前言
在上一篇文章中,我們介紹了一些關於直接記憶體存取(DMA)的基礎,例如其必要性、架構以及如何控制等。在本文中,我們將會集中在DMA移轉的分類上,以及關於分類在設定上的概念。
設定DMA
DMA移轉設定有兩種主要的類型:暫存器模式(Register Mode)以及描述符模式(Descriptor Mode)。而不論是何種類型的DMA,(表一)中所描述的相同類型資訊,都會進入到DMA控制器中。當DMA以暫存器模式運作時,DMA控制器只會使用存在於暫存器中的數值。而當DMA以描述符模式運作時,DMA控制器則會在記憶體中搜尋其設定用數值。
(表一) DMA暫存器
Next Descriptor Pointer (lower 16 bits) |
Address of next descriptor |
Next Descriptor Pointer (uper 16 bits) |
Address of next descriptor |
Start Address (lower 16 bits) |
Start address (source or destination) |
Start Address (uper 16 bits) |
Start address (source or destination) |
DMA Configuration |
Control information (enable, interrupts, 1D vs. 2D) |
X_Count |
Number of transfers of inner loop |
X_Modify |
Number of bytes between each transfer in inner loop |
Y_Count |
Number of transfers in outer loop |
Y_Modify |
Number of bytes between end of inner loop and start of outer loop |
以暫存器為基礎的DMA
在以暫存器為基礎的DMA中,處理器會對DMA控制暫存器直接進行編程,以便啟始移轉作業。以暫存器為基礎的DMA,具有最佳的DMA控制器性能,這是因為暫存器不需要從記憶體中的描述符持續地重新讀取資料,此外核心也不需要去對描述符進行維護。
以暫存器為基礎的DMA包含有兩個次模式(sub-mode):自動緩衝模式(Auto-buffer Mode)以及停止模式(Stop Mode)。在自動緩衝DMA中,當一個移轉區塊完成時,控制暫存器就會自動的重新讀取其原始設定數值,然後相同的DMA程序就會重新開始,而不會有任何多餘的開支。
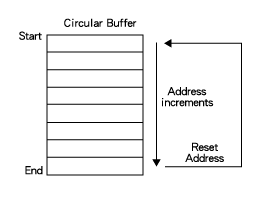
如(圖一)所示,假如我們設定了一組自動緩衝DMA,要將某些數量的字元,從周邊移轉至L1資料記憶體中的緩衝區內,DMA控制器會在前一個字元的移轉完成時,立即重新讀取初始參數。這將會形成循環緩衝(circular buffer),因為當數值被寫入緩衝區內的最後一個位置之後,下一組數值就會被寫入緩衝區內的第一個位置。
對於性能相當敏感,具有連續資料串流的應用來說,自動緩衝DMA特別適合。DMA控制器能夠獨立讀取串流資料,不會受到處理器動作的影響,並且當每個移轉完成之後,可對核心發出中斷要求。雖然想要很平順的將自動緩衝模式停止下來是可能的,但假如一組DMA程序必須要經常性的啟動與停止,那麼使用這種模式就不恰當。
以下我們來看一個自動緩衝的範例。
自動緩衝的範例:雙重緩衝
假設有個應用裝置,其處理器是以每次512筆音訊取樣的方式運作,而其編解碼器(音訊類比 / 數位轉換器)則是以音訊的時脈速率來傳送新的資料。在這樣的一個架構中,自動緩衝DMA可以算是最佳選擇,這是因為資料的移轉會在週期性的間隔內發生。
雙重緩衝
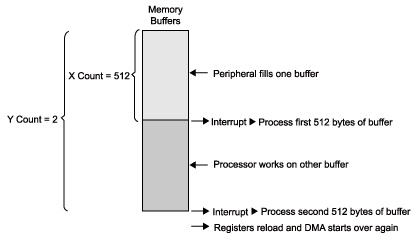
以此相同的模型來作為基礎,假設我們想要將所接收到的音訊資料進行雙重緩衝(double - buffer)處理。也就是說,我們希望當一組緩衝區正在運作時,DMA控制器可以將另一組緩衝區填滿。處理器必須在DMA控制器將特定資料緩衝區的啟始部分包圍起來之前,先在該緩衝區上將工作完成,如(圖二)中所示。使用自動緩衝模式的話,設定就會很簡單。
