Xilinx 深度神經網路(xDNN)引擎使用 Xilinx Alveo資料中心加速器卡提供高效能、低延遲的 DNN 加速。通過保持較低能源成本以及最大限度地減少運行過程中所需的特定加速器的數量,可以顯著降低總體擁有成本。本文概述 xDNN 硬體架構和軟體堆疊,以及支援高能效推論聲明的基準資料,幫助讀者實現Alveo資料中心加速器卡上的結果再創造。
資料中心應用的深度學習關聯性
在過去幾年中,深度學習方法在各種應用領域均取得了巨大成功。應用機器學習(ML)的一個領域是視覺和視訊處理。互聯網上的視訊內容在過去幾年中也迅速增長,對圖像整理、分類和辨識方法的需求也相應增長。
卷積神經網路(CNN)是ML神經網路的一種,其一直是處理圖像資料的有效方法,尤其是在資料中心部署的背景下。CNN圖像網路可用於對雲端中的圖像進行分類和分析。在許多情況下,影像處理的延遲對最終應用至關重要,例如標記流視訊中的非法內容。
賽靈思深度神經網路(xDNN)引擎是一款可編程推論處理器,其能夠在賽靈思Alveo 加速器卡上運行低延遲、高能效的推論。xDNN推論處理器通用CNN 引擎,支援各種標準的CNN 網路。
xDNN引擎通過xfDNN軟體堆疊整合到諸如Caffe、MxNet和TensorFlow等ML框架中。在Alveo加速器卡上運行的xDNN處理引擎,能夠以每秒GoogLeNet v1傳輸率4,000或更多圖像的速度進行處理,意味著在Batch = 1時超過70%的運算效率。
正如該運算效率所述,運行在賽靈思 Alveo 加速器卡上的 xDNN,在落實低延遲推論方面優於 GPU 等加速平台。眾所周知,GPU 平台能夠通過同時批次處理多個圖像來提高其效能;然而,雖然批次處理可以提高效能並減少所需的 GPU 記憶體頻寬,但批次處理的副作用是延遲顯著增加。
相比之下,xDNN處理引擎不依賴於批次處理來達到最大化的傳輸率效能。而是每個引擎獨立運行,並且不共用權重記憶體。每個引擎在Batch = 1下運行,並且可以在單個Alveo加速器卡上實現多個引擎。因此,增加元件中 xDNN 引擎的數量僅增加了聚合元件 Batch = 1 的傳輸率。
xDNN架構概覽
