神經網路幾乎成了人工智慧的代名詞,正在被應用於各種領域,包括影像識別、語音辨識、自然語言處理、自動駕駛、訊號分析、大數據分析和遊戲。
這是一個瞬息萬變的世界,每年都有新的神經網路模型被更新,大量的開放原始碼到處流傳,專用人工智慧晶片開發企業更是如雨後春筍般湧現。
因此全球研究人員正透過模仿人類大腦組織方式,積極開發類神經網路技術,雖然一直有突破性的進展,但是現階段的神經網路,還是缺乏即時變化的靈活性,以及難以快速適應陌生的狀況,使得神經網路技術普及實用化的進程還是相當遙遠。
根據不同應用開發出的神經網路模型
神經網路是模仿人類神經細胞網路的模型,由輸入層、中間層(隱藏層)和輸出層的神經元,以及連接它們的突觸組成。而機器學習就是在大量資料的基礎上,自動構建連接和它們的權重。
深度學習是指,使用具有多個中間層的神經網路的機器學習。深度學習使電腦能夠提取自己的特徵量,作為發現模式和規則時應該注意些什麼,同時也能進行識別和其他作業,因此促進了人工智慧熱潮。
模型根據應用的不同,又分為影像識別的深度神經網路(DNN)、卷積神經網路(CNN)、語音辨識的迴圈神經網路(RNN)和自然語言處理的Transformer。模型可以在不同的應用中進行整合,也可為每個應用開發出新模型。
深度神經網路(DNN)
DNN的隱藏層由一個卷積層和一個池化層組成。卷積層利用過濾上一層附近的節點,而可得到一個特徵圖。池化層進一步縮小卷積層輸出的特徵圖,得到新的特徵圖,同時可在保持影像特性的同時,可以極大地壓縮影像中的資訊量。例如,在2012年ILSVRC影像識別比賽中,以壓倒性的優勢獲勝,採用八層結構的AlexNet就引發了深度學習的熱潮,隨後經過改進而來的ResNet,其層數就達到了152層。因此,透過導入簡化處理塊的Residual模組,即使是在高層數的結構下,也能達到高效學習。
迴圈神經網路(RNN)
具有自我回饋的遞迴網路RNN,是一個適合處理包括語音波形、視訊和文字檔(字串)等等時間序列資料的神經網路。例如神經網絡中為了處理如語音等,可變長時間序列數據,將隱藏層的值再次回饋輸入到隱藏層。當存取很久以前的數據,或出現運算量爆炸等問題時,可透過應用於自然語言處理的LSTM(長短時記憶)來解決。
Transformer
在自然語言處理方面,既不是透過RNN,也不是CNN,而是據由深度學習的Transformer取得了重大進展:這是一個只使用Attention(表示要注意句子中哪些單詞的分數)的Encoder-Decoder模型,也可透過並行化來減少學習時間。在後續的技術改進下也相繼開發出的BERT、GPT-2、T5等,甚至已超過了人類的語言處理能力。
而Conformer是一個結合CNN的模型,可被應用於語音辨識,其能力已經超過RNN的最高準確性。Conformer結合了善於提取長時空依賴關係的Transformer,和善於提取局部關係的CNN。此外,一個新的影像識別模型-Vision Transformer也被開發出來,在進行影像識別時,所需要的運算資源比CNN少更少。
大型數據處理業者相爭投入開發AI晶片
