為了改善電腦系統在資料處理上的效能,科學家將主意打到了人類的神經網路上。這個念頭並不是神來一筆,而是觀察到人類的腦神經在處理視覺、聽覺和語言方面,有非常卓越的表現。
這種參考人類神經元結構所產生的資料處理程序,被稱為「類神經網路」或者「人工神經網路(Artificial Neural Network,ANN)」,它就是一種模仿生物神經網路結構和功能的數學模型的演算法。
ANN技術其實已問世超過50年,且不斷的進行改良和突破,例如卷積類神經網路(Convolutional Neural Networks,CNN)就是相當著名的一支,由於它的結構簡單易用,因此發展迅速,並被廣泛的運用在大型圖像的處理上。
到了近幾年,隨著晶片技術的突破和人工智慧應用的崛起,讓神經網路技術又進一步受到重視。目前主要的推力則是機器學習(Machine Learning),它是人工智慧的基礎所在,而機器學習的核心是基於神經網路的多層資料處理技術的「深度神經網路(Deep Neural Network)」,也因此,想辦法來提升神經網路資料處理的效能,就成了目前各家終端產品設計的突破點。
而眼前,最火熱的戰場,就是智慧型手機。
神經網路 智慧手機的新賣點
神經網路運算有多項優勢,包含平行處理、內容定址記憶、容錯特性、能處理一般演算法難以勝任的問題等,因此很適合運用在經常需要處理非常複雜的任務的應用上,而手機就是一個這樣的產品。
智慧手機是當代人們每天都要隨身的電子裝置,它不僅時時要能連線上網,而且經常會同時開啟多個App軟體,影像和語音的處理更是家常便飯。而隨著人工智慧功能的導入,更讓手機功能的優化與執行變得複雜,此時,神經網路技術就成了最好的解決方案之一。
由於神經網路技術具有自我學習的能力,能學習使用者的操作特性,並設定出一個最佳的輸入和輸出的路徑。因此一旦學習完成之後,後續的各項操作皆能相對以往的軟體程序快上不少,對於使用者體驗有大幅的改善。
目前主要的手機處理晶片供應商也已經在其解決方案中,加入了神經網路處理器的技術。
蘋果Bionic處理器加入神經網路引擎
蘋果的iPhone就是最著名的產品。蘋果在2017年的iPhone A11 Bionic處理器上首度加入了神經網路處理引擎(Neural Engine)的技術。根據蘋果的資料,這個神經網路引擎是一個雙核的設計,每秒運算次數最高可達6000億
次,能大幅提升機器學習的效能。

| 圖一 : 蘋果最新的A12處理器,神經網路引擎的核心數已達8個。(source: Apple) |
|
而實際的使用情形也證實蘋果所言不假,神經網路處理技術的的確確讓機器學習有了脫胎換骨的表現。也因此,蘋果最新一代的處理器A12更進一步增強了神經網路處理單元的性能,更正確的說,是增加了4倍。
在硬體設計上,蘋果的神經網路引擎是透過一塊FPGA區域來達成,因此在機器學習性能上有很強的自定義能力。而在最新使用7奈米製程的A12處理器上,神經網路引擎的核心數已達8個(A11是雙核),且每秒可進行5萬億次運算(約8.33倍),至於執行Core ML的速度則是上一代的9倍,但功耗卻只有前代的十分之一。
也因為如此,採用A12處理器的iPhone學習能力驚人,除了能快速甚至即時的運行各項應用程式外,更能夠迅速的辨認模式並做出預測,且不斷的進行改良,堪稱是當代最聰明的智慧型手機。也由於新的處理器,iPhone在智慧語音和影像辨識的能力有了絕倫的表現。