xDNN硬體架構如圖1所示。每個xDNN引擎由一個脈動陣列、指令記憶體、執行控制器和元素級處理單元組成。引擎通過指令佇列從在主處理器上執行的命令軟體接收張量指令。僅當目標網路改變時,CNN網路的指令(張量和記憶體操作)才改變。重複執行相同的網路,會重複使用先前載入的駐留在指令緩衝器中的指令。
xDNN 處理引擎架構亮點
‧ 雙模式:傳輸率最佳化或延遲最佳化
‧ 命令級並存執行
‧ 硬體輔助圖像分塊
‧ 客製層支援(異質執行)
‧ 脈動陣列架構
傳輸率和延遲最佳化模式
xDNN處理引擎的架構特性之一是包括兩種操作模式,一種用於傳輸率最佳化,另一種用於延遲最佳化。在傳輸率最佳化模式中,通過創建最佳化的處理引擎(PE)來利用資料流程並行性,以處理低效映射到一般脈動陣列的特定層。
例如,GoogLeNet v1的第一層是RGB層,占整體運算開銷的近10%,不能有效地映射到有效運算網路其餘部分的脈動陣列。在此傳輸率最佳化模式中,xDNNv3 包括為三個輸入通道定制的其他脈動陣列。這種變化的網路效應是更高的整體運算效率,因為可以在先前圖像卷積和 FC 層完成其各自的處理的同時,運算下一圖像的第一層。
對於需要最低單圖像延遲的應用,使用者可以選擇部署延遲最佳化版本的引擎。對於這些應用,可以調整 xDNN PE 管線以減少延遲。
命令級並存執行
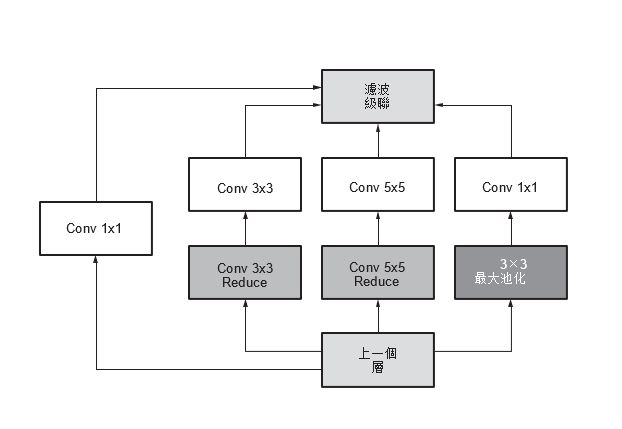
xDNN 處理引擎為每種類型的命令(下載、Conv、池化、元素級和上傳)提供專用的執行路徑。如果網路圖允許,則允許卷積命令與其他命令並行運行。某些網路圖具有不同指令類型的並行分支,有時允許並行處理。例如,在 GoogLeNet v1 inception 模組中,3 x 3 最大池化層是一個層的主要實例,該層可以使用 xDNN 處理引擎與其他 1x1/3x3/5 x 5 卷積並行運行,圖2 顯示了 GoogLeNet v1 網路的 inception 模組。
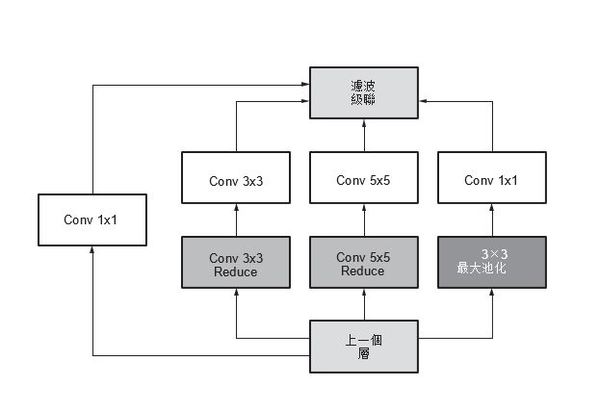
| 圖2 : GoogLeNet v1 中的 Inception 層 |
|
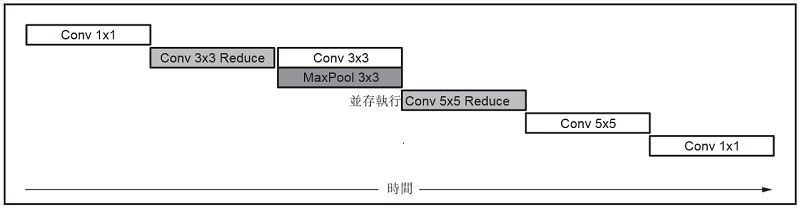
如圖3 所示,軟體可以與第二個分支的 3 x 3 卷積並行地調度 3 x 3 最大池化。
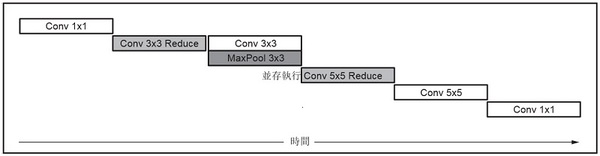
