group),一個歐洲電信標準組織(European telecommunications Standards Institute;ETSI)的次級團體所制定,ETSI為一個非營利組織,負責制定和維持歐洲專用的電信標準,而這些標準也有可能用於全世界。AMR語音編解碼器的全部技術規格都可以在ETSI的網站上找到[6]。
AMR語音編碼器技術
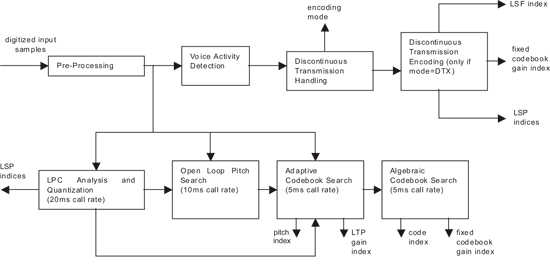
AMR語音編碼器被設計為將160組16位元的字元輸入編譯成95到244位元之間的編碼參數輸出,輸出的長度視編碼器的運算模式而定。以AMR為基礎的應用程式所要求的ADC/DAC取樣率是8KHz。因此AMR語音編碼器持續地以20ms(160 x 125μs)的速率處理資料訊框。處理路徑可以大致區分成下列的功能方塊:前置處理(Pre-processing)、線性預測分析和量化(Linear predictive analysis and quantization)、開放迴圈音調與增益分析(Open loop pitch and gain analysis)也就是適應型代碼簿搜尋(Adaptive codebook search)、以及代數型代碼簿搜尋。部份功能方塊是以20ms的資料訊框來計算,其他的演算則以5ms或10ms的取樣資料子訊框(Subframe)為基準(通常稱為子訊框迴圈;Subframe Loop)。
AMR語音編碼器也可以執行VAD計算以判斷現有的訊框是否含有語音和背景雜訊,以及在解碼時的DTX模式以降低當編碼器中沒有語音時的集結傳輸需求。AMR語音編碼器的資料流程方塊如(圖二)所示。
這裡有一段對於AMR編碼所需要的演算法和計算形式的摘要,並未對演算法作最詳盡的解釋。為了簡單起見,以下僅對4.75kbps的編碼模式作說明。八種運算模式的計算大多類似,而在某些模式中會增減部份的步驟。請參考以下的規格以獲得完整的AMR語音編碼器技術資訊(可以在ETSI的網站下載):
前置處理(Pre-processing)
一旦裝滿輸入緩衝器的160個樣本,AMR語音編解碼器就對資料進行前置處理。首先是去掉輸入樣本的最小三位有效位元(Least Significant Bit;LSB),使得一組16位元的輸入信號只剩下13位元的資料。在多數的情形下因為電信ADC的低SNR和壓縮方法原本具有的失真,這些資料損失是聽不見的。處理過的輸入資料接著以80Hz的截止頻率,經過一組二階無限脈衝響應(Infinite Impulse Response;IIR)高通濾波器(Highpass Filter;HPF)。此濾波過程是可接受的,因為在電信系統中的基頻為300~3400Hz。此外輸入信號會下降兩級,減少因進行16位元定點計算產生的飽和或溢流所引發的誤差或失真的機會。
聲音訊息偵測(VAD)
在語音編碼器產出參數之前,輸入語音先要進行VAD演算來判斷取樣緩衝器內是否為有效的語音或者只是背景雜訊。假使輸入資料判定為語音,則進行編碼步驟。不然則進行DTX演算來決定緩衝器是否仍當成是語音來完全編碼,或是傳輸一個簡化的資料訊框(稱為靜音描述符號;Silence Descriptor,或是SID訊框)。
AMR語音編解碼器包括兩種不同的VAD演算法,VAD1和VAD2。只有一種VAD演算法會被編譯進入完整的AMR語音編解碼器。兩種VAD演算法的輸出信號都是一樣的;會有一個旗標(Flag)表示現在的輸入信號是否含有語音。系統設計師決定那一種演算法較適合其應用方案。因為在GSM無線通訊中VAD1比較常用,在以下僅對此演算法作說明。
