賽靈思All Programmable元件與工具支援從二進位到雙精度浮點在內的多種資料類型。相較於浮點運算,執行於定點運算的設計擁有更高的效能,由於定點運算僅需消耗少許的資源和功耗。當設計遷移到定點時,功耗與占用面積縮減一半也不稀奇。
相較於浮點,定點資料類型的優勢,包括:
‧ 邏輯資源使用減少
‧ 功耗降低
‧ 材料成本降低
‧ 延遲縮短
支援的資料類型
賽靈思所有元件均支援需要浮點資料類型所提供的動態範圍之客戶,並提供高達7.3TFLOP的單精度浮點DSP效能。
賽靈思工具套件提供浮點支援。Vivado高階合成技術(HLS)和DSP系統產生器(System Generator)本身均支援可變的浮點精度,包括半精度(FP16)、單精度(FP32)及雙精度(FP64);系統產生器亦支援具較大彈性的客製化精度。這些工具本身也支援可變定點資料類型。
表1:賽靈思工具支援浮點與定點資料類型 (註1-2)
賽靈思工具 |
FP16 |
FP32 |
FP64 |
客製化FP |
定點 |
Vivado HLS |
Y |
Y |
Y |
N |
Y |
DSP系統產生器 |
Y(1) |
Y |
Y |
Y |
Y |
浮點運算IP |
Y |
Y |
Y |
Y |
Y(2) |
賽靈思元件和工具提供的可變精度資料類型,可提供客戶簡單且彈性的解決方案,來調整並適應業界的趨勢變化,例如圖像分類只需要INT8或更低的定點運算,就能保持可接受的推論精度。
用於高運算密集工作負載的GPU等其他元件,傳統上其結構僅用於有效支援單精度浮點,而這些廠商現已開始重新設計產品,來因應趨勢的變化。然而,賽靈思的可擴展架構讓客戶能擴展單訊號處理鏈的精度,以滿足業界日新月異的需求。
客戶在選擇運用浮點還是定點訊號處理鏈時,必須在功耗、成本、生產力與精度之間仔細權衡。
賽靈思彈性的DSP48E2分割(Slice)可在進行重要的DSP運算時,適用於所有資料類型。當運行新定點設計或針對某些應用將現有設計從浮點轉換成定點(當轉換為適用選項)時,DSP分割與賽靈思工具集相結合能帶來巨大優勢與彈性。
對於採用C/C++語言設計的客戶,賽靈思提供Vivado HLS並支援任意精度定點資料類型,使客戶能輕鬆地採用定點進行設計,或將現有的C/C++設計轉換為定點。
浮點轉換為定點的優勢
對目前幾乎所有的設計來說,將功耗最小化是首要目標,且大多數的應用產品必須先滿足嚴格的功耗和散熱範圍需求才能投產。
相較於較低精度,目前普遍接受的原則是在浮點內的設計會導致較高的功耗。對FPGA來說也一樣,其中的浮點DSP模塊在FPGA中已被強化,且客戶必須使用提供的DSP資源與其它FPGA資源來運行軟解決方案。浮點方案與同等的定點解決方案相比,會使用較多FPGA資源,且當資源使用增加,功耗則隨之增大,最終會提高設計運行的總成本。
將浮點設計轉換為定點設計能透過以下方法,來滿足具挑戰性的規範:
‧ 減少FPGA資源
。使用定點資料類型時,需較少的DSP48E2、查表(LUT)與正反器。
。儲存定點數所需的記憶體容量更小。
‧ 降低功耗
。減少FPGA資源利用自然會降低功耗。
‧ 降低材料成本
。設計人員能在相同成本內運用附加的可用資源,為其應用獲得額外功能。
。資源的節約能大幅提升FPGA的運算能力,提升的運算能力能讓許多應用受益,例如機器學習DNN。
。資源的節省也許能縮小設計所需的元件尺寸。
‧ 降低延遲
。 運行FIR時減少所佔用的資源,尤其是DSP48E2分割,能降低定點設計的延遲。
‧ 相近的效能和精度
。對於不需要用浮點來達到動態範圍的設計與應用,定點方案能提供相近的結果與精度,在某些情況下,結果甚至更好。
過去由於缺乏工具支援,因此難以將設計從浮點轉換為定點。對於選用賽靈思All Programmable元件的C/C++開發人員來說,使用Vivado HLS可減少轉換過程中的挑戰。
這種轉換能帶來許多優勢,因此在適用情況下應認真考慮,尤其是不需要利用浮點來達到動態範圍與浮點精度的設計,以及預期內少量的精度損失不會導致部署後應用效能降低。
實例:將浮點FIR濾波器轉換為定點
Vivado HLS中簡單的FIR濾波器設計可用來展示當浮點FIR設計轉換為定點設計時,如何減少所用資源和功耗,並達到相近的結果精度。
單精度浮點FIR
在C++ FIR函數代碼中,頂層函數在FIR.h標頭檔(header file)中找到的CFir類別(class CFir)的實例化。
#include “FIR.h ”
// Top-level function with class instantiated
fp_acc_t fp_FIR(fp_data_t x) {
#pragma HLS PIPELINE
static CFir fir1;
return fir1(x);
}
CFir類別是主要的FIR演算法,在標頭檔中被定義為FIR.h
// FIR main algorithm
template
acc_T CFir::operator()(data_T x) {
//caller uses #pragma HLS PIPELINE which makes this function pipelined as needed.