| 圖3 : GoogLeNet v1 中 Inception 層的 xDNN 調度 |
|
硬體輔助圖像分塊
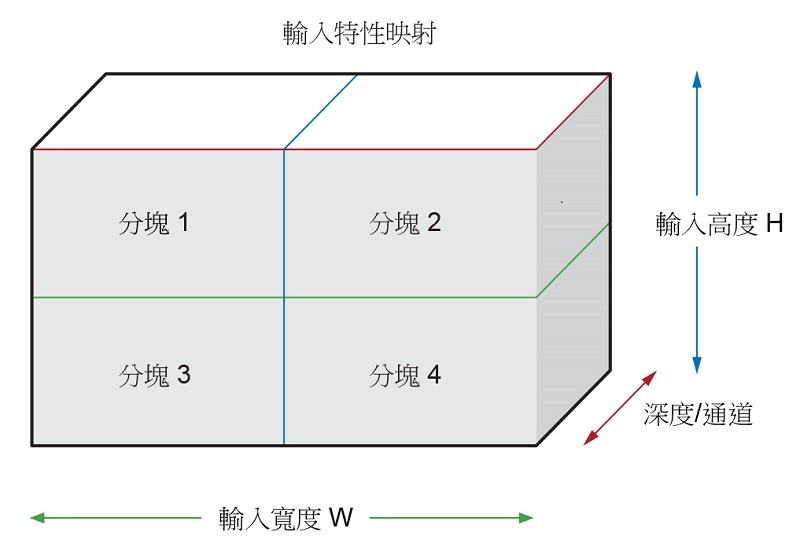
xDNN 處理引擎具有內置的硬體輔助圖像分塊功能,用來支援具有大圖像/啟動大小的網路。xDNN 處理引擎允許跨寬度和高度的輸入特性映射分塊。如圖4所示。
硬體輔助圖像分塊採用單個非資料移動指令(Conv、Pool、EW)並生成正確的微操作序列(下載、操作、上傳)。通過將啟動記憶體邏輯分區為兩個區域(如雙緩衝區),微操作在硬體中完全實現管線化。
通過異質執行客製網路支援
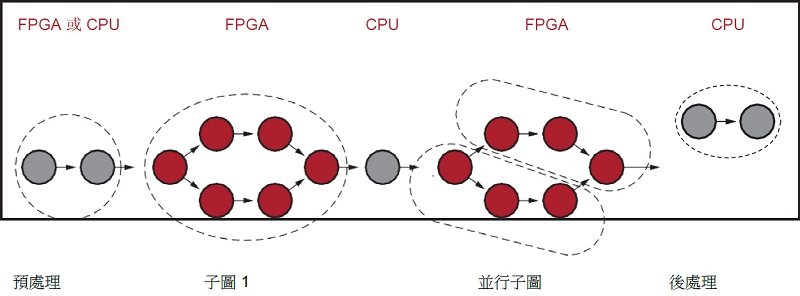
儘管 xDNN 處理引擎支援廣泛的 CNN 操作,但新的客製網路仍在不斷開發中 - 有時,FPGA 中的引擎可能不支援選擇層/指令。由 xfDNN 編譯器來辨識 xDNN 處理引擎中不受支援的網路層,並且可以在 CPU 上執行。
這些不受支援的層可以位於網路的任何部分 - 開始、中間、結束或分支中。圖5顯示了編譯器如何將處理劃分到 xDNN 處理引擎甚至 CPU 中的各種 PE 上
脈動陣列架構
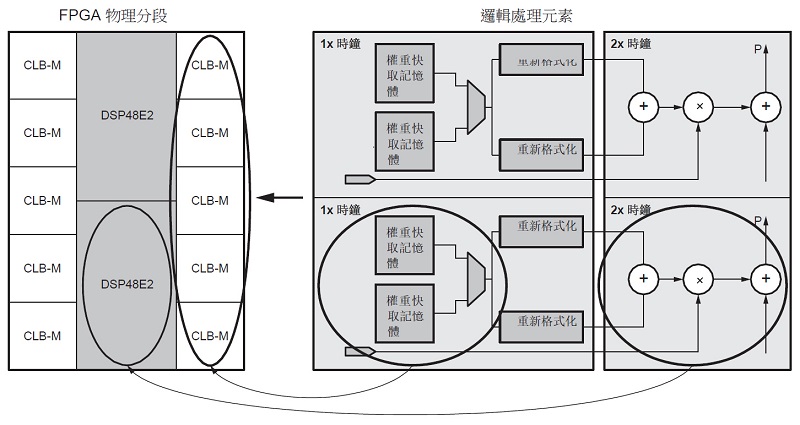
xDNN處理引擎利用諸如“SuperTile”論文(1)中描述的技術來達到高工作頻率。這個SuperTile DSP 巨集提供了一個關係放置的宏,其可以進行分塊以構建更大的運算陣列,例如矩陣乘法和卷積,這是 CNN 運算最為密集的操作。
圖 6 顯示了映射到FPGA中的DSP48和CLB-M(LUTRAM)分塊的邏輯處理元件的實例。該巨集單元是 xDNN 脈動陣列中的基本處理單元。
xfDNN 軟體堆疊概覽
xfDNN 軟體堆疊是軟體工具和 API 的組合,其可通過各種常見的ML框架落實xDNN 處理引擎的無縫整合和控制。圖7中的流程圖詳細說明了如何準備網路和模型,以便通過Caffe、TensorFlow或 MxNet在 xDNN上進行部署。在CPU上運行不受支援的層的同時,xfDNN編譯器還支援xDNN層。在編譯和量化網路/模型之後 - 該流程通常需要不到一分鐘 -使用者可以通過選擇簡單易用的Python或 C++ API與xDNN處理引擎進行介面連接。
