本文分享沒有AI背景的工程師,在使用NanoEdge AI Studio快速訓練風扇異常偵測的模型的方法。
此模型是依馬達控制板的電流訊號,偵測風扇濾網的堵塞百分比。當風扇堵塞時,馬達的電流訊號波型與一般情況不同,但傳統演算法很難偵測到差異。因此,機器學習演算法便成為解決此問題的絕佳選擇。在訓練模型時,通常會使用scikit-learn函式庫,因此,本文將闡述自行訓練機器學習模型及使用 STM32Cube.AI 部署到相同裝置上的方式,以便使用者比較兩者之間的差異。
NanoEdge AI Studio為端對端工具,可預先處理部分資料,再進行訓練與媒合演算法;而STM32Cube.AI則會需要工程師具備完整的AI模型開發經驗。
硬體與軟體前置準備
P-NUCLEO-IHM03馬達控制套件用於驅動風扇,是由NUCLEO-G431RB主機板、馬達控制擴充板與無刷馬達所組成。
在進行軟體前置準備時,需先設定Anaconda環境,並安裝scikit-learn、pandas和ONNX等必要函式庫。
然後,再依建立AI專案的關鍵步驟,逐步建立以STM32Cube.AI為基礎的專案。
首先,使用者需要收集建立機器學習模型所需的資料。在此資料集當中(訓練資料集),部分將用於模型訓練,典型比例為80%,而另一部分(測試資料集)用於日後評估所建模型的效能,典型比例為20%。
第二步,使用者需要「標記」資料。因為決策樹模型是以模型建立者所標記的分類為基礎,因此,機器需要知道所收集到之資料的類別,例如「跑步」、「行走」、「靜止」等。
分類是指使用者依照其認為重要的屬性將資料分組,也就是機器學習領域中的「類別(class)」。
接下來,使用者要利用已準備好的資料集訓練機器學習模型,也就是「擬合(fitting)」。此步驟的結果準確度有極大程度取決於資料之內容與數量。
第四步,使用者要將訓練完畢的機器學習模型內嵌至系統。若是電腦執行的機器學習,使用者可使用Python函式庫直接執行模型;若機器學習位於MCU等裝置上,則可在實作前將此函式庫轉換成C語言程式碼;若為MEMS MLC等硬體配線方案,實作前可使用UNICO-GUI專用軟體,將函式庫先轉換為暫存器設定。
最後一步為驗證機器學習模型,如果驗證結果不符預期,使用者必須確認並改善上述步驟。
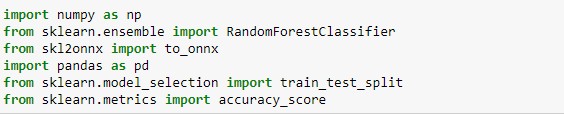
首先,先匯入需要的函式庫
為了方便比較,這邊使用上一次NanoEdge AI Studio訓練模型中所使用的資料集。本文作者使用pandas,並從csv檔讀取資料,並將其用於訓練模型。
在開始訓練模型前可以先輸出(print)資料集的形狀以瞭解內容。
此資料集是由119筆資料所組成,共有128種特徵,且最後一個資料欄為資料標籤。
接著,我們將資料集分為訓練集及測試集,訓練集用以訓練模型,佔資料集的80%,而測試集是用以檢查模型一般化能力,比重為20%。
資料集備妥即可開始訓練模型。
訓練結束後可在測試集上驗證該模型的效能。可以看到,模型在測試集上可達到約83%的準確率。
