智慧工廠、智慧城市、智慧家庭和行動裝置的出現,帶動網路終端裝置需要更智慧的系統架構和全新應用。人工智慧(AI)和機器學習(ML)半導體解決方案對新一代人工智慧應用程式的運算能力至關重要。
對打造邊緣運算解決方案的設計師來說,在這個競爭激烈的市場中出現了包含靈活、低功耗、小尺寸以及低成本等新需求,同時不能降低性能表現。在系統中整合接近物聯網(IoT)資料來源的低功耗推論能力與低能耗的低密度FPGA,才能在網路終端裝置的嚴苛要求下,同時保有快速推出產品的能力。
全新Lattice sensAI作為一套完整的開發生態系統,簡化了針對網路終端開發彈性推論解決方案的工作。通過各類IP、工具、參考設計和設計專長,開發人員可以善用產業體系讓創新解決方案快速上市。
架構轉變和網路終端日益增長的智慧需求
自第一台電腦發明以來,找到理想的系統架構一直都不是容易的工作。從電腦發展史中可以看出,系統架構始終在運算資源遠離使用者的集中式架構和處理資源靠近使用者的分散式架構之間反復搖擺。曾於20世紀70年代和80年代流行的伺服器架構方案採用高度集中的運算資源和儲存能力。但是這一理念很快在低成本個人電腦和互聯網快速發展的80和90年代衰落了。在這種新的架構模式下,運算任務不斷向個人電腦傾斜。
圍繞個人電腦構建的高度分散式方案似乎無懈可擊,直到以智慧型手機、平板電腦和筆記型電腦為代表的高流動性工具大行其道,四處攜帶運算硬體和儲存資源瞬間成為了一種負擔。系統架構隨之緩慢地將任務移到雲端,利用其近乎無限的運算和儲存資源、高可靠性以及低成本。
企業也使用雲端降低成本,同時更有效率地管理IT基礎設施的維護成本。隨著他們採用機器學習和更進階的人工智慧技術,雲端將成為整體核心。即將來臨的新一代智慧工廠、智慧城市和智慧家庭需要雲端來高效管理機器的視覺系統、協調交通以及降低能源使用。
但並非所有應用都將在雲端運行。產業專家指出,另一輪系統架構從集中轉變為分散的趨勢已開始出現。不論這樣的轉型是否會發生,有一點確信無疑:那就是低延遲、不斷加劇的隱私問題和通信頻寬限制將提升網路終端對智慧化的需求。隨著設計人員向網路終端應用加入更多智慧,他們需要能夠快速回應環境變化的系統。例如,當一輛無人駕駛車駛入智慧城市,它不可能詢問雲端如何避免車禍,而是必須立即且自主地做出判斷、反應。相同的道理,當AI安全攝影機在家中檢測到異動,它必須利用設備上的現有資源做出決定,如有人闖入則立刻報警。
