DSP是因應二次大戰期間軍事上的需求而發展出來,在戰後,DSP進入和平用途,應用在石油、深海礦物、衛星遠距探戡或者氣象分析上,直到1995年Intel將DSP嵌入CPU中,以多媒體指令MMX實現Dual Core發展出single chip解決方案,DSP才正式進入高階且平價的消費市場,DSP SoC也同時在寬頻通訊、數位控制、數位音頻與數位視訊等眾多市場獲得肯定。
根據Forward Concepts報告顯示,通訊仍然是今年DSP最大的應用市場,然而位居第二的消費性電子產品,隨著數位化發展趨勢,DSP又扮演著將類比轉為數位的重要轉換橋樑,預估自2004年起,DSP在消費性電子的應用將會挾帶龐大影響力進入人們的生活。
由於大眾對生活品質要求提高,同時帶動了消費性電子產品的需求量,而聲音在電子產品上的呈現要求,也從只是「聆聽聲音」進階至「聽覺享受」。DSP能即時處理大量訊號、處理速度快且成本低,其高品質的表現結果成為數位資訊產品的核心,而現階段音頻訊號透過DSP進行處理的依賴程度也就日益加深。由於人類可接收的聲音源是類比環境,(圖一)是說明將輸入的類比訊號轉為數位訊號,再將處理過的數位訊號轉為類比訊號過程。
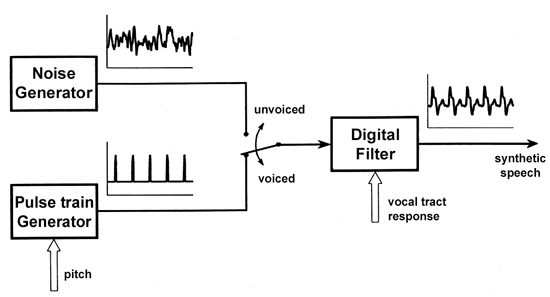
DSP的應用領用相當廣泛,在音訊上的工程技術包括回音消除、噪音抑制、語音處理(語音辨識、合成)、VOIP及聲音壓縮解壓;在應用產品上有DVD/CD播放機、音響合成器、數位錄音機、電子語音玩具、助聽器與網路電話等。其中,音訊處理主要部份又可分為聲音的處理及合成、音訊編碼及語音辨識。
百變聲音發明家─合成及處理
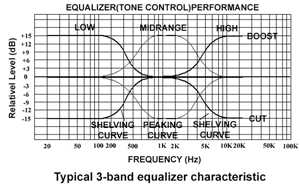
在音樂播放過程中,數位資料的呈現結果最重要是要防止在類比儲存和運作時所造成的音質損耗。等化器(Equalizer)能將不同頻率範圍的訊號分別濾出,然後再各別放大或縮小處理,最後再合成,所以能補償訊號的頻率衰減,使音質回復原音,或者也能補償輸入的不足,使音質達到理想狀態。由於人類的聽覺系統在低頻及高頻的接收上靈敏度較差,透過Equalizer強化或補足聲音的功能,能彌補人們在聽覺上的盲點。例如:將頻率為100Hz的組成泛音放大,就會讓聲音中100Hz左右的低頻部份聽起來震撼一些,若覺得聲音的低頻部份不夠明顯,也可以用等化器加以補足。像目前MP3播放器幾乎都有Equalizer的功能,使用者可選定或自定不同的播放音場(搖滾、爵士、流行音樂、抒情),充份表現出音樂的個性化。另外,變聲器(voice changer)是透過聲音處理技術改變原始的音源呈現,此種技術可廣泛應用在電話上做安全過濾或者調整播放音調及速度後,達到語音學習的目的,成為高階語言學習機的必備功能。
創造聲音的無限時間及空間─音訊編碼
為了滿足現代人對於儲存容量的需求,利用音訊編碼(Digital Audio Coding)可實現聲音數位化後小體積、複製時不會失真、容易保存及保密等優點。音訊編碼有許多種,針對聲音的編碼有PCM、ADPCM、DM、PWM、WMA、OGG、ACC、MP3Pro以及MP3等等,目前最常見的為MP3;針對人類語音有LPC、CELP與ACELP,文中會以CELP做介紹。
MP3聲音編碼
MP3是MPEG 1 Layer III的簡稱,是由MPEG(Moving Pictures Expert Group)所制定的影音壓縮─聲音部分。目前已在市場上銷售的MP4,並非是MP3的延伸,MP4是指小尺寸螢幕的視訊產品,MP3具有可攜式「隨身聽」的特色,而MP4的小螢幕設計卻與人類一般的視覺習慣背道而馳,也減損了「隨身看」的原意。