神經網路中的訊號處理,相當於將神經元乘以權重的數值加在一起,再透過高速運算乘積之和的操作來模仿大腦行為(高速積和加速器)。最近的主流配置是盡可能多鋪設必要數量的圖磚(Tile)來進行AI運算,例如,一個圖磚被用於終端感測器控制,4-16個圖磚用於中等規模的邊緣處理,64個或更多圖磚用於資料中心等伺服器。
人工智慧晶片的功能大致可分為推理和學習。兩者都需要相同的高速乘積運算,但與推理相比,學習需要進行大量的乘積和運算,因此各大數據處理業者正積極投入這方面的研發,例如,Google目前正積極開發TPU來作為本身資料中心的AI晶片。第一代(2017年)有8位元定點操作,只能用於推理,但第二代有16位浮點運算,則可以應用在學習。接下來第三代的性能則是120Tops @ 250W,最新的第四代載板設計了4顆TPU,且採用液體冷卻,運算速度更是上一代的2.7倍。這些電路板被安裝在一個個機櫃內,然後通過高速傳輸線相互連接。
用於推理的人工智慧晶片要求體積小、功耗低和即時處理。例如,Gyrfalco銷售一種形狀像USB隨身碟的AI棒。採用的AI晶片是一款具有矩陣處理引擎,利用PIM(記憶體中處理器)技術來進行神經網路模型的計算處理,這個架構可降低與記憶體和計算電路之間的資料存取的功耗,晶片內部有大約28000個節點和10M bytes的記憶體,據稱能夠將通用模型所需的所有性能都能整合到晶片中。
NTT與東大合作開發新型類腦學習算法
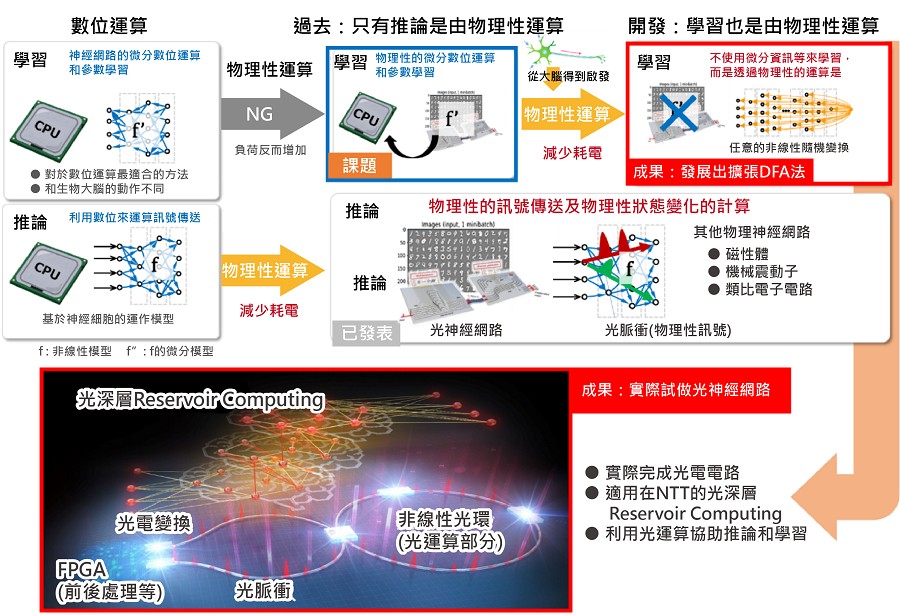
對於深度神經網絡的運算,日本NTT與東京大學合作下,開發了一種不需要準確掌握物理系統資訊,適用於物理神經網絡的新演算法-「擴展DFA(Detrended Fluctuation Analysis)」。
圖一A是這種演算法的概況和結果的定位,這是基於深入研究了一種名為直接回饋排列法的學習演算法,是將反向傳播演算法(Back Propagation;BP)修改為在大腦資訊處理更容易實現的形式,並將其擴展到可在物理神經網絡中實現。
這個方法是將神經網絡最後一層的輸出與所需輸出訊號(誤差訊號)之間的差值,透過隨機元素的矩陣的線性變換來更新學習參數。運算過程不需要測量物理系統的狀態,也不需要像BP法需要利用微分回應的物理類比進行近似運算。
此外,這個運算可以在包括光路等物理系統上執行,除了可以在物理系統上有效地運算推理,還可以進行學習。這種新的學習方法不僅適用於物理實現中實現的神經網絡模型,也適用於各種機器學習模型,包括實際用於機器翻譯和其他應用的高級深度神經網絡模型。
因此NTT與東京大學構建了一個光學神經網絡(圖一 B),證明了以前難以進行的光學神經網絡學習,可以利用光學計算輔助推理和學習運算的可行性。這一成果將解決人工智慧的計算時,功耗和計算時間增加的問題。
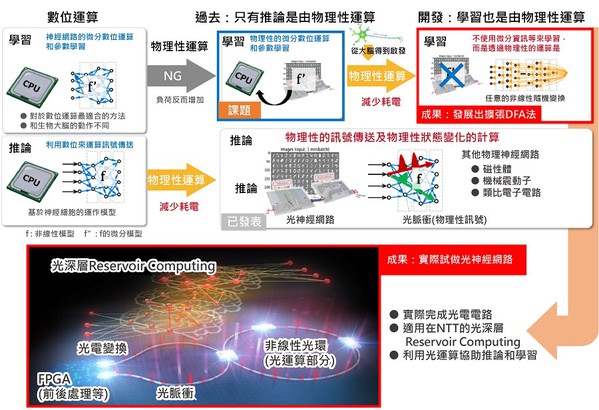
| 圖一 : 物理系統的計算被納入學習部分來提高效率;以及實際設備應用的光學神經網絡。(source:日本NTT;作者整理) |
|
適用於物理神經網絡的擴展DFA法
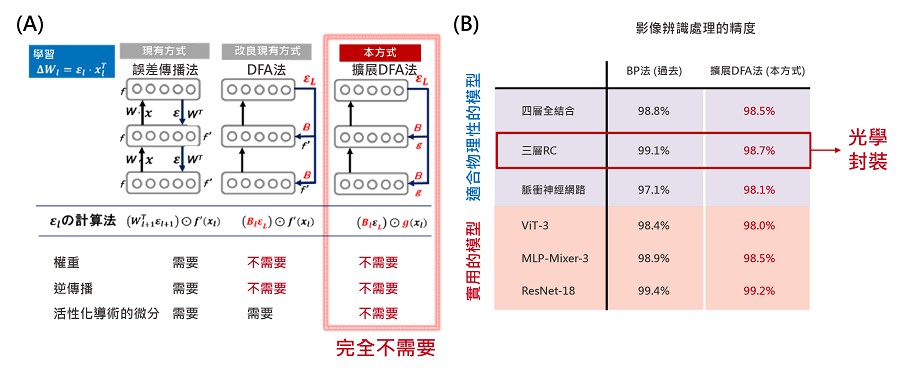