#pragma HLS ARRAY_PARTITION variable=c complete dim=1
#pragma HLS ARRAY_PARTITION variable=shift_reg complete
dim=1
int i;
acc_T acc = 0;
data_T m;
loop: for (i = N-1; i >= 0; i--) {
if (i == 0) {
m = x;
shift_reg[0] = x;
} else {
m = shift_reg[i-1];
if (i != (N-1)) {
shift_reg[i] = shift_reg[i - 1]; }
}
}
acc += m * c[i];
}
return acc;
}
此函數包含重要的ARRAY_PARTITION編譯指示,以確保設計的所有運行方案都是II=1(迭代區間為1),而PIPELINE編譯指示也被應用於頂層函數調用。
這些編譯指示、平行產品運行及用於執行累加的加法樹,無論任何資料類型,都能確保整個FIR函數維持最低延遲,並保持II = 1。
在fp_FIR函數中,fp_coef_t、fp_data_t和fp_acc_t都被定義為浮點類型,即C++原生的單精度浮點資料類型。
// float
typedef float fp_coef_t;
typedef float fp_data_t;
typedef float fp_acc_t;
通過標頭檔中的include指令加載濾波器係數。
template
const coef_T CFir::c[] = {
#include "FIR_fp.inc"
};
用係數創建一個對稱的FIR濾波器,但在本例中,未使用DSP48E2分割中的預加器,若使用預加器,則能達到更高效率。
以下是針對85-tap FIR濾波器在C合成及在Vivado HLS中執行,並採用XCVU9P-2FLGB2104元件上的400MHz時脈(2.5ns 時脈週期)所得到的結果。詳見表2。
表2:單精度浮點FIR運行後的結果
單精度浮點(FP32) |
最大頻率(FMAX) |
500MHz |
延遲(時脈週期) |
91 |