高通驍龍NPE技術 以DSP突破運算性能
神經網路技術的優勢明顯,各家手機處理器晶片商當然也就陸續投入相關的技術研發,高通(Qualcomm)就是其中一個。旗下的驍龍(Snapdragon)處理器就已經搭載了神經網路處理引擎(Neural Processing Engine; NPE)技術。

| 圖三 : 高通Hexagon DSP神經網路執行性能,相比在CPU上執行,能快出5至8倍。(source: 高通) |
|
根據高通的資料,驍龍的NPE是一種整合了多種軟硬體的元件,用來加速終端裝置上(on-device)的AI功能,以改善使用者的體驗,但原則上,高通的NPE是以軟體為中心(software-centric)的解決方案。
而在軟體架構上,高通的NPE是屬於開放的架構,能支援多種神經網路的框架,包含Tensorflow、Caffe、Caffe2和ONNX,此外,高通也開發了自有的Hexagon Neural Network(NN)函式庫,讓開發者可以讓其AI演算法在驍龍處理器裡的Hexagon DSP上執行。
而在最新一代的驍龍處理器855上,NPE已經發展到了第四代,其效能已較第三代有3倍的成長,可對影像、影音、AR/VR與遊戲等智慧功能進一步優化。只不過高通並沒有具體的說明其NPE的技術細節,硬體的架構也不得而知,也沒有解釋為何是在DSP上運行。但依據高通自己的說法,高通的Hexagon DSP 的神經網路執行性能,相比在CPU上執行,能快出5至8倍。
聯發科曦力處理器加入NeuroPilot與APU技術
台灣的聯發科技(MediaTek)當然也看到了人工智慧在行動裝置上的應用商機,自2018年初起,就推出了NeuroPilot的技術,並將之首次運用在其手機處理平台曦力P60上。
根據聯發科的說法,NeuroPilot是基於他們的核心監控與調節技術CorePilot的進階版。CorePilot在2014年就已經被開發出來,其主要作用就是動態監控手機多核處理器的每個核心的工作負載量,並加調節和分配,以提高手機運行的性能並降低電耗。
到了人工智慧時代,聯發科也順勢推出了APU技術,並運用在CorePilot所積累的異構運算經驗,推出了NeuroPilot平台,作為CPU、GPU和APU間的運作協調,以提升整體的AI運算效能。
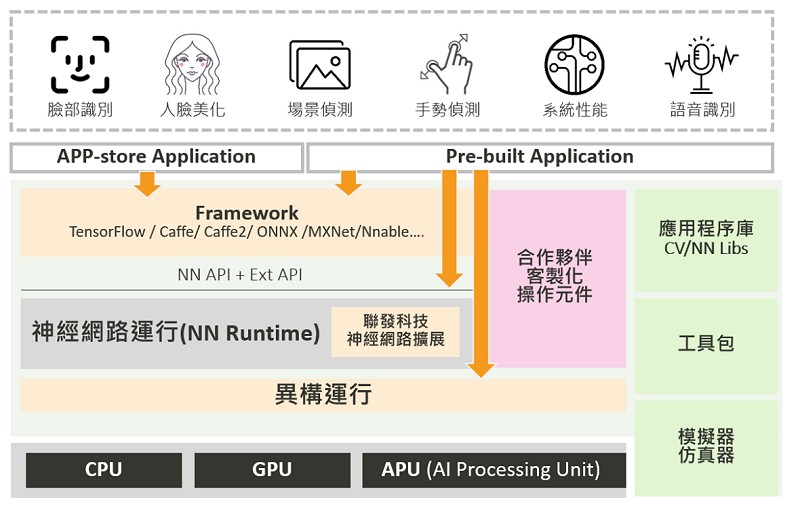
NeuroPilot平台約可分為三個層級,頂層是各種APP應用程式;中間層為程序編寫和異構運算(軟體層);最底層是各種硬體處理器。而其中最關鍵的就是中間的軟體層。
聯發科指出,中間層主要由演算法軟體構成,包括各種軟體的API、神經網絡運行(NN Runtime)、異構運行(Heterogeneous Runtime)。簡單來說,就是所謂的人工智慧的運行架構(AI framewrok),以及神經網路的演算法。
而聯發科的NeuroPilot也是屬於開放式的架構,支援目前市面上主流的AI framework,包含TensorFlow、TF Lite、Caffe、Caffe2、Amazon MXNet、Sony NNabla和ONNX等。聯發科也提供NeuroPilot SDK,其包含Google神經網路API(Android NN API)和聯發科NeuroPilot擴充元件。
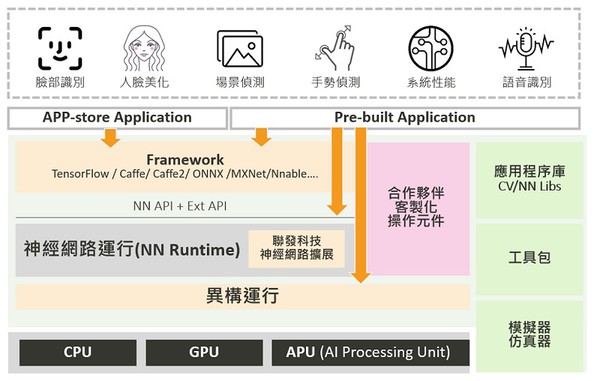