MP3的編碼原理主要是利用人耳聽覺的特性,從聲音中去除人耳聽不到的資訊。人耳因為構造的關係,在接收聲音時均會在頻率與時間上產生遮蔽效果(masking)。所以MP3根據這樣的特性採取了「感官編碼技術」(perceptual coding techniques),即編碼時先對音頻資料進行頻譜分析,利用人耳聽覺上的遮蔽效應,將量化雜訊限制在人耳無法察覺的範圍內,除了能夠提供高壓縮效率,還能保持非常好的音質。
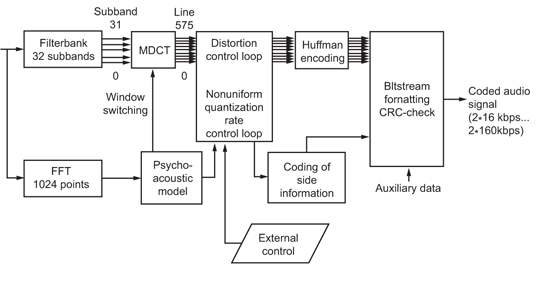
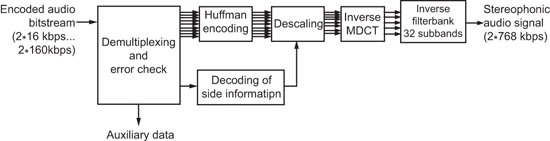
(圖三)為MP3壓縮編碼的方塊圖,訊號輸入為PCM格式2×768kbps,經過filter bank將訊號分為32個子頻帶,同時PCM訊號經FFT轉換後,利用人耳的心理聲學模型(Psycho-acoustic model),決定必須量化的頻譜與量階並進行第一次的編碼(失真壓縮)。編碼結果再用無失真壓縮作第二次編碼(Huffman encoding)。最後因應通訊需求,加上封包資訊與錯誤更正碼,即完成編碼過程。而解碼過程即為編碼反運算(圖四),將封包解開後,經過Huffman decoding,得到量階與頻譜,再經反離散餘弦轉換(IMDCT)及filter bank將各頻譜訊號組合,即可還原成PCM訊號。
DSP大量使用在聲音處理部份,像CD播放機的聲音輸出便是使用DSP進行Reed Soloman Code的編解碼,因而即使音軌上有些許損毀,還是能自動更正錯誤,撥出毫無受損的音樂。此外,高階DAC(Digital Analog Converter)中的△Σ也是利用DSP進行雜訊整型,可將訊號頻帶內雜訊抑制至最低而達到高訊雜比(SNR),讓聲音擁有更真實完美的呈現。
CELP語音編碼(Code excited linear prediction)
CELP是近來最成功的語音編碼演算法,具有語音品質清晰及計算量合理之優點。CELP是一種高效率(壓縮比較高)的語音編碼技術,由於採用了感覺加權、分析合成、向量量化和後濾波等技術,CELP能夠在中低速率上完成高品質的合成語音。像同樣128Mb Flash的記憶容量,以ADPCM進行編碼,只有8小時的儲存空間,而CELP編碼卻能達到36小時。不過,CELP在6~8k的頻寬環境下使用,能維持較佳的音質,而在4kbps的速率時,激勵碼原始尺寸小,因此合成語音品質較差。為了提高此速率的合成品質,往往需要增加處理長度(例如30ms或更長),不過,這會使編碼延長時間,另外還需要增加演算法複雜度和記憶體容量,才能得到令人比較滿意的合成語音品質。目前CELP已經被許多語音編碼標準所採用,除了高品質的窄帶語音保密通信外,需要長時間錄音(10小時以上)的消費性產品,如錄音筆或錄音棒也是使用CELP技術。
只動「口」不動手的年代─語音辨識
英特爾的創辦人摩爾在接受媒體專訪時,曾直指「語音技術」將是影響未來科技發展最關鍵的技術,「半導體教父」的預言,讓語音技術的發展,頓時受到全球的注目。所謂語音辨識最主要目的是讓電子設備,譬如電腦能聽懂人類說話的語言或命令,而做出相對應的工作。當聲音藉由類比到數位的轉換裝置輸入電腦內部,並以數位方式儲存後,語音辨識程序便開始啟動,將事先儲存好的聲音樣本與輸入的聲音樣本進行比對工作。聲音比對工作完成之後,辨識程式會輸入一個它認為最“像”的聲音樣本序號,理解使用者剛剛發出聲音的意義,進而命令電腦做事。