迭代區間(II) |
1 |
DSP48E2 |
423 |
查表(LUT) |
23,101 |
本例中,需要423個DSP48E2及約23,000個查表來運行單精度浮點FIR,運行結果顯示延遲為91個時脈週期,最大頻率(FMAX)為500MHz(遠高於目標400MHz)。
轉換到定點FIR濾波器
為了達到最高DSP效率,浮點到定點的轉換必須考慮DSP分割的匯流排寬度,即27x18位元乘法器和48位元累加器。若進一步將匯流排寬度縮減至設計允許的最小值,能在資源與功耗上獲得最大的回饋。
針對此FIR濾波器實例,定義以下定點資料類型以匹配DSP48E2分割中的匯流排大小,即18位元係數中1個整數位元和17個小數位元;27位元資料中15個整數位元和12個小數位元;以及48位元累加器中19個整數位元和29個小數位元。
// fixed points
#include
typedef ap_fixed<18,1> fx_coef_t;
typedef ap_fixed<27,15> fx_data_t;
typedef ap_fixed<48,19> fx_acc_t;
要使用Vivado HLS原有的ap_fixed資料類型,必須包含ap_fixed.h標頭檔,以定義任意定點資料類型。
採用400MHz時脈(2.5ns時脈週期)和XCVU9P-2FLGB2104元件,其C合成與運行定點FIR設計後所產生的結果,如下表3所示。
表3:比較兩種設計運行後的結果
? |
單精度浮點 |
定點 |
定點優勢 |
FMAX
(運行後) |
500MHz |
580MHz |
提高16% |
延遲 |
91 |
12 |
降低約7.5倍 |
迭代區間(II) |
1 |
1 |
- |
DSP48E2 |
423 |
85 |
DSP效率提高5倍 |
查表(LUT) |
23,106 |
1,973 |
邏輯效率提升11倍 |
正如結果所顯示,當重視延遲與FPGA資源利用率時,可獲得明顯的改善。
在UltraScale架構中,可將多個DSP48E2分割串聯,以支援更高的匯流排寬度。採用串聯DSP48E2分割的定點設計,與浮點方案相比仍可顯著減少資源使用與功耗。
比較濾波器精度