賽靈思 xfDNN 軟體堆疊包括:
網路編譯器和最佳化器
編譯器產生在 xDNN 引擎上執行的指令序列,其提供張量級控制和資料流程管理,以實現給定的網路。
型號量化器
量化器從經訓練的CNN網路模型產生目標量化(INT8 或 INT16),而無需數小時的再訓練或標記的資料集。
執行時間和調度器
xfDNN簡化了xDNN處理引擎的通訊和程式設計,並利用了符合SDx的執行時間和平台。
圖8顯示了xfDNN函式庫的流程圖,其將深度學習框架與在賽靈思FPGA上運行的xDNN IP相連接。
xfDNN編譯器的更多資訊
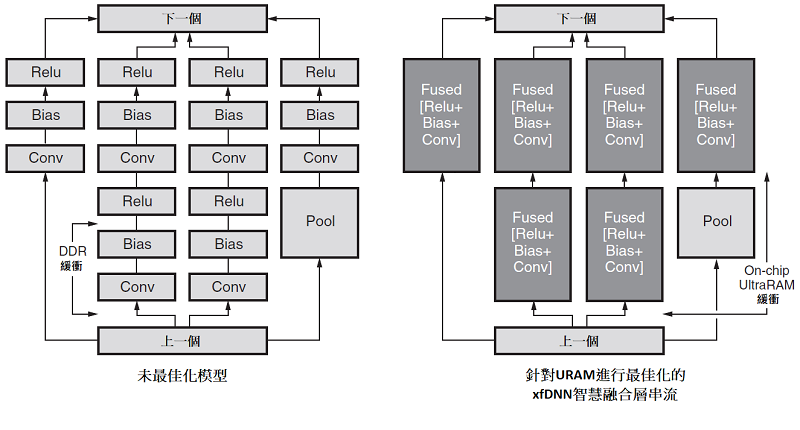
現代CNN是數百個單獨操作的圖表,即卷積、Maxpool、Relu、偏置、批次處理規範、元素級加法等。編譯器的主要工作是分析CNN網路並生成在xDNN上執行的最佳化指令集。xfDNN編譯器不僅提供簡單的Python API來連接到高級ML框架,而且還通過融合層、最佳化網路中的記憶體相關性,以及預調度整個網路來提供網路最佳化工具。這消除了CPU主機控制瓶頸。請參見 圖 9 作為實例。
效能基準測試結果
隨著即時AI服務的日益增多,延遲成為整體 AI 服務效能的重要方面。GPU在延遲和傳輸率之間存在顯著的權衡,與此不同的是,xDNNv3 DNN 引擎可以提供低延遲和高傳輸率。此外,xDNNv3內核提供簡單的Batch = 1介面,無需任何排隊軟體來自動批量輸入資料便可達到最大傳輸率,從而降低了介面軟體的複雜性。
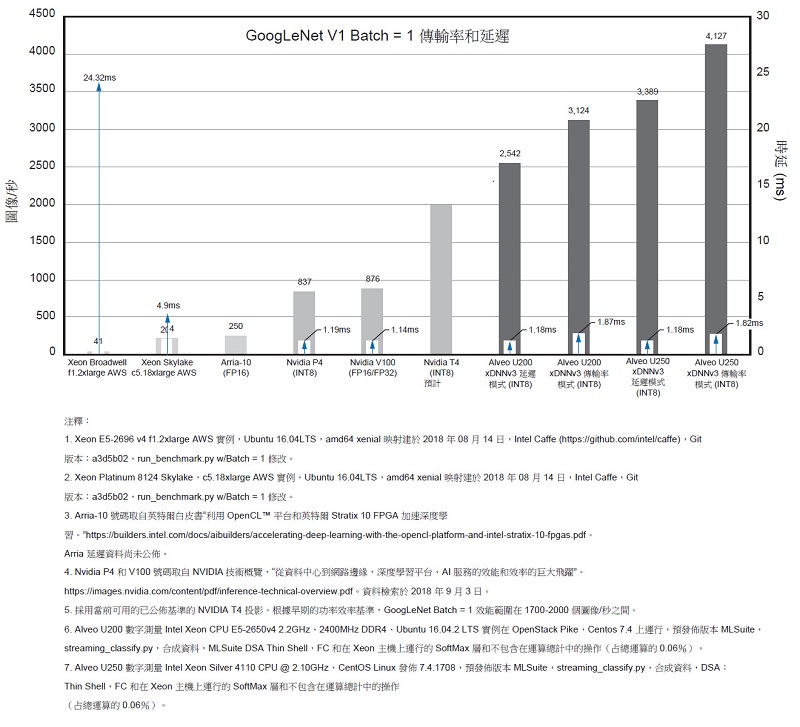
圖10和圖11顯示了Alveo 加速器卡,以及GPU和FPGA平台上的CNN、延遲和傳輸率基準。圖10顯示了沿左Y 軸以每秒圖像數量來測量的GoogLeNet V1 Batch = 1 傳輸率。傳輸率上方顯示的數位是以毫秒為單位的測量/ 報告延遲。
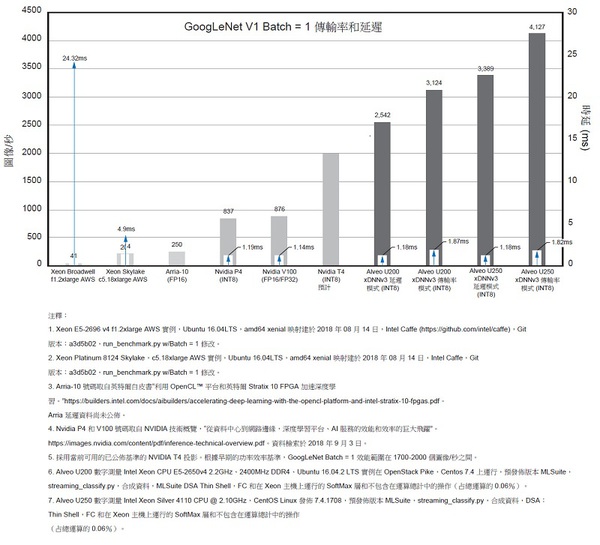
| 圖10 : GoogLeNet v1 Batch = 1 傳輸率 |
|
注釋:
1. Xeon E5-2696 v4 f1.2xlarge AWS 實例,Ubuntu 16.04LTS,amd64 xenial 映射建於 2018 年 08 月 14 日,Intel Caffe (https://github.com/intel/caffe),Git 版本:a3d5b02,run_benchmark.py w/Batch = 1 修改。
2. Xeon Platinum 8124 Skylake,c5.18xlarge AWS 實例,Ubuntu 16.04LTS,amd64 xenial 映射建於 2018 年 08 月 14 日,Intel Caffe,Git 版本:a3d5b02,run_benchmark.py w/Batch = 1 修改。
3. Arria-10 號碼取自英特爾白皮書“利用 OpenCL? 平台和英特爾 Stratix 10 FPGA 加速深度學習。”https://builders.intel.com/docs/aibuilders/accelerating-deep-learning-with-the-opencl-platform-and-intel-stratix-10-fpgas.pdf。
Arria 延遲資料尚未公佈。
4. Nvidia P4 和 V100 號碼取自 NVIDIA技術概覽,“從資料中心到網路邊緣,深度學習平台、AI 服務的效能和效率的巨大飛躍”。https://images.nvidia.com/content/pdf/inference-technical-overview.pdf。資料檢索於 2018 年 9 月 3 日。
5. 採用當前可用的已公佈基準的 NVIDIA T4 投影。根據早期的功率效率基準,GoogLeNet Batch = 1 效能範圍在 1700-2000 個圖像/秒之間。
6. Alveo U200 數字測量 Intel Xeon CPU E5-2650v4 2.2GHz、2400MHz DDR4、Ubuntu 16.04.2 LTS 實例在 OpenStack Pike,Centos 7.4 上運行,預發佈版本 MLSuite,streaming_classify.py,合成資料,MLSuite DSA Thin Shell,FC 和在 Xeon 主機上運行的 SoftMax 層和不包含在運算總計中的操作(占總運算的 0.06%)。