DFA法是受到大腦資訊處理的啟發,因而進一步擴展為適合在物理神經網絡中實現的形式。如圖二A所示,傳統的DFA法是透過隨機矩陣對最後一層的誤差,進行線性變換來訓練深度神經網絡學習;儘管比BP法更適用於物理神經網絡,但仍然需要計算物理神經網絡時,使用的非線性變換及其導數。
而NTT與東大擴展了DFA法技術,使這部分可以由一個任意的非線性函數代替。這完全省去了對物理系統的狀態測量、基於微分響應的物理類比的近似值,以及基於這些近似值的順序反向傳播演算。學習過程已被大幅度簡化,實現了用物理神經網絡幾乎不可能的學習。此外在對各種深度學習模型的適用性應用於各種深度學習模型時,也可以適用於廣泛的深度神經網絡模型,包括從實際用於影像識別,和其他應用的高級模型(圖二B)。
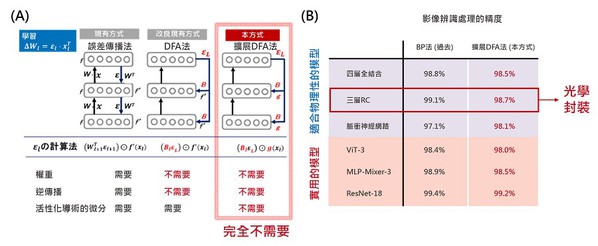
| 圖二 : A現有和新開發的學習方法概述;B各種模型的基準測試結果。(source:日本NTT;作者整理) |
|
圖三A是使用構建系統對影像處理基準任務性能的比較結果,光學神經網絡可達到最高性能。圖三B則是顯示了每單位影像的學習時間對神經元數量的依賴性。在小規模網絡模型的情況下,速率決定了資訊傳輸到光學硬體的處理時間,因此效果不如光學計算的計算加速效果大。
但是隨著神經元數量的增加,可以發現光學神經網絡計算在運算速度上比傳統的數位電子計算更有優勢。此外,由於人工智慧運算的功耗,是由效率和計算時間的積和所決定的,因此加速計算有助於降低功耗。
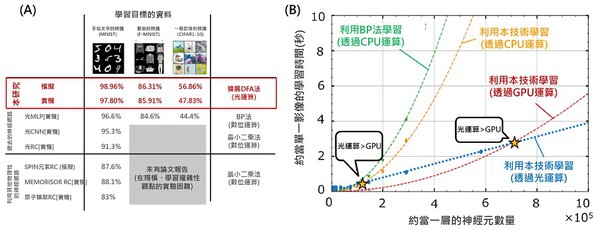
| 圖三 : A使用光學神經網絡進行影像辨識測試(手寫字符辨識、衣服影像辨識;B 每單位影像的運算時間對神經元數量的依賴性。(source:日本NTT;作者整理) |
|
靈感來自於線蟲的液體神經網路技術
2020年,由麻省理工學院Ramin Hasani和Matthias Lechner所領導的一個研究小組,推出了一種液體神經網路(Liquid Neural Network)的新形態神經網路,其靈感來自微小的線蟲。這項技術是以模仿具有細長的線狀身體的「線性動物」為參考基礎,來開發出神經網絡技術,達到前所未有的速度和靈活性,來實現「質」的跨越性進步,足以在某些應用中取代傳統網路。
據加州大學伯克利分校的機器人工程師Ken Goldberg表示,根據實驗結果顯示,比起需要透過隨時間變化,來進行建立模型的「連續時間神經網路」,這款「液體神經網路技術」,要來得更快、更準確(圖四)。

| 圖四 : 麻省理工學院Ramin Hasani和Matthias Lechner開發出新形態的液體神經網路。(source:麻省理工學院Ramin Hasani博士) |
|
Hasani和Lechner在思考如何能建立出一個夠靈活,且能快速適應新狀況的反應性神經網路時,發現線蟲是一個非理想可參考的生物體。線蟲是少數具有完全反射的神經系統的生物之一,可以透過一個大約1mm長的神經系統,來完成一系列複雜的行為,包括遷移、覓食、睡眠、交配,甚至從經驗中不斷的學習,而且在現實世界中,線蟲無論在任何環境或狀況下都具有相當優秀的適應能力。