這些新型應用需要靠近物聯網感應器的人工智慧/機器學習運算能力,而非雲端運算。這樣的需求有多大?有人認為潛力非常可觀。Gartner的分析師估計到2022年,高達50%的企業資料將在傳統集中式資料中心或雲端以外的地方處理(圖1)。
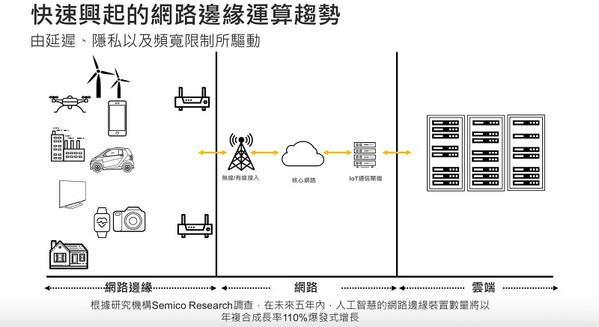
| 圖1 : 為避免受延遲、隱私和網路頻寬限制而快速興起的網路終端運算 |
|
網路終端運算的要求
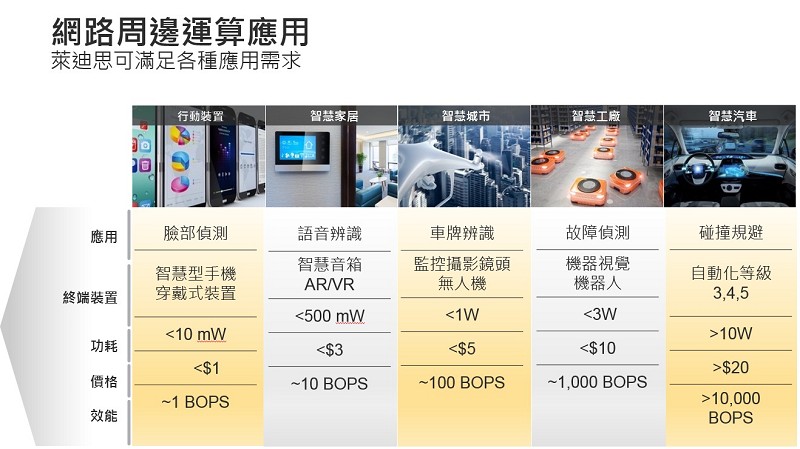
設計人員在開發網路終端運算解決方案時面臨最嚴峻的挑戰是要同時滿足高靈活性、低功耗、小尺寸和低成本等獨特要求(圖2)。
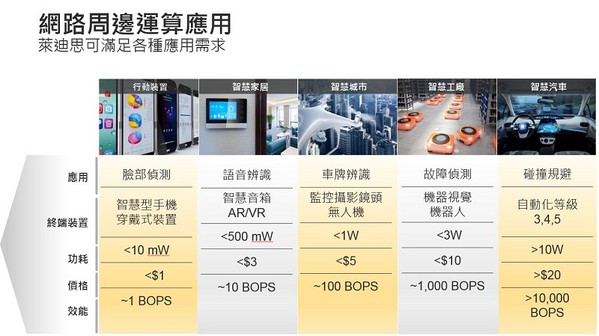
| 圖2 : 新一代基於AI 的網路終端運算應用需要滿足一系列獨特要求 |
|
開發人員如何構建功耗低、尺寸小、成本低而又不影響性能的網路終端解決方案呢?首先,他們需要可以提供最大設計彈性的半導體晶片。他們需要一個可以協助善用快速進化的神經網路架構與運算的晶片解決方案,同時這個晶片也要支援各種I/O介面。最後,他們還需要可以自訂量化的解決方案,讓他們可以犧牲精確度以節省電力。
考慮到網路終端設備的尺寸限制,設計人員需要適當的晶片來設計小巧、高性能的AI裝置,在輸出卓越性能的同時又能滿足尺寸或散熱的要求。成本也是一個關鍵要素。任何一種解決方案都必須能與其他大量生產的網路終端解決方案一較高下。最後,即便是在網路終端,快速上市的規則依然適用。第一個將解決方案推向市場的企業必然擁有巨大優勢。因此,所有解決方案都必須讓設計者可以獲得資源以客製化解決方案、縮短展示機、參考設計或設計服務的開發週期。
建立於FPGA的網路終端機器學習推論
FPGA在網路終端扮演什麼角色?機器學習通常要求兩種類型的運算工作:訓練系統透過既有資料學習新能力。例如,臉部辨識功能通過採集和分析成千上萬張圖片來學習識別人臉。這種早期訓練階段是高度運算密集的。開發人員通常會在資料中心使用高性能硬體來處理這麼龐大的資料量。
機器學習的第二階段:推論,將系統的能力運用在新資料上,如辨認固定模式與執行工作。例如之前討論的臉部辨識功能將在投入現場工作後持續優化其能力,以正確識別人臉。在此階段系統邊運行邊學習,隨著時間推移變得愈加智慧。由於有許多限制要求在邊緣裝置上運算資料,因此開發人員無法運用雲端。相反地,他們必須透過在獲取資料的邊緣裝置上運算,並將系統的智慧延伸到邊緣裝置上。