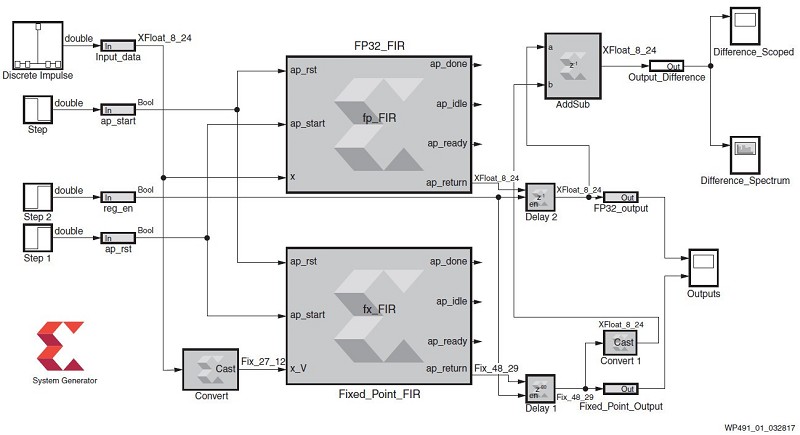
在DSP系統產生器中,使用來自賽靈思模組集的Vivado HLS模塊,能在MATLAB/Simulink環境中,針對兩種FIR濾波器的運行方案進行比較。如圖1所示。
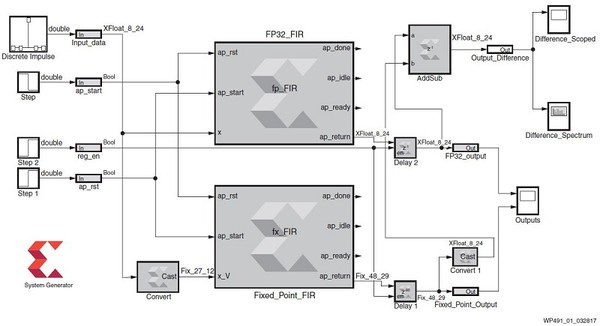
| 圖1 : DSP系統產生器模型─使用兩種HLS解決方案進行分析 |
|
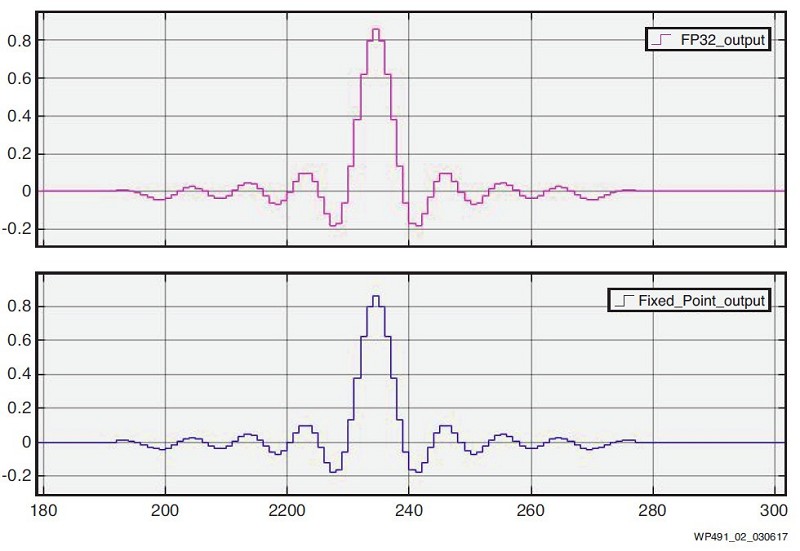
系統產生器模型由兩個Vivado HLS模塊所組成,其配置包含來自Vivado HLS的單精度浮點(FP32)和定點FIR解決方案。兩個模塊具有相同的輸入和離散脈衝訊號,然後在Simulink示波器上比較每一個FIR輸出。如圖2所示。
為了方便比較,有必要延遲定點結果,以按照兩種解決方案之間的延遲差進行比對。
正如預期,兩種FIR濾波器產生的結果幾乎相同,且差異很小。
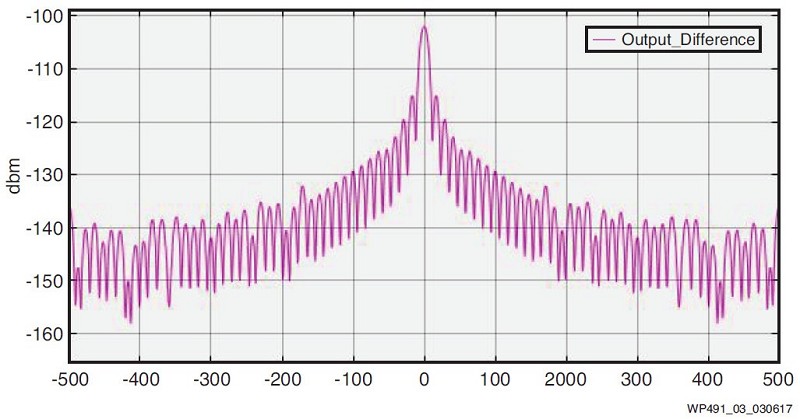
為進一步分析訊號,將兩個輸出相減,如圖3的光譜分析所示,若訊號在 -100dBm至 -160dBm範圍內,其精度損失非常小。
關鍵優勢
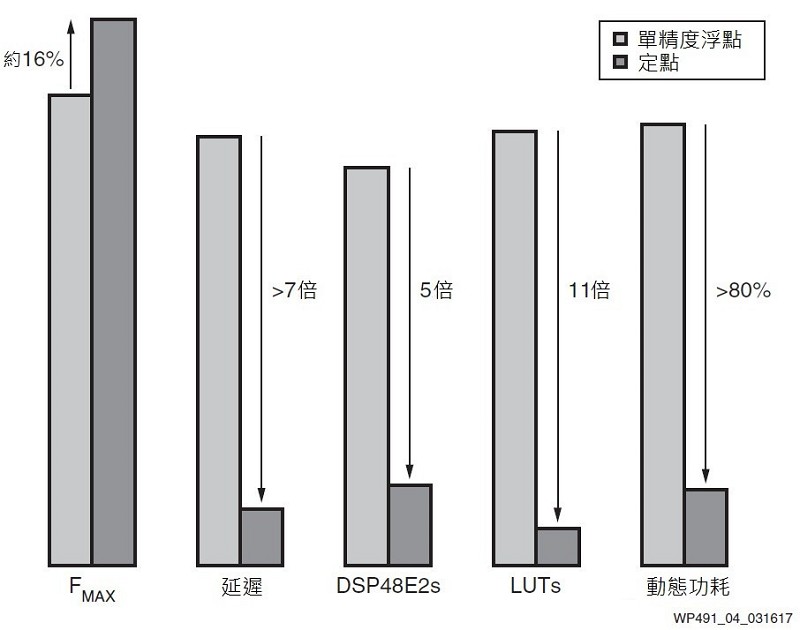
當把原始單精度浮點FIR濾波器與轉換後定點FIR濾波器的結果進行比較時,發現定點設計不僅減少了資源使用與延遲,同時還能保持甚至改善設計的最大頻率(FMAX)。如圖4所示。
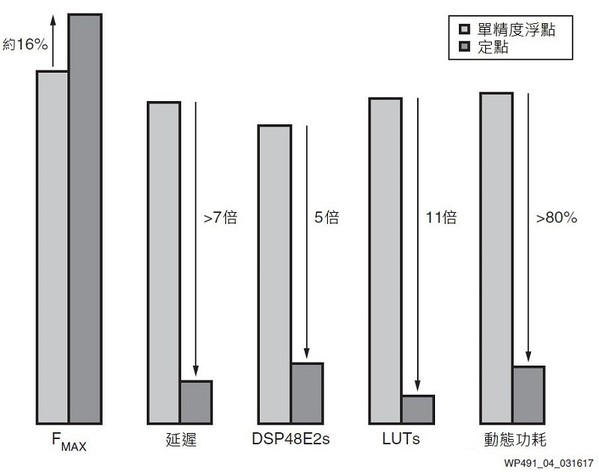
| 圖4 : 定點─效能相近,並減少延遲、資源使用和功耗 |
|
大幅減少FPGA資源的使用
本例中的定點FIR比原始浮點FIR小五倍以上。
精選出的匯流排寬度是為了優化映射到硬體中的DSP48E2分割。這允許每個相乘都在一個DSP48E2分割中完成,並與每個85係數平行,讓DSP48E2分割的使用量降低到只有浮點解決方案的20%。
在FPGA架構中,查表也大幅節省約90%,因定點方案無需額外的查表來建構浮點運算。
