晶片设计平台即服务(Silicon Platform as a Service,SiPaaS)供应商芯原公司推出一款电脑视觉和人工智慧应用的高度可扩展和可程式设计的处理器VIP8000。它每秒可提供超过3 Tera MAC,功耗效率高于1.5 GMAC /秒/毫瓦,为最小面积的采用16FF制程技术的处理器。
 |
| 突破性的IP为嵌入式装置提供即时1080p场景分类、物件侦测和像素分割。 (Graphic: Business Wire) |
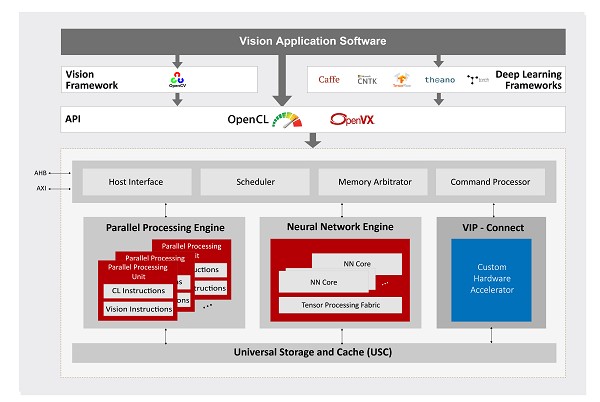
Vivante VIP8000由高度多执行绪的平行处理单元、神经网路单元和通用储存快取单元组成。 VIP8000可以直接汇入由Caffe和TensorFlow等主流深度学习架构生成的神经网路,并可利用OpenVX架构将神经网路整合到其他电脑视觉功能模组中。它支援当前所有的主流神经网路模型(包括AlexNet、GoogleNet、ResNet、VGG、Faster-RCNN、Yolo、SSD、FCN和SegNet)和层类型(包括卷积和去卷积、扩张、FC、池化和去池化、各种规范化层和启动函数、张量重塑、逐元素运算、RNN和LSTM功能),旨在促进新型神经网路和新型层的采用。神经网路单元支援定点8位元精度和浮点16位精度,并支援混合模式应用,以达到最佳计算效率和准确率。
Vivante VIP8000的VIP-Connect介面支援客户快速整合专用硬体加速单元,使其与标准的Vivante VIP8000硬体单元实现协同运作。
该处理器由OpenCL或OpenVX进行程式设计,并在含客户专用硬体加速单元在内的硬体单元中采用统一的程式设计模型。所有硬体单元同时工作,共用快取资料,可显著减少频宽。
为了加强因应不同市场区块的嵌入式产品,Vivante VIP8000可以灵活配置,其平行处理单元、神经网路单元和通用储存单元分别具有可升级性,且ACUITY SDK可提供培训和全套IDE工具。
芯原执行副总裁兼首席战略官戴伟进表示:「神经网路技术正在快速成长和演进,Vivante VIP8000的用例范围拓展到最初的的监视器和汽车电子客户群之外。Vivante VIP8000以其优越的PPA (性能、功耗、面积),透过正在申请专利的通用快取架构来降低频宽的创新之举,以及压缩演算法,加快了将嵌入式装置作为AI终端且与云端协作,为终端使用者提供革命性AI体验的行动。」
JonPeddie Research总裁Jon Peddie表示:「为了在嵌入式装置中实现AI的快速成长,支援OpenCL和OpenVX等业界标准API的高效且功能强大的可程式设计引擎可谓至关重要。神经网路创新和增加计算密度将共同提升效率。」