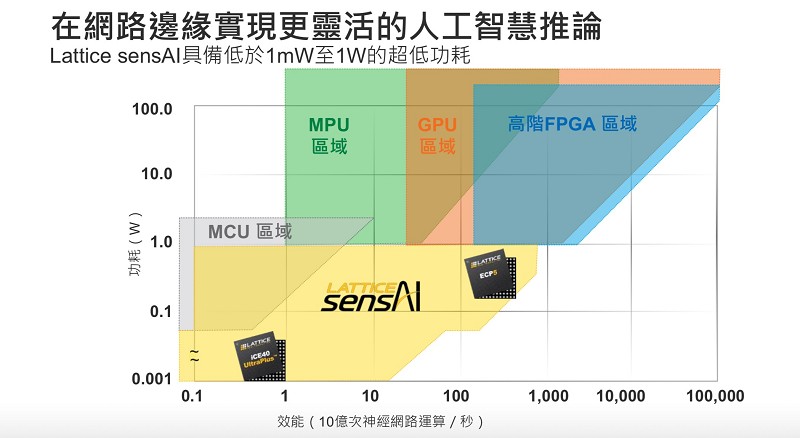
但是設計人員要如何在網路終端進行推論並取代大量的雲端運算效能呢?一種方式就是利用FPGA內建的並行處理能力來提升神經網路的性能。設計人員可以使用經過特別優化的低功耗低密度FPGA滿足網路終端對嚴苛性能和功耗限制的要求。萊迪思的ECP5和iCE40 UltraPlus FPGA就可滿足此需求:設計人員可通過功耗不到1W的ECP5 FPGA和毫瓦級iCE40 UltraPlus FPGA來加速神經網路,構建高效率的AI網路終端應用。(圖3)
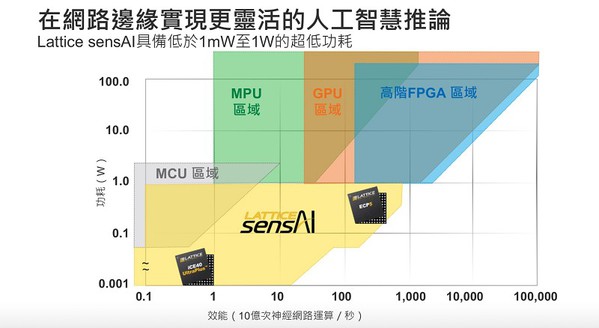
| 圖3 : 基於萊迪思FPGA的低功耗(1mW-1W)機器學習推論 |
|
Lattice sensAI簡介
除了運算硬體外,設計人員還需要各類 IP、工具、參考設計和設計專業知識來構建有效的解決方案並將其快速推向市場。
為協助開發人員應對日益嚴峻的挑戰,萊迪思推出基於iCE40 UltraPlus和ECP5 FPGA系列的完整開發生態系統。Lattice sensAI旨在協助開發人員快速構建適用於智慧家庭、智慧城市、智慧工廠、智慧汽車和行動應用的AI網路終端解決方案,為網路終端提供更靈活的推論。
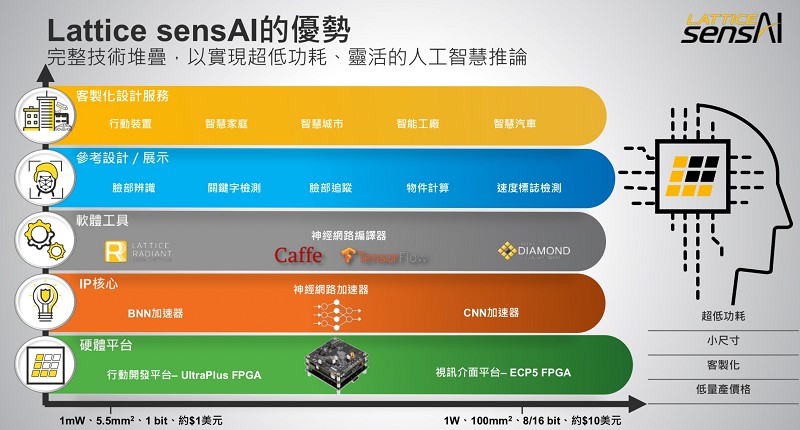
正如圖4所示,Lattice sensAI結合模組化硬體平台、神經網路IP核心、軟體工具、參考設計和來自合作夥伴生態系的客製化設計服務,簡化了靈活推論解決方案的開發,具有低功耗(1mW-1W)、封裝尺寸小(小至5.5mm2)、低量產價格(約1-10美元)等優勢。
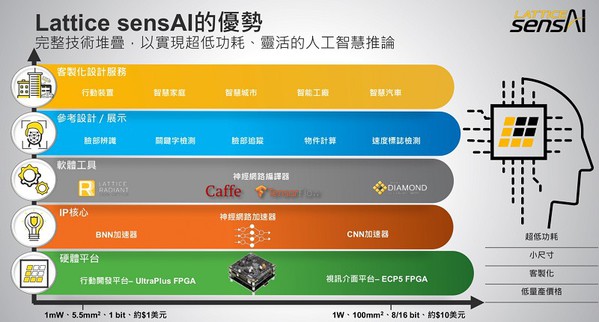
| 圖4 : Lattice sensAI 為開發人員構建網路終端運算解決方案提供了堅實的基礎 |
|
如圖4所示,Lattice sensAI以萊迪思的硬體平台為基礎。為實現這一功能,萊迪思提供全新的模組化硬體平台,加速機器學習的原型設計,滿足廣泛的性能和功耗需求。萊迪思還提供基於低功耗iCE40 UltraPlus FPGA的行動開發平台(MDP),可用於毫瓦級功耗AI設計。行動開發平台包括一系列板載感應器,如圖像感應器、麥克風、羅盤、壓力計和陀螺儀等。針對功耗稍高但總體低於1W的應用,萊迪思則提供基於ECP5 FPGA系列的模組化視訊介面平台(VIP)。