若一個設計有10個FIR濾波器,其預期的功耗會隨設計而擴展。表4顯示在10個FIR濾波器設計的單精度和定點運行方案中,XCVU9P FPGA資源使用率的結果。此設計中,比較單精度浮點與定點運行的資源使用率時,有明顯地差異。
表4:擁有10個FIR濾波器的兩種資料類型解決方案的資源使用
? |
DSP48E2 |
查表(LUT) |
資源總量 |
元件使用 |
資源總量 |
元件使用率 |
單精度浮點 |
4,230 |
62% |
231,060 |
20% |
定點 |
850 |
12% |
19,730 |
2% |
顯著的資源節省能獲得多種優勢,為設計人員帶來深遠的影響,有助於改善設計的功能集、功耗、效能及成本。
達到顯著的功耗節省
節省大量的資源能夠相應地降低功耗。
比較本文中提到單個FIR濾波器的兩種運行方案,其功耗估算結果發現,定點FIR的功耗減少1.4W。兩種方案中,元件的靜態功耗略高於3W,而單個單精度浮點FIR設計的總功耗為4.7W。當定點FIR功耗為3.3W時,表示該設計的動態功耗節省80%以上。
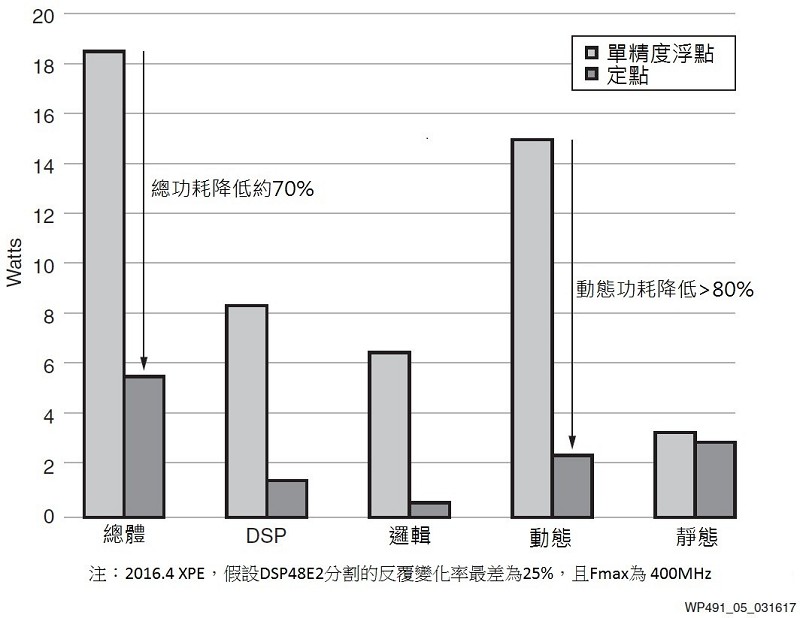
再來看10個FIR濾波器的設計,可利用賽靈思功耗評估器(XPE)針對兩種運行方案的功耗進行評估,並於表4中顯示運算的資源,而圖5為功耗節約的比較圖。
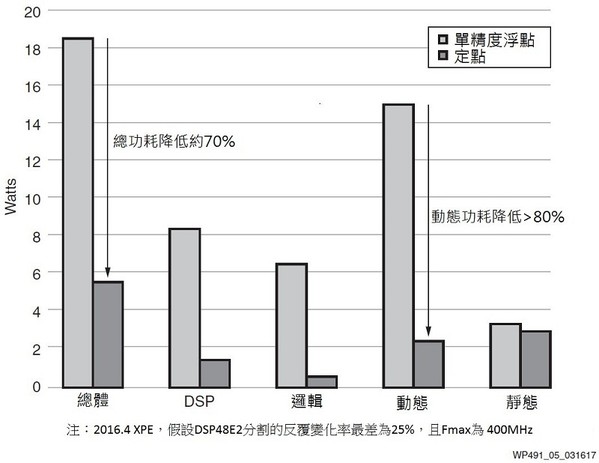
| 圖5 : 10個FIR濾波器實例:利用定點達到顯著的功耗節約 |
|
在此10個FIR濾波器實例中,當把設計轉換成定點資料類型時,其總功耗能節省高達70%。對於大量使用大量FPGA資源的浮點訊號處理設計,可透過將部分或全部浮點訊號處理鏈轉換為定點,來實現巨大的節能效果。
削減材料成本
將浮點設計轉換成定點方案,能大幅減少FPGA資源使用率。FPGA資源的削減能降低材料成本。可通過以下三種方法來實現:
1.可利用最新的FPGA資源來擴增應用功能集。
2.由於FPGA資源大量減少及通過資料路徑提高FMAX,因此FPGA的總體運算能力明顯增加。
3.由於所需的FPGA資源減少,因此設計可遷移到更小型的賽靈思FPGA中。
相近的精度