VAD1演算法對輸入信號進行跨九個頻帶的功率分析。除此之外,VAD1使用音調延遲(Pitch Delay,從開放與封閉迴路音調分析收集得來)對之前的編碼器計算結果偵測額外的週期信號,以及音色偵測(Tone Dectection)來判斷之前的編碼器計算結果中是否有帶有訊息的音調,如DTMF。也會執行複雜信號偵測以尋找開放迴路音調分析結果中的複雜關連信號,如音樂。VAD1演算法使用這些資料與背景雜訊的估計值得到背景雜訊功率與信號功率在9個頻帶中的比值。這個比值會與一個適應性界限作比較,如果超過界限則判定輸入信號為雜訊。最終的VAD結果會視雜訊信號的複雜度分析(信號可以經由CNG適當處理),與是否應該有「移換手(Hangover)」而定,有 「移換手」時語音編碼器會在語音突波(burst)結束時繼續把信號當成語音作解析。
不連續傳輸(DTX)
DTX功能方塊決定現有的訊框是否要處理,不論是語音或雜訊。注意這和VAD有所不同,VAD決定現有的訊框是否要當成語音或是雜訊。在AMR語音編碼器由處理語音資料切換到處理雜訊之前一定要有一長串連續的雜訊訊框。這麼做的用意是避免編碼器快速切換不同模式而產生惱人的噪音。一旦有足夠的訊框被辨識為雜訊,語音編碼器會進入較少參數的簡單模式。編碼器會嘗試將抽樣雜訊的頻譜品質作比對,並將此訊框設為SID_FIRST_FRAME。如果信號繼續是雜訊,則開始從SID_FIRST_FRAME之後的第三個訊框開始每隔8個訊框傳送一個SID_UPDATE訊框以提供雜訊的最新情況。
DTX處理基本上是一種狀態機制,控制是否計算全部編碼參數(語音),計算一部份的參數(SID_FIRST或SID_UPDATE),或是否不需要計算(NO_DATA)。DTX處理要在想要較低的頻?需求和可理解的語音中取得平衡,特別是在開始點時(一個新的語音突波開始時)。DTX處理在無線應用方案中特別有意義,因其非常希望避免連續傳送信號。傳送較少的信號不但可降低在空氣介質中的整體干擾,同時可節省無線通訊裝置的電力。
線性預測分析和量化
線性預測編碼(Linear Predictive Coding;LPC)是一種表示和壓縮語音成為一組參數的常用方法。簡單地說,LPC演算法將聲音束的行為當作是一連串的共鳴管和氣流經過聲帶的模型,產生準週期衝擊(Quasi-periodic Impulses;發聲信號)或是白色噪音(White Noise;不出聲的信號)。LPC模型以全極濾波器(共振峰濾波器)的濾波係數計算出聲音束的共振頻率。AMR使用一組10階的全極濾波器來表示和估計聲音束的共振頻率。濾波器係數可以用不同的方法計算出來。AMR語音編碼採用自我相關(Autocorrelation)法與Levinson-Durbin遞迴來計算線性預測(LP)係數[7,8,9,10,11]。
一旦係數計算出來後會轉換成線頻譜對(Line Spectral Pairs;LSPs)。作這個轉換有三個理由:第一,LSP易於用來評量該LP濾波器是否有任何共振。其次,量化LSP所產生的誤差要比量化LP係數來得小,因為對頻譜的敏感度較低。此外,因為LSP與共振峰濾波器的共振頻率有直接關係,LSP極適合作為訊框到訊框之間的插入(Interpolating)係數。對LSP作一階移動平均預測值(Moving Average Predictor),再用分割矩陣量化法量化殘餘向量[12]。量化指數將被當作編碼參數的一部份來傳輸。
開放與封閉迴路的Pitch分析
開放迴路pitch分析是用來找出輸入向量pitch的估計值。這個估計是用來封閉迴路pitch分析,是用來找出少數的pitch延遲。封閉迴路的pitch分析計算整數和小數的延遲。這個延遲是透過對特定範圍當中的所有延遲的處理,然後找出原始和合成語音間最小的平均平方誤差(mean squared error)的pitch延遲。在此,一個pitch增益(gain)是透過計算已篩選過的適應性代碼簿的取得和比例,及其和已篩選的適應性代碼簿與目標信號間相關程度的比例。這樣的延遲和pitch都會被編碼且成為被傳輸參數的一部分。
幾何代碼簿查詢