緩衝組計算方式
自動緩衝DMA的總數量,必須要透過一組2D DMA,來將兩組資料緩衝區的大小包含在內。在這個範例中,每個資料緩衝區的大小與2D DMA中內部迴路的大小相當。緩衝區的數量則與外部迴路相當。因此,我們將維持 XCOUNT = 512。假設音訊資料元素的大小是4 位元組,我們將字元移轉大小編程為32位元,並且設定XMODIFY = 4。由於我們需要兩組緩衝區,因此我們設定YCOUNT = 2。假如我們希望這兩組緩衝區在記憶體中是back-to-back的話,那麼我們必須設定YMODIFY = 1。然而,將緩衝區個別分開,通常會是比較明智的作法。此種方式可以讓你避免掉當處理器與DMA控制器在對相同的記憶體副插槽(subbank)進行存取時,兩者之間所產生的衝突。要達成這樣的結果,可以將YMODIFY提高,以便在緩衝區之間提供適當的區隔。
在2D DMA移轉中,當XCOUNT抑或是YCOUNT到期時,我們還有產生中斷的選項可供選擇。將其轉移到這個範例中時,那就是我們可以設定每當XCOUNT降為0、亦即每組512移轉結束時,DMA中斷就會被觸發。若我們將其想像成當每個內部迴路終止時、所接收到的中斷,就能比較容易理解。
停止模式的運作方式
停止模式的運作方式與自動緩衝DMA大致相同,除了在DMA完成之後,暫存器不會重新讀取,因此整個DMA移轉只會運行一次而已。對於會針對某些特定事件而觸發一次性的移轉而言,舉例來說,以非週期性的方式將資料區塊從一個位置搬移至另一個位置,停止模式是最為有用的方法。當需要讓事件同步時,這個模式也相當的有用。舉例來說,假如有一項作業必須要在下一個移轉啟始之前完成,使用停止模式可以確保這個流程的正確性。此外,停止模式對於緩衝區的初始化也是相當有用。
描述符模式
以描述符為基礎的DMA移轉,需要一組儲存在記憶體中的參數,以便啟動DMA序列。描述符中所包含的,是所有通常會被編程並寫入DMA控制暫存器組的相同參數。然而,描述符也允許多重的DMA序列相互鏈結在一起。在以描述符為基礎的DMA運作下,我們可以將DMA通道予以編程,以便自動進行設定,並且在現有的序列完成之後啟動另一組DMA移轉作業。在對系統的DMA移轉做管理時,以描述符為基礎的模型能夠提供最大的彈性。
描述符模型:以ADI為例
在ADI的Blackfin處理器中有兩種主要的描述符模型 ,一種是「描述符陣列」,一種是「描述符清單」。具有這兩種模型的目的,是為了可以在彈性與性能之間取得平衡。
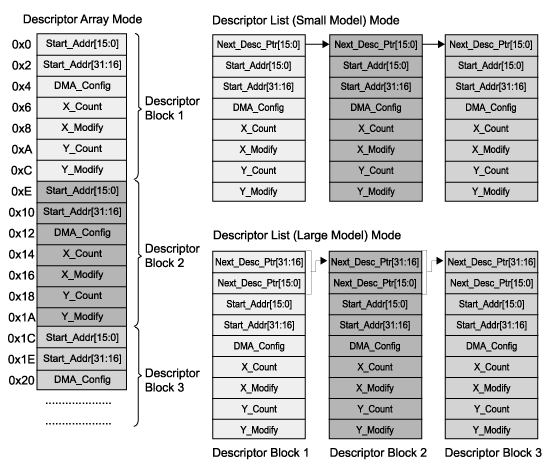
在描述符陣列模式中,描述符會常駐在連續記憶體之中。DMA控制器仍然會從記憶體內讀取描述符,但是因為下一個描述符,會緊接著現有的描述符,因此兩個用來記錄尋找下一個描述符、以及它們所對應的描述符讀取字元,也就不再重要。由於描述符並不包含此一「下一描述符指標」(Next Descriptor Pointer)資料,DMA控制器就會認為記憶體中的這些描述符群組,會如同陣列一般地一個接著一個排下去。
使用描述清單
當個別的描述符,在記憶體中不是以back-to back的方式配置時,就可以使用描述符清單的方法。事實上有許多種類的次模式可供使用,以便在性能與彈性之間取得平衡。在「小型描述符」(small descriptor)的模型中,描述符包含一組單一的16位元場域,該場域是用來作為「下一描述符指標」場域較低部分的設定所用;較高部分則會透過暫存器個別加以編程,並且不會改變。當然,這將會使描述符被限制在記憶體內的特定 64K ( =216 )分頁(page)內。當描述符的位置超出這個界限之外時,就要使用能夠提供32位元作為「下一描述指標」資料的「大型」模型。
描述符讀取
不論採用何種描述符模式,使用越多的描述符數值,都會需要越多的描述符讀取。這就是為何Blackfin處理器要指定一組「彈性描述符模型」(flex descriptor mode)。該模型可以適當調整描述符的長度,使其只包含只有針對特定移轉所需的資料,如(圖三)所示。舉例來說,假如 2D DMA沒有需要的話,YMODIFY以及YCOUNT暫存器就沒有必要成為描述符區塊中的一部份。