| 圖四 : NeuroPilot平台可分為三個層級,中間層為程序編寫和異構運算,是最關鍵的一層。(source: 聯發科) |
|
而在硬體方面,除了原本的CPU、GPU外,則是增加了新的人工智慧處理器APU,用來提高人工智慧應用和神經網路處理的校能。在最新一款的旗艦處理器P90上,聯發科的APU已升級至2.0版本,比前一代快上四倍,算力達1127GMACs(電腦定點處理能力的量)。
中國海思攜手寒武紀 主攻NPU技術
中國華為旗下的海思半導體(HiSilicon),是手機處理器市場一家快速崛起的IC設計公司,目前屢屢在技術上有領先業界表現。該公司在2017年九月就率先發表了一款採用10奈米製程的智慧手機處理器-麒麟(Kirin)970,該處理器是產界首款具有人工智慧神經處理元件(NPU)的手機處理晶片。
海思的NPU同樣是屬於AI應用程式的加速處理單元,也就是針對神經網路演算法的處理,特別專注於卷積神經網路(CNN)的應用。根據海思的說法,在相簿模式中,Kirin 970的NPU每秒能處理2,000張照片的處理;若沒有NPU介入,單以處理器運算只能處理約100張而已。

| 圖五 : 最新一代的Kirin 980處理器,其NPU核心數已增加至兩個。(source: 海思) |
|
據了解,Kirin 970的NPU,是由中國的晶片IP商寒武紀(Cambri0con)所提供,並由海思與寒武紀共同合作進行優化的一個模組。
而最新一代的Kirin 980處理器,其NPU核心數已增加至兩個。根據華為的資料,雙核NPU的性能可達到每分鐘處理4,500張圖像,較前一代提升了120%的辨識速度。可以快速執行人臉識別,物體偵測與辨識,物體識別,影像分割和智慧辨識等人工智慧的應用。
AI需求成形 處理器IP商也加入戰場
由於神經網路的性能卓越,因此除了IC設計商積極投入研發外,處理器IP供應商自然也開始跨入此一領域,包含前段所提到的中國寒武紀之外,以色列的IP商CEVA也開始提供具備神經網路技術的IP方案。
CEVA近期所發表的WhisPro就是一款基於神經網路技術的智慧語音辨識方案,它採用了可擴展遞迴神經網路(Recurrent Neural Network)技術,可同時辨識多個觸發片語,能運用在智慧手機、智慧音箱、藍牙耳機和其他語音設備中。
然而有趣的是,雖然神經處器技術的勢頭已經竄起,但處理器IP的龍頭Arm卻是動作緩慢,到目前為止,仍未提供任何的神經網路解決方案。雖然Arm也看好人工智慧的應用市場,但就是遲遲未把具體的產品曝光。
而依據Arm的時程,最快今年第一季才會推出具備人工智慧功能的AI處理器-Arm ML CPU。根據Arm的說明,Arm ML處理器也會是一個系列產品,提供多種規格給不同的應用產品,性能範圍是1至4 TOP/s,可滿足不同的產品需求,包含智慧手機、智慧手機、智慧家居和汽車等。
Arm指出,其ML處理器主要有三個部分,一個是MAC引擎,主要是執行卷積雲神經網路的運算;第二是可程式的運算引擎,可以支援未來新的運算元和網路;第三是資料管理,用來降低AI運算的功耗。
雖然推出的時間晚了,但Arm仍是自信滿滿,由於其處理器的生態系十分龐大且完整,要後來居上也可能是易如反掌。
「我們已經看到機器學習技術正在成熟,市場需求也正在不斷增加,我們認為現在是進入市場的最佳時機。」Arm機器學習副總裁Dennis Laudick說。