幾何代碼簿的查詢,是將已加權的輸入信號與已加權的合成語音信號之間的平均平方誤差的最小化來進行。目標信號是在計算所需的幾何程式碼前,與來自適應性程式碼的貢獻一起更新的。代碼簿的基本想法是找出一系列的脈衝,在通過合成篩選裝置時加入先前的語音信號估計值,這麼一來將減少這個新的信號和目標輸入信號間的誤差。在AMR的4.75kbps模式當中,每次訊框的兩個脈衝是用來勵磁(excitation)之用。在次訊框中脈衝的位置和信號會被編碼,這麼一來,需要36個位元來代表所有四個次訊框當中脈衝的位置與信號 。
不同子訊框之間的資料處理有一些微小但明顯的差異。其中之一是部份參數是以之前的數值差異作編碼而非絕對值。這樣可以減少傳輸所需的總位元數而不致?牲語音品質。在處理語音訊框結束時,AMR語音編碼器亦會更新狀態(靜態)變數。
語音解碼器技術概論
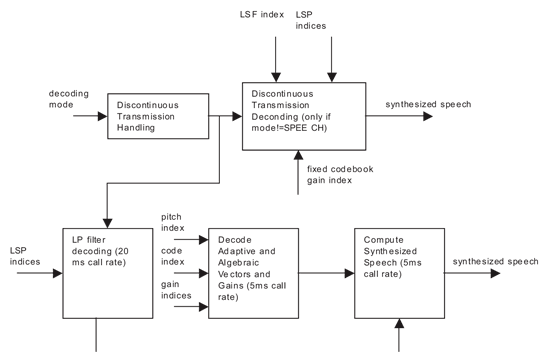
AMR語音解碼器與編碼器的技術架構類似,只是需要計算的部份較少。主要原因是語音解碼器著重於由已計算出的參數合成信號,而不必分析輸入信號及判斷參數是否能充分描述信號。AMR解碼器的基本處理方塊為LP濾波器解碼、解譯適應性與代數密碼簿向量和增益,以及計算合成的語音,如(圖三)所示。AMR語音解碼器也包括DTX處理演算。
DTX處理
從AMR編碼器對已接收的參數進行解碼的第一步驟,是決定所接收的框架是否包含語音或是一個DTX框架一部分。此一步驟是隨著分析以往框架類型所產生的參數,分析現有框架類型所達成。如果輸入向量確定不是語音的話,該參數會通過一個DTX解碼器。DTX解碼器是用來當作一個簡化的語音合成器,在沒有語音的存在下,從已接收的信號當中產生一個一致性噪音(conform estimate)的估計值。DTX處理運算的發生原因有許多種。如果DTX處理器決定將該輸入資料視為一個SID框架,它們會被DTX編碼器進行處理且會產生一致性噪音。除此之外,如果輸入資料被中斷了,這也將會引起DTX動作,以避免來自語音解碼器,令人懊惱且斷章取義(annoying garbled)的輸出。
LP濾波器的編碼運算
LSP相關係數是跨越四個次框架的內插(interpolated)結果,並被轉換成LP濾波器的相關係數。這些相關係數是用來創造重組輸出語音向量的合成濾波器之用。
幾何與適應性代碼簿向量與增益的解碼(Decoding the Algebraic and Adaptive Codebook Vectors and Gains)
在計算LP濾波器相關係數之後,適應性代碼簿向量是經由對所接受的pitch索引進行解碼運算而被發現的。對這個索引的解碼運算造成整數和分數的延遲。利用pitch延遲,透過對過去excitation所進行的內插,可以發現適應性代碼簿向量。幾何代碼簿向量可以透過脈衝位置和利用幾何代碼簿索引輸入參數的信號,來加以擷取。
適應性和幾何代碼簿的增益是從已接收的代碼簿索引計算而來的,這樣的索引直接提供適應性代碼簿增益和幾何代碼簿增益修正的因子(factor)。幾何代碼簿增益是經由修正的因子來估計和表示(scaled)的。
代碼簿增益和向量接著會經過後處理(post processing)路徑。代碼簿增益通過一個流暢的濾波器,以避免不自然變動。可以流暢處理的量是依靠接收器頻道(channel)的狀態與信號上是否有背景噪音來決定的。一個反稀少(anti-sparseness)的濾波器也在AMR的低位元速率的模式上執行;因為較低的速率只能針對在固定的(fixed)代碼簿上的一些非零的脈衝,因此這麼做是必要的。代碼簿向量是與三個預先儲存的脈衝回應當中的一個一起旋繞(convolved)。脈衝回應是根據絕對增益和是否有一個起始(onset)在語音信號上被偵測,來加以選擇的。基本上,固定的代碼簿變小,必須應用在代碼簿向量的反稀少濾波器就越強。
計算已合成的語音