但要真正建立辨識率高的語音辨識程式,卻是非常困難而專業的。例如:“聲音樣本”要如何建立呢?簡單來說,如果要辨識10個字,那就是先把這10個字的聲音輸入電腦中,存成10個參考樣本,辨識時,只要將本次所輸入的聲音(測試樣本)與事先存好的10個參考樣本一一對比,找出與測試樣本最像的樣本,即可把測試樣本辨識出來。但是,別忘了語音訊號還有一項重要的特性:在不同時間,雖然說的是同一句話或相同的音,但其波形卻不盡相同,也可以說語音是一種隨時間而變化的動態訊號,做語音辨識就是要從這些動態訊號中找出規律性,一旦找到規律性之後,訊號再怎麼變化,大致都能擷取出它們的特性,進而將它們辨識出來。這種規律性在語音辨識上稱為特徵參數,也就是能夠代表訊號特性的參數,語音辨識的基本原理就是以這些特徵參數做基礎。
要建立一個語音識別系統僅有一組好的語音特徵還不夠,還要有一個好的語音識別模型和演算法。目前,在研發完成的語音識別系統中,基於統計的HMM演算法可能是最為成功的一種。現今所見的各種性能優良的連續語音識別系統,幾乎無一例外地採用這種模型。這是因為這種數學模型出現的時間較早,人們對它的研究比較深入,也已建立起完整的理論框架。這種隱含馬爾可夫模型的演算法是將語音看成是一連串特定狀態,這種狀態是不能被直接觀測到的,而是以某種隱含的關係與語音的特徵相關聯。而這種隱含關係在HMM模型中通常是以機率形式呈現,輸出結果也是以機率形式表示,為系統最後的穩健判斷創造了條件。
目前的語音辨識系統已達到可接受的程度:手機可用語音聲控撥號,汽車的衛星導航系統也能透過語音「說」出路線。
數位聲音全面進攻消費性電子
現階段以DSP來發展消費性電子並未存在高難度的技術障礙,目前所要關注的重心反而是針對整體系統的瞭解並做最佳化的設計。由於系統的彈性與效率通常無法兼顧,愈有彈性的架構設計,其執行效率就會愈低;反之,執行效率愈高,作業系統通常就愈沒有彈性。所以設計者在做技術架構規劃時,就必須在彈性度與專業度間取捨並做最佳的判斷。另外,由於消費性電子的使用對象是一般大眾,在追求經濟成本的目標時,除了硬體架構設計外,也要保留軟體的修改空間,以軟硬體最佳化方式來追求最佳成本。
DPS未來的發展重點將是低耗電量、更快的時脈速度與價格的競爭,尤其在可攜式產品的應用上,如何提升效能又同時兼顧耗電量的問題,乃是最需要重視的問題。而在音訊處理方面,也有很大的改進空間,聲音合成要創造出更真實、更自然、更豐富的聲音;在聲音壓縮方面,再繼續提高壓縮比率,以更少的空間儲存更多的資訊並保有更真實的聲音;在聲音辨識方面,希望能做到讓機器產生更好的反應,開發出更加友善的使用產品。而噪音抑制技術愈加成熟後,人們也將享受到整體聲音環境的提昇。
結語
隨著數位化進程的加速,未來數位訊號將會取代更多的類比訊號環境,這意謂將有更多的音訊產品採用DSP作設計。例如:擴大機數位化後,在可接受的音質範圍內,D類放大器更能達到高效能運作,其它像數位電話、數位廣播、數位電視等相關音效設備,也都將促進DSP的蓬勃發展。目前音樂的儲存格式早已由CD取代傳統的Tape,如今在數位可攜式音樂的浪潮推進下,MP3格式大眾化的年代已經宣佈來臨。雖然仍有許多技術問題尚待克服,但聲音的數位化顯然正在快速前進中,將帶給人們生活上更多的便利與享受。(作者為AT-Chip演算科技行銷企劃部副理)
|
|
 |
設計一個語音辨識程式,至少又有兩方面的知識:瞭解如何把外界的聲音訊號抓到電腦內部處理。相關介紹請見「何謂語音辨識」一文。 |
|
語音辨識技術應用之發展趨勢。你可在「語音辨識及語音合成」一文中得到進一步的介紹。 |
|
手機與 PDA 已能夠提供各種不同娛樂功能,而消費者更希望其能夠擁有立體聲,甚至是 3D 音效。在「手機與PDA之聲頻系統應用探微」一文為你做了相關的評析。 |
|
|
 |