最後,儲存訓練後的模型會取得名為random_forest.onnx 的ONNX格式檔案。
以下為使用Netron模型可視化工具檢視的模型架構:
經過STM32Cube的整合,STM32Cube.AI 使用者能有效率地將模型移轉至多樣化的STM32微控制器系列中,而且類似模型也同樣適用於不同產品,能夠在STM32產品組合中輕鬆移轉。
此外掛程式可擴充STM32CubeMX的功能,自動轉換預先訓練的人工智慧演算法,並將其產生的最佳化資料庫整合至使用者專案當中,不需手動撰寫程式碼,並且能將深度學習解決方案嵌入各種STM32微控制器產品組合中,賦予產品智慧功能。
STM32Cube.AI提供各種深度學習框架的原生支援,例如Keras、TensorFlow Lite、ConvNetJs,也支援像是PyTorch、Microsoft Cognitive Toolkit、MATLAB等,所有可匯出為ONNX標準格式的框架。
此外,STM32Cube.AI還支援來自大量ML開放原始碼函式庫scikit-Learn的標準機器學習演算法,例如Isolation Forest、支援向量機器(Support Vector Machine,SVM)、k-means。
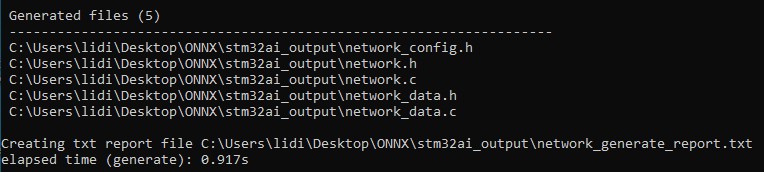
現在已經準備好將模型部署至MCU了。本篇採STM32Cube.AI的CLI模式,可使用以下指令將模型轉換成最佳化C語言程式碼:
Stm32ai generate –m random forest.onnx
若轉換成功,以下訊息將會出現。
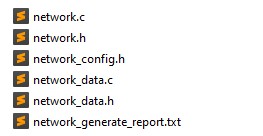
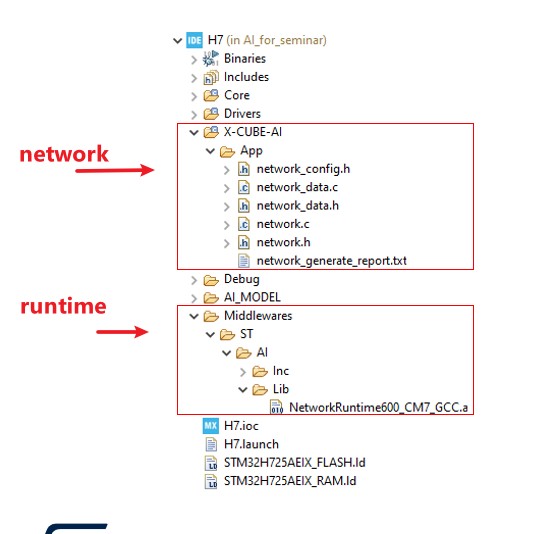
在資料夾stm32ai_output中,可以看到下方產生出來的檔案。其中,network.c/.h保留模型拓撲的資訊,而network_data.c/.h則會記錄模型權重的資訊。
此時,產生的模型也已經可以整合至STM32專案中。當使用CLI模式時,STM32Cube.AI的執行階段需要手動新增至專案中,以利呼叫network.h中的函式執行模型。
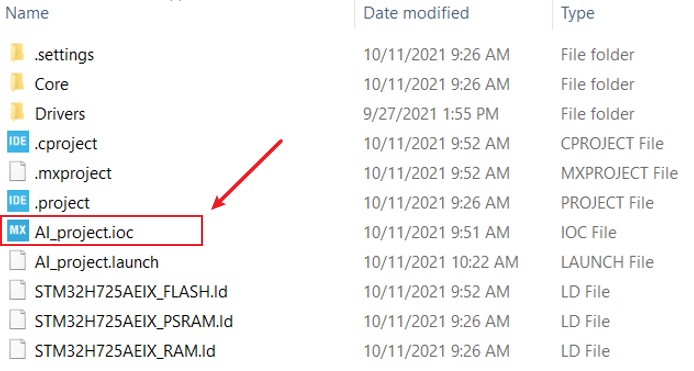
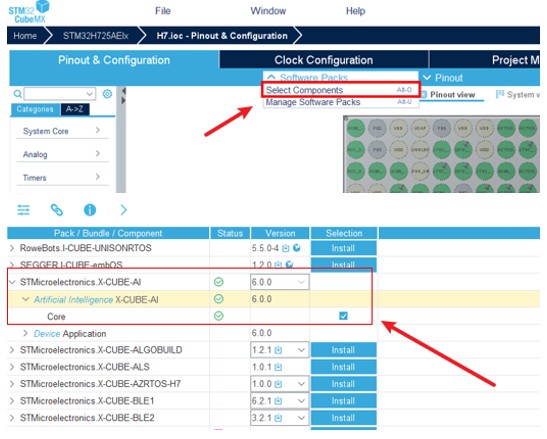
STM32Cube.AI也有更輕鬆整合AI模型的方式,若專案是以ioc檔案著手,便可將AI模型新增至CubeMX程式碼產生階段,一同產生程式碼。
如下圖所示,啟用CubeMX的AI功能。
將AI模型整合至專案當中。
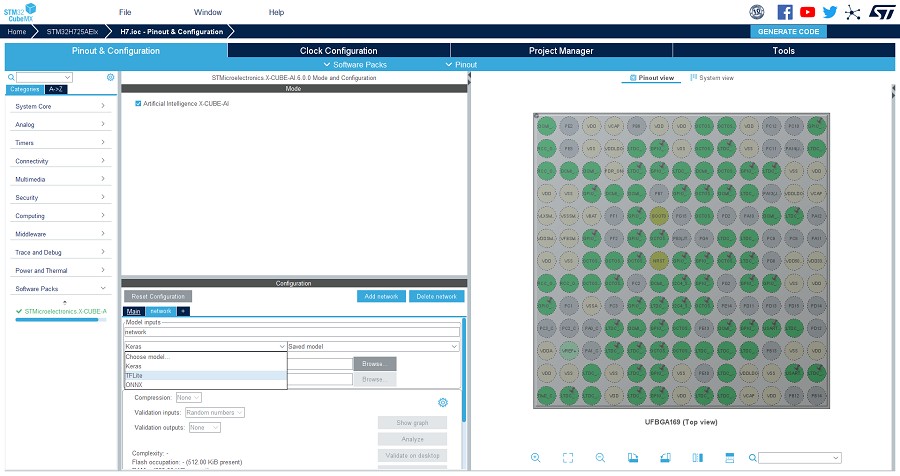
如此一來,在產生程式碼時,AI模型會轉譯成最佳化C語言程式碼,而且STM32Cube.AI執行階段的對應版本也會一併整合至專案中。
藉由這樣的方式,模型可整合至專案,且不會產生任何差錯。從以上兩種方法可以發現兩者差異在於NanoEdge AI Studio較簡易,且更有效率,而STM32Cube.AI則較為靈活、可自訂空間較大。