已合成的語音的運算,是減去來自已計算的勵磁(excitation)的合成器當中那些已篩選過、過往的輸出。如果合成濾波器超過容量時,這個勵磁(excitation)的規模就會變小,然後其輸出會再一次地被合成。這個輸出是饋入到一個適應性的後部濾波器(postfilter)而最終將透過一個高通濾波器,來移除任何低於60Hz的疏漏輸出。這個時候,語音解碼工作已經完成而其輸出將被傳送到一個DAC(數位類比轉換器)上。
小結
本文對GSM行動電話應用的適應性多重速率(Adaptive Multirate;AMR)編解碼器軟體發展作簡介,包括發展經過、硬體使用,以及使用標準化團體所開發的參考程式碼;並針對此演算法和架構深入介紹。另外,我們將在下期介紹移植和測試程式碼的基本步驟,以提供讀者在使用或設計這類嵌入式演算法和硬體平台時的完整參考。
(作者為美商ADI DSP軟體工程師)
<參考資料:
[1] Nihal Kularatna, “Modern Component Families and Circuit Block Design”, Butterworth-Heinemann, 2000
[2] Phil Laplsey, Jeff Bier, Amit Shoham, Edward A. Lee: “DSP Processor Fundamentals”, Berkeley Design Technology, 1994-1996
[3] Heinen, S. et el: “A 6.1 to 13.3 kb/s variable rate CELP codec (VR-CELP) for AMR speech coding”, 49th IEEE-ICASSP ’99 Conference Proceedings, 1999, pg 9-12
[4] Corbun, O, Almgren, M and Svanbro, K: “Capacity and speech quality aspects using adaptive multirate (AMR)”, 9th IEEE Intl’ Syposium on Personal, Indoor and Mobile radio Communications, Sept 1998, pg 1535-1539.
[5] Hindelang, T.,et el,: “Improved channel coding and estimation for adaptive multirate (AMR) transmission”, Vehecular Technology Conf Proc., 2000, Tokyo, pp 1210-1214.
[6] http://www.etsi.org
[7] Digital Processing of Speech Signals, L. R. Rabiner, R. W. Schafer, pg 82, Prentice Hall, 1978
[8] Digital Processing of Speech Signals, L. R. Rabiner, R. W. Schafer, pg 398-404, Prentice Hall, 1978
[9] Digital Processing of Speech Signals, L. R. Rabiner, R. W. Schafer, pg 411-413, Prentice Hall, 1978
[10] Digital Coding of waveforms: Principles and Applications to Speech and Video, N. S. Jayant and P. Noll, Prentice Hall, 1984.
[11] Digital Speech, A. M. Kondoz, John Wiley and Sons, 1994.>