7. Alveo U250 數字測量 Intel Xeon Silver 4110 CPU @ 2.10GHz,CentOS Linux 發佈4.1708,預發佈版本 MLSuite,streaming_classify.py,合成資料,DSA:Thin Shell,FC 和在 Xeon 主機上運行的 SoftMax 層和不包含在運算總計中的操作(占總運算的 0.06%)。
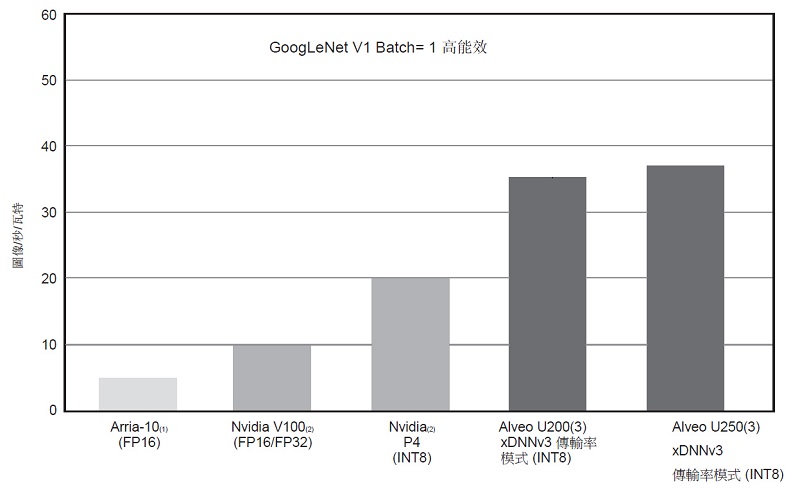
圖11顯示了沿 Y 軸以每秒每瓦特圖像數量來測量的 GoogLeNet V1 傳輸率。雖然GoogLeNet v1效能可用於基準測試,但xDNN支援廣泛的CNN 網路。
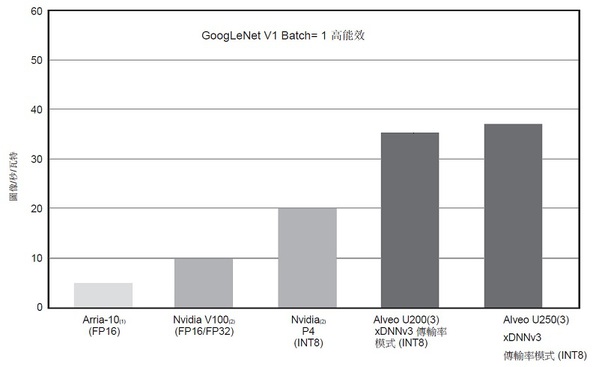
| 圖11 : GoogLeNet v1Batch= 1 能源效率 |
|
注釋:
1. Arria-10 號碼取自英特爾白皮書“利用 OpenCL? 平台和英特爾R StratixR 10 FPGA 加速深度學習。”https://builders.intel.com/docs/aibuilders/accelerating-deep-learning-with-the-opencl-platform-and-intel-stratix-10-fpgas.pdf。
2. Nvidia P4 和 V100 號碼取自 Nvidia 技術概覽,“從資料中心到網路邊緣,深度學習平台、AI 服務的效能和效率的巨大飛躍”。https://images.nvidia.com/content/pdf/inference-technical-overview.pdf。資料檢索於 2018 年 9 月 3 日。
3. 基準執行期間電路板管理固件報告的電路板功率資料。
結論與行動呼籲
如共用效能結果所示,xDNN處理引擎是一種低延遲、高能效的DNN加速器,在即時推論作業負載方面優於當今眾多常見的CPU/GPU平台。xDNN處理引擎可通過ML Suite在眾多雲端環境(例如 Amazon AWS/EC2 或 Nimbix NX5)中使用。其通過賽靈思的新Alveo加速器卡無縫擴展到本地部署。
賽靈思的可重配置 FPGA 晶片允許使用者通過 xDNN 更新繼續接收新的改進和功能,這使得使用者能夠跟上不斷變化的需求和不斷演進發展的網路。