模組化視訊介面平台提供多樣化的連接介面,包含MIPI CSI-2、嵌入式DisplayPort (eDP)、HDMI、 GigE Vision和USB 3。嵌入式視覺開發套件(Embedded Vision Development kit)是萊迪思首批硬體平台之一,該模組化平台包含了一塊CrossLink輸入板、一塊ECP5處理器板和一塊HDMI輸出板。隨著新加入的嵌入式DisplayPort (eDP)和USB 3 GigE I/O板,設計人員可輕易更換輸出板以支援其他應用。
除硬體層面外,萊迪思還提供新的神經網路加速器IP核心,便於開發人員在FPGA上演示。此軟IP包括一個針對iCE40 UltraPlus FPGA優化的二進位神經網路(BNN)加速器,可讓開發人員使用iCE40 UltraPlus FPGA透過二進位神經網路演算法實現深度學習應用。萊迪思還提供一個卷積神經網路(CNN)加速器核。該核可靈活設置參數,適用于萊迪思的ECP5 FPGA,它還支援不同量化,讓設計人員可在精確度與功耗間取得平衡。
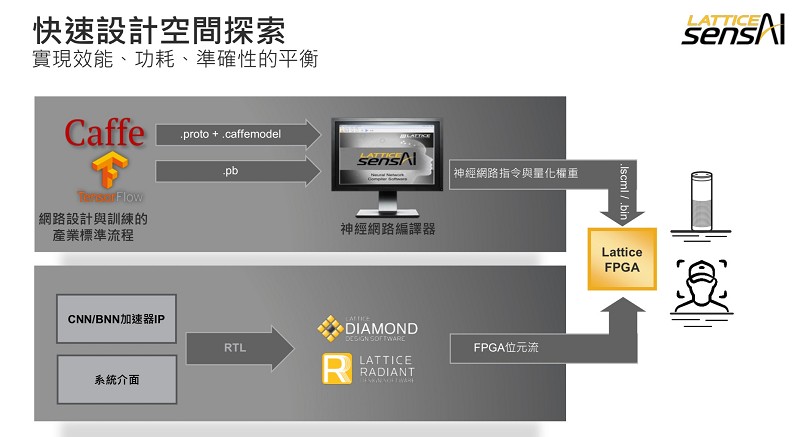
如圖5所示,Lattice sensAI能讓使用者透過簡單易用的工具流程執行快速設計空間探索與平衡。網路訓練可透過產業標準框架如Caffe和TensorFlow完成。接著神經網路編譯器工具能將訓練過的網路模型映射成定點數值,同時支援不同的量化權重和指令。此外,神經網路編譯器能協助分析、模擬和編譯不同類型的網路,進而在沒有RTL設計經驗的情況下,也能在萊迪思的卷積神經網路(CNN)/二進位神經網路(BNN)加速器IP核心上實現。然後使用Radiant和Diamond等傳統的FPGA設計軟體實現整體的FPGA設計,包括剩下的預/後處理模組。
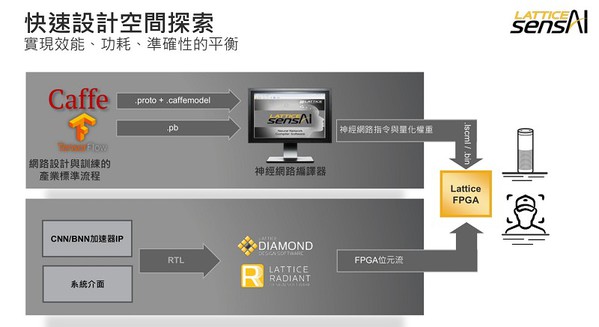
| 圖5 : 通過易用的 Lattice sensAI 工具流程執行快速設計空間探索和平衡 |
|
為簡化常用AI功能的應用流程,Lattice sensAI也結合硬體平台、IP核心與軟體工具,提供許多參考設計與案例。範例包含:
低功耗臉部辨識 —該範例包含適用於網路終端、使用神經網路模型、低功耗快速臉部辨識功能。這個基於iCE40 UltraPlus FPGA的案例使用了二進位權重和指令,能協助設計人員實現低於1mW功耗的人臉識別。