液體神經網路技術與傳統的神經網路有很大的不同,傳統的神經網路只提供特定時刻的結果。而液體神經網路技術是一種非常特別的神經網路架構,可以將神經元都是聯繫在一起,並且透過彼此之間具有相互依賴的特性,來描述系統於任何特定時間下的狀態。
此外,在處理突觸的方式上也有所不同,突觸是人工神經元之間的連接。在標準的神經網路中,突觸連接的強度,可以用單一的數值來表示「權重(weight)」。而另一方面,在液體神經網路中,神經元之間的訊號交換是透過「非線性」函數控制的隨機過程,這意味著不會傳回與輸入成比例的響應(圖五)。

| 圖五 : MIT的研究人員基於蠕蟲的啟發,發現了一種更靈活的機器學習方法-液體神經網絡,可以即時轉換其底層算法,達到前所未有的速度和適應性。(source:Quanta Magazine) |
|
只需利用基本運算獲得精確的近似解
傳統的神經網路演算法是利用在訓練期間調整「權重」的最佳值,但在面對大量資料的環境下,液體神經網路的適應性會來得更強。因為液體神經網路可以根據觀察到的輸入改變基礎程式。例如在對自動駕駛汽車操作進行測試時,傳統的神經網路只能定期分析來自汽車攝影機的視覺資料,雖然液體神經網路僅由19個神經元和253個突觸所組成,按機器學習標準來說這個能力根本是非常薄弱,但事實上,該模型是允許對例如蜿蜒的道路等,複雜的道路進行更頻繁的採樣,因此液體神經網路能比傳統神經網路,表現出更高的反應能力。
不過,在突觸和神經元的非線性方程式,通常需要電腦多次運算才能得出解決方案。因此這也是液體神經網路的死穴,因為液體神經網路的突觸和神經元的軟體,由於是單獨進行計算,再加上所使用的突觸和神經元數量不多,因此運行速度非常慢。不過,這樣的困境也被克服了。
在2022年11月新發表的一篇論文中表示,研究團隊提出了一種新網絡架構,不必透過複雜困難的運算來解決非線性方程式。這個架構是只需要利用基本運算,就可以獲得近乎精確的近似解,大幅度的減少運算時間和能量,以及明顯地提高了處理速度。
目前這個小組正用一架無人機測試最新的液體神經網路,最初的測試是在森林中進行的,但希望將來能移到城市環境中,看看在面對新的環境條件時自我調適能力。
結語:過度投入將導致泡沫熱潮
神經運算是人工智慧熱潮的基礎技術,在許多業者和機構的投入下,從材料到設備、硬體、軟體到應用,都呈現迅速地發展的態勢。此外,還有全方位的開放架構,進入門檻相當低,尤其是從應用的角度來看,也有相當多的開發工具可使用。
以目前來看,但最大的障礙可能是收集所需要的大量學習數據,例如在某些領域,由於隱私和其他問題,資料收集是非常困難的。
另外,有些應用領域更是缺乏關於缺陷和故障的資料,如預測性故障和故障分析。由於神經運算是一個以歸納方式給出答案的系統,因此有些人會抱怨,這和訴諸理性的演繹法不同。
然而,無論如何神經運算已經開始啟動了,也呈現出非要達到目標的勢頭。為了解決上述問題,仍然需要技術的創新,可以說所有的技術領域都有商業機會。因此更要冷靜地分析形勢,不要被繁榮的景象所引誘,而又出現另一個泡沫熱潮。