通過比較單個FIR濾波器設計的兩種運行方案之輸出,會發現定點運行方案提供相近的濾波器精度,精度損失僅為 -100dBm至 -160dBm之間,並且能獲得降低功耗與成本的優勢。
然而,定點方案無法獲得相同的動態範圍,導致設計中出現可預測的精度損失。由於許多設計僅需低標準的精度,因此這並不構成任何問題,且這類設計與單個FIR實例類似,所以很適合轉換為定點。
對於需要更高精度值的設計,有時可將訊號處理鏈中的中間值從浮點轉換為定點,但此方案僅可讓設計人員能夠將特定部分(而非全部)轉換為定點。最終,設計人員能夠在需要時保持動態範圍,並確保維持資料路徑的精度下,同時充分發揮定點運行方案帶來的部分優勢。
改善延遲
在單個FIR設計實例中,可通過濾波器降低延遲,從浮點設計的91個時脈週期降低為定點運行方案的12個時脈週期。隨著資源用量減少,尤其是DSP48E2分割的用量減少,則有望降低延遲。
除了降低延遲,在單個FIR實例中,還能提升FMAX;運行之後的FMAX可提升16%。
結論
賽靈思All Programmable元件和工具支援多種資料類型,包括浮點和定點的多種精度。使用浮點的設計與使用定點的同一設計相比,資源用量和功耗都來的更高,無論採用FPGA或其他如GPU的架構皆是如此。
某些應用領域已開始放棄浮點資料類型,例如深度學習推論工作負載運用INT8或盡可能地使用更低的精度,這已經成為明顯的產業趨勢。
如今的設計環境極具挑戰,散熱及功耗的要求越來越難以滿足,因此設計人員必須評估各種方法來降低功耗,其中一種選擇就是將浮點設計轉為定點。
若使用C/C++,Vivado HLS等賽靈思工具有助於簡化轉換過程。
設計人員必須對定點資料類型的轉換進行充分權衡,並充分理解這樣做所能帶來的巨大優勢。
繼續使用浮點雖是通向市場的捷徑,但其成本較高。因此,若投入時間與精力轉換成定點,將能降低資源使用量、成本和功耗,且降低效能損失,進而獲得更大的優勢。
(本文作者Ambrose Finnerty1、Herve Ratigner2為Xilinx公司1DSP技術行銷主任工程師、2軟體應用工程師)
註:
1.DSP系統產生器原本不支援FP16,但支援客製化FP16。
2.浮點運算核心支援轉換→定點到浮點、浮點到定點轉換,以及浮點到浮點的精度變換。