汽車改裝市場攝影機 —該範例針對新興的汽車改裝市場中的攝影機領域。它展示了設計人員如何透過FPGA本身的平行運算辨識速度標誌。在此案例中,在ECP5 FPGA上的卷積神經網路被訓練讀取路上的交通指示牌。訓練完成後,攝影機就可在經過交通標誌時檢測並顯示速度限制。
將聲音指令轉換為系統操作 —此範例向設計人員展示了將聲音指令轉化為系統操作的藍圖。這項功耗不足5mW的關鍵字識別功能,使用了iCE40 UltraPlus FPGA的二進位神經網路。案例描述如何將數位麥克風串連到萊迪思推論引擎,進而達到隨時監聽關鍵字的功能。
用於臉部追蹤的目標辨識解決方案 —該範例深入研究如何將AI物件辨識功能套用於人臉追蹤應用程式。案例中描述了使用萊迪思ECP5-85 FPGA進行卷積神經網路(CNN)加速,其中8個卷積層在8個神經網路引擎中實現。該方案在萊迪思的嵌入式視覺開發套件上獨立運行,啟動後在90 x 90RGB輸入下以14fps運行,而ECP5的總功耗僅0.85W。
客製化設計服務
開發團隊通常需要設計服務合作夥伴的專業能力來協助開發客製化解決方案,在AI市場也不例外。為滿足這種需求,萊迪思與智慧工廠、智慧城市、智慧汽車、智慧家庭和行動應用等眾多領域的設計服務夥伴展開了合作。例如,萊迪思經認證的合作夥伴之一VectorBlox是一家神經網路推論解決方案的開發商。近來,VectorBlox和萊迪思合作在iCE40 UltraPlus FPGA上用不到5000個LUT的神經網路實現了臉部辨識應用。該解決方案使用了開源RISC V軟處理器和定制加速器,大大降低了功耗,同時縮短了回應時間。
為了更快地在萊迪思FPGA中實現推論解決方案,開發人員可能需要求助於具備神經網路設計和訓練知識的設計服務專家。這些知識通常需要與Caffe和TensorFlow框架以及傳統的RTL設計經驗相結合。為了讓這些專業知識更容易被取得,萊迪思推出了Lattice sensAI設計服務方案,推薦設計服務公司以加速設計,在萊迪思FPGA上實現深入學習應用。這些公司提供開發和訓練網路的專業知識,且能針對特定應用開發RTL。
參與該計畫的其他第三方協力廠商已經與萊迪思進行合作,展現其在神經網路開發、訓練和結合硬體使用的強大實力。
結論
網路終端運算革命蓄勢待發,正等待著有人工智慧系統背景的開發人才。當使用者需要更高的智慧,就推升對靠近資料來源、低功耗推論裝置的需求量。Lattice sensAI提供靈活、超低功耗、小尺寸和低量產價格的網路終端優化解決方案。