描述符的管理
要回答管理描述符清單的最佳方法,此一答案必須視應用領域而定,不過最重要的是要瞭解有什麼樣的選擇可用。
鏈結
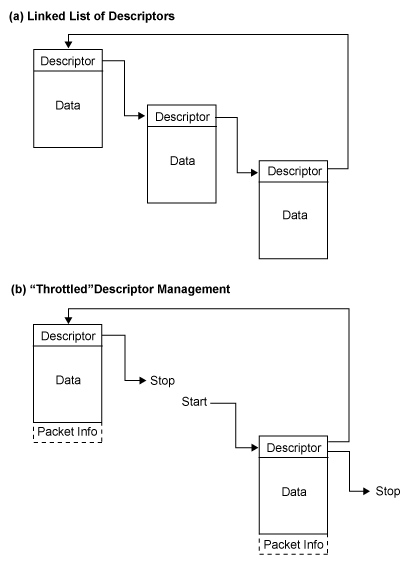
首先我們將要討論的選項,其運作模式與自動緩衝DMA非常相似。在這個選項中,必須要對鏈結在一起的多重描述符進行設定,如(圖四a)中所示。
「鏈結」(chained)意指前一個描述符會指向下一個描述符,同時也會自動讀取。想要完成這個鏈結,最後的描述符指標,必須指回到第一個描述符,重複運作處理程式。使用這項技術而不利用自動緩衝模式的原因之一,就是在移轉的大小與方向上,使用描述符會具有較多的彈性。
致能
其次我們討論的選項,則是以處理器手動管理描述符清單。描述符實際上是屬於記憶體內的架構。每個描述符包含有一個設定字元,而每個設定字元則包含有一組「致能」(Enable)位元;當一組移轉啟動時,此位元可作為調整之用。現在我們假設有4組緩衝區、必須要在某些特定的作業區間內搬移資料,假如我們所需要的是,當處理器準備妥當時,就讓處理器分別啟動每個移轉作業,那麼我們可以預先設定好所有的描述符,不過其中的「致能」位元必須予以清除。當處理器判定啟動描述符的時間已到時,它將只會更新記憶體中的描述符,然後寫入DMA暫存器中,以便啟動各自分隔開的DMA通道。(圖四b)所示為這套流程的範例。
串流同步化實例操作
這種類型的移轉何時才會派上用場?試想有個多媒體應用裝置需要將輸入串流與輸出串流同步化。舉例來說,即使工程師嘗試要將這些串流調整成相同的時脈速率,視訊取樣接收至記憶體的速率、與所播放的輸出視訊速率之間,可能是不相同的。在同步化是個問題的大前提下,處理器可以針對與輸出緩衝區相關連的DMA描述符,進行手動調節。在下一組描述符被「致能」之前,處理器可以透過確保一次只有一個實體(entity)在對共用資源做存取的信號機制(semaphore mechanism),來調整現有的輸出描述符,以便將串流同步化。
在處理器之間使用內部的DMA描述符鏈結、或是以DMA為基礎的串流時,如果在所傳送資料區塊的末尾加上一個額外的字元 ,其中包含如何處理資料、同時可能包含時間戳記(time stamp),也是相當有用,該字元對於判定封包是否已被傳送出去,則有所幫助。(圖4b)中以虛線所標示的區域,就是這種架構的範例。
軟體為核心的DMA功能
在最複雜的應用領域中,會具有以軟體做成的DMA管理員功能。這項功能可能會成為作業系統或即時核心的一部份,但是它也可以不需要依賴這些而自行運作。在Blackfin處理器中,這項功能是以VisualDSP++工具套件中系統服務的一部份為基礎。這項管理功能讓工程師能夠透過標準的應用程式介面(API)來搬移資料,而不需去對每個控制暫存器進行手動設定。
基本上,應用會提交DMA描述符的請求給DMA佇列管理員,而其職責就是處理每個請求。這些請求會依據被應用軟體所接收到的順序而加以處理。通常,一個指向「回覆」(call - back)功能的位址指標(address pointer),也會是系統的一部份。當一組資料緩衝區已經就緒時,這項功能會完成你希望處理器所要執行的作業,而無需讓核心滯留在高優先權的中斷服務常式內。總而言之,由於DMA管理員抽象化資料移轉過程,因而能簡化編程模型。
管理描述符佇列
想要使用中斷來管理描述符佇列,通常有兩種方法。第一種是以每組描述符完成時的中斷為基礎,只有當工程師可以確定每個中斷事件都能個別地被處理,不會有中斷溢出(overrun)時,才能使用這種方法。第二種方法所牽涉到的中斷,是只有當一組工作區塊(work block)的最後一個描述符所指定的移轉作業完成時,才會產生。一組工作區塊乃是一或數個描述符的集合。
想要保持描述符佇列的同步化,非中斷軟體必須要維持計數加入到佇列中的描述符,而中斷常式則會維持計數從佇列中移出之已完成的描述符。只有當DMA通道在已處理完所有的描述符之後而暫停下來時,其數量才會相等。
小結
在這篇文章中,我們主要討論是以暫存器和描述符為基礎的DMA資料流結構,以及何時該使用哪種類型。下一次我們將會討論一些能夠在多媒體系統中,提供協助並使得資料搬移更為有效率的先進DMA特點。(本文由ADI